DEVELOPER’s BLOG
技術ブログ
- トップ
- 技術ブログ

第1弾、第2弾に続き 第1弾:海洋エネルギー × 機械学習 〜普及に向けた課題と解決策〜 再生可能エネルギーの一つである海洋エネルギー発電の長所と課題とその解決策について触れた。 第2弾:海洋エネルギー × 機械学習 〜機械学習を利用した電力需要量予測による波力発電の制御〜 複数ある課題から「発電量と需要とのバランスが取りにくい」、「無駄な待機時間がある」を解決するために、電力需要量を予測を行った。必要な電力需要量が分かれば、その分量を発電できるように

このような課題はありませんか 不良品検査の人員不足で外注しており、コストがかかっている...【コスト削減】 ノウハウが引き継げずにベテラン検査員が退職し、検査に膨大な時間がかかっている...【人依存の解消】 利益率向上・働きやすい環境のために生産性を上げたい...【生産性の向上】 人によって判定にばらつきがあるため、品質にもばらつきが出てしまう...【品質向上】 どれも製造業のお客様からよく聞くお困り事ですし、改善には時間もお金もかかります。しかし、改善し

機械学習では、訓練データとテストデータの違いによって、一部のテストデータに対する精度が上がらないことがあります。 例えば、水辺の鳥と野原の鳥を分類するCUB(Caltech-UCSD Birds-200-2011)データセットに対する画像認識の問題が挙げられます。意図的にではありますが訓練データを、 水辺の鳥が写っている画像は背景が水辺のものが90%、野原のものが10% 野原の鳥が写っている画像は背景が水辺のものが10%、野原のものが90% となるように

はじめに 昨日まで開催されていたKaggleの2019 Data Science Bowlに参加しました。結果から言いますと、public scoreでは銅メダル圏内に位置していたにも関わらず、大きなshake downを起こし3947チーム中1193位でのフィニッシュとなりました。今回メダルを獲得できればCompetition Expertになれたので悔しい結果となりましたが、このshake downの経験を通して学ぶことは多くあったので反省点も踏まえて

こんにちは。 今回は「アイトラッキング」について紹介します! 皆さんは「アイトラッキング」という技術をどのくらいご存知でしょうか? 「アイトラッキング」とは、人間の視線の動きを追跡・分析する手法であり、視線推定技術とも呼ばれます。 この技術により、これまで調査者側からではわからなかった被調査者の無意識の「本音」がわかるようになりました。 この記事ではそんな素晴らしい技術、「アイトラッキング」がどんな場所、場面で使われているのかを調査し、その可能性について

はじめに KaggleのNFLコンペで2038チーム中118位となり、銅メダルをとることができました。以下に、参加してからの取り組みや、反省点を書いていきたいと思います。 コンペ参加前の状況 10ヶ月ほど前にTitanicコンペに参加してから、「Predicting Molecular Properties」と「IEEE-CIS Fraud Detection」というコンペに参加してみましたが、公開されているカーネルを少しいじってみた程度でメダルには到底届

アクセルユニバース株式会社(以下当社)では、人が対応している業務を画像認識、音声認識、文字認識等を活用して効率化する機械学習ソリューション開発をおこなっています。 インターン生は業務の一環としてKaggleに取り組んでおり、先日のASHRAE - Great Energy Predictor IIIにて銅メダルを獲得しました。 メダルを獲得した田村くんのコメントです。 今回は、他の方が提出したもののブレンド(混ぜる)の仕方を工夫しました。 まずはなるべ

業種別 機械学習導入・検討状況 2018年にIBMがおこなった調査によると、企業の82%はAIの導入を検討しており、金融サービス業界では既に16%の企業がAI システムを運用または最適化し、製造業がそれを追いかけるように導入・検討が進んでいます。 例えば、シーメンス、ジェネラルエレクトリック(GE)、ボッシュ、マイクロソフトなどの業界大手企業は、既に製造業のあらゆる部分を後押しするための機械学習アプローチによるAIの製造に多額の投資をおこなっているようで

はじめに 多くの機械学習モデルにおいて注意することの一つとして過学習(overfitting)があります。過学習は学習データに適合しすぎて未知のデータに適合できずに、汎化性能が低下してしまう現象のことを指します。DNNを例に取ると、モデルサイズを大きくしたり、エポック(epoch)及びイテレーション(iteration)を大きくしすぎるとモデルが過学習しすぎてテストエラー(汎化誤差)が大きくなってしまいます。ですが最近になって、一定以上を超えて上記のパラメ

リモートワーク・業務効率化を阻む紙 このようなことはありませんか? お客様アンケートを手集計している。 見積作成のために出社しないといけない。 紙の伝票処理に時間がかかっている。 コロナウイルスの影響もあり、リモートワーク化が進む中、上司のハンコを貰うのでリモートワークできない。という声も少なからずあるようです。紙書類の作業のために出社をしなけばいけない...。リモートワークに限らず、営業が業務日報や見積り作成で会社に戻ることは業務効率を大きく下げる要因で

概要 AI技術の発展が進み、今や私たちの身の回りでも当たり前のようにAIが生活をより便利にしてくれています。この夢のような技術を支えているのは研究者の方たちによる地道な努力です。では、最近はどのような研究が行われているのでしょうか? 研究の成果は論文という形で公開されますが、世界中で活発に研究されているAI関連の論文は1日に数十~百本もの論文が出ています。そのためこれらの論文を読んで最新の研究動向をつかむことは難しいでしょう。 そこで今回はテキストマイニン

今回は「じゃらんの口コミをスクレイピングしてみた」ということで紹介していきます。※この記事はスクレイピング初心者向けに書いています。 目次 1はじめに 2スクレイピング 3可視化 4分析・まとめ 5注意すること 6終わりに はじめに 皆さんは今年の冬をどのように過ごす予定でしょうか? 今回は「冬」「雪」といえば「スキー」「温泉」ということで、この二つのキーワードに関連するホテル・旅館の口コミを分析しました。LINEトラベルのサイトによると、温泉が楽しめ

アクセルユニバース株式会社(以下当社)では、人が対応している業務を画像認識、音声認識、文字認識等を活用して効率化する機械学習ソリューション開発をおこなっています。 インターン生は業務の一環としてkaggleに取り組んでおり、先日のNFL Big Data Bowlコンペにて銅メダルを獲得しました。 こちらのコンペは、アメリカンフットボールのランプレイにおいて、攻撃側が進むヤード数を予測するコンペです。 メダル獲得した小野くんのコメントです。 ーーー 主な勝
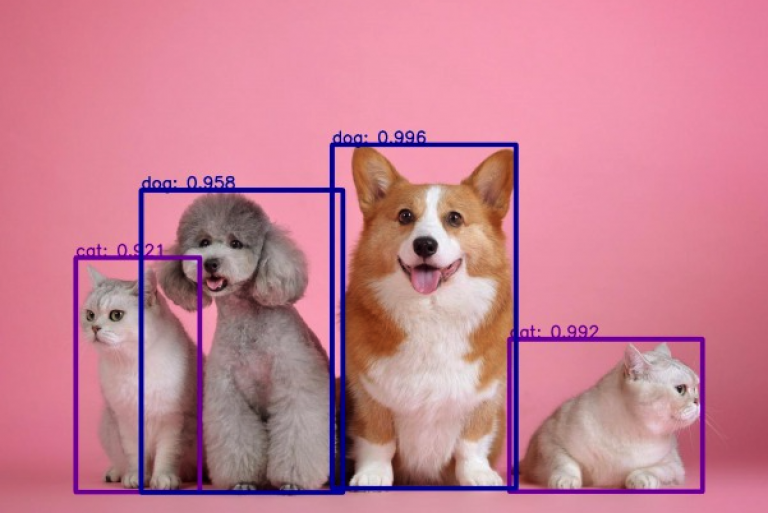
はじめに この記事では物体検出に興味がある初学者向けに、最新技術をデモンストレーションを通して体感的に知ってもらうことを目的としています。今回紹介するのはAAAI19というカンファレンスにて精度と速度を高水準で叩き出した「M2Det」です。one-stage手法の中では最強モデル候補の一つとなっており、以下の図を見ても分かるようにYOLO,SSD,Refine-Net等と比較しても同程度の速度を保ちつつ、精度が上がっていることがわかります。 ※https:

概要 Adversarial ValidationはTrainデータとTestデータの分布が異なる際に、Testデータに似たValidationデータを作成するのに使われる手法です。 Kaggleなどのデータ分析コンペではTrainデータとTestデータの一部が与えられ、コンペ終了まではこの一部のTestデータに対するスコアのみ知ることができます。一部のTestデータだけを見てモデルを評価していると、全体のテストデータに対しては良いスコアが出ずに最終的に低

【ネタバレあり】 皆さん今年のM-1グランプリご覧になりましたか? 今年はミルクボーイさんが見事歴代最高得点で優勝しました。本当におめでとうございます! ミルクボーイさんといえば 「それコーンフレークやないかい!」 「いやほなコーンフレークちゃうやないかい!」 と一方の文章に対してもう一方がコーンフレークかどうかをつっこむ、というネタですよね。 そこでテレビを見ながら思ったわけです。 「これって、機械学習でできるんじゃね?」 与えられた文章に対して、それが

最近、機械学習のビジネスへの活用がさかんになっています。 その中でこういったお困り事はありませんか? トップダウンで「機械学習を導入してほしい」と言われたけど何から始めればいいか分からない 機械学習の導入を検討したけど計画で頓挫した 社内に機械学習の導入を提案したいが、提案がまとまらない 本記事ではそんな方向けに機械学習の検討ステップと導入効果をご紹介します。 機械学習の検討ステップ 1.AI・機械学習で出来ることを知る 2.対象の業務・目的を決める 3.

はじめに まずは下の動画をご覧ください。 スパイダーマン2の主役はトビー・マグワイアですが、この動画ではトム・クルーズがスパイダーマンを演じています。 これは実際にトム・クルーズが演じているのではなく、トム・クルーズの顔画像を用いて合成したもので、機械学習の技術を用いて実現できます。 機械学習は画像に何が写っているか判別したり、株価の予測に使われていましたが、今回ご紹介するGANではdeep learningの技術を用いて「人間を騙す自然なもの」を生成する

"TASK2VEC"は2019年2月にsubmitされた論文の中で提唱された手法であり、「タスクをベクトル化する」手法です。 この手法が提唱されるまでは、"タスク間の関係を表現する"フレームワークが存在しなかったため、一部界隈で脚光を浴びました。 しかし、このTASK2VECの言わんとすることが理解出来ても、どういうものなのか正直ちょっとわかりにくいです。そこで今回は出来るだけ論文の内容をかみ砕いて解説したいと思います。 目次 1.TASK2VEC 概要

最近は今までに増して機械学習を検討する企業が増えています。 しかし、導入検討にあたり、機械学習でなにを改善するのか/なにを解決するのかという、導入目的を決めあぐねているケースも多いと耳にします。 本記事では機械学習はどのような業種で、どんな目的で導入されようとしているのかを紹介し、機械学習の活用例と解決できる課題(導入効果)をお伝えします。 『こんな使い方が自社に役立つな』や『機械学習でこんなことをやりたい』を発見してもらえると嬉しいです。 検討段階のシフ

はじめに 2019年秋の応用情報技術者試験に無事合格することができたので、勉強法などを何番煎じかわかりませんが書いていこうと思います。 私は現在文系学部の2年生で、趣味でプログラムとかを5年ほどやっているのでパソコン系の知識はそこそこありますが、数学や理論といったことははめっきり。 今春に基本情報技術者試験を通ったのでその流れで受けました。 試験の概要 IPA(独立行政法人 情報処理推進機構)によって実施されており、士業の独占などはありませんが、国家資格の

AIの進歩が目覚ましい近年、文章の文脈まで読み取ってくれるAIがあれば嬉しいですよね。 ビジネスの場面でも、クレームとお褒めの言葉を分類したり、議事録のアジェンダと中身が合っているかなど、文脈を判断できればAIの使える場はぐんと広がります。 文脈を機械が読み取るのは難しく、研究者も今まで苦労してきました。 しかし近年、ELMoとBERTという2つのAIが現れたことで、今機械学習は目覚ましい進歩を遂げています。 多くの解説記事は専門家向けに書いてあることが多

今回はデータを分析するという点で共通する経済学やデータサイエンスについて 概要を説明し、経済学において機械学習を使うことの難しさについて説明します。 難しさと言っても、『活用できない』と否定をするわけではありません。 あくまでも活用していくことを前提に、気をつけたい点を紹介します。 目次 経済学とデータサイエンスについて なぜ経済学と機械学習が議論されるのか 経済学で機械学習を利用する際の注意点 まとめ 経済学とデータサイエンスについて そもそも経済学は、

〜普及に向けた課題と解決策〜に続き 私が前回作成した記事である「海洋エネルギー × 機械学習 〜普及に向けた課題と解決策〜」では、海洋エネルギー発電の長所と課題とその解決策について触れた。今回はそこで取り上げた、 課題①「電力需要量とのバランスが取りにくい」、課題③「無駄な待機運転の時間がある」への解決策 ~発電量・電力需要量予測~ ~機械学習を用いた制御~ を実装してみる。 繰り返しにはなるが、この「発電量・電力需要量予測」と「機械学習を用いた制御」
お問い合わせはこちらから