DEVELOPER’s BLOG
技術ブログ
機械学習でひみつ道具『ムードもりあげ楽団』の実現を考えた

アクセルユニバース株式会社(以下 当社)では『機械学習・深層学習で世界を笑顔にする』を掲げ、人が対応している業務を画像認識、音声認識、文字認識等を活用して効率化する機械学習ソリューション開発をおこなっています。
今日は世界を笑顔にしたい私が
「ドラえもんのひみつ道具があれば、みんな笑顔になるのではないか!?」
と機械学習を活用してひみつ道具の実現を考えてみました。
目次
- ひみつ道具の検討
- 実現したいこと
- 結果と今後
ひみつ道具の検討
ずばり、今回実現を検討したいひみつ道具は「ムードもりあげ楽団」です。

出典:ドラえもんのひみつ道具を一つもらえるとしたら
人の気分を盛り上げる楽団ロボット。その時の気分によって楽曲を演奏してくれます。
人は嬉しい時には楽しい音楽、悲しい時には悲しい音楽が聴きたくなるものです。
今回は人の声から感情を判定し、適切な音楽が流れる仕組みを検討します!
実現したいこと
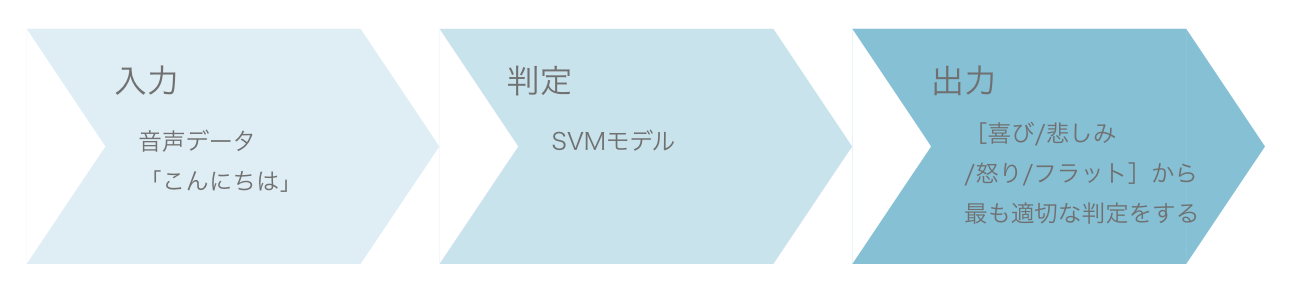
人間の発した音声からその時の感情を判定し、適切な音楽が流れる仕組みです。

実現するために、システムが人の発語を聞き取り感情を分析し、予め決めておいた感情群に判定します。そして判定された感情によって異なる音楽が流れることが必要です。
今回は機械学習の範囲の、感情分析〜判定を考えていきましょう。感情の変化は音声の韻律特徴に表れるので、韻律特徴により4つの感情[喜び/悲しみ/怒り/フラット]に分類します。
いくつか文献を読んでこのように計画しました。文献は最後に紹介します。
データの準備
複数の人から発声データを集め、音の高さ・強さを時系列データにし、適当な長さに分割する。
学習データ : 話者と面識のある人が音声データを聴き、感情を判定(ラベル付け)し、分割する。
モデル
SVM(Support Vector Machine)
未学習データに対する高い汎化性能があり、高い認識性能が認められている。
SVMについて当社ブログ/最初に学ぶ 2分類SVMモデルの基本
評価
交差検証法(クロスバリデーション)
膨大なデータを用意することが難しく、また人の声のため学習にムラがあるかも、と懸念し汎化を高めるために、全てを学習データとして扱う本法を挙げる。
少し計算に時間がかかるかも...。
結果と今後
今回は計画だけで実装はしていませんが、愛知工業大学での結果は精度60%程度で判定できています。
「短時間発話からの音声感情認識のための音声データ選択法に関する検討」
音声データを短く切ることで、特徴として捉える範囲が減り、似たグラフの動きを誤判定してしまうようで若干精度が低下しているようです。
別の研究だと、音声データだけではなく、表情も感情判定に使用し、こちらは精度68%〜70%と結果が出ています。
また、一度判定させたものに結果をフィードバックすることでさらなる精度向上も見込めると思います。
どうやら実現可能性は多いにありそうなので社内でウケが良ければ実装に向けて進めていきます!
ドラえもんひみつ道具シリーズはシリーズ化したいので面白いひみつ道具やお気に入りがあれば是非コメントください。
当社ではインターン生が取り組んでいることを技術ブログで紹介しています。
文系学部2年生の私が「SIGNATE」初参加で上位8%に入った話や論文 Attention Is All You Need から Attentionモデルの解説等が公開されています。
定期的にメルマガでも情報配信予定なので、問い合わせページに「メルマガ登録希望」とご連絡ください。
参考
平井有三:"初めてのパターン認識"森北出版 2012
小野谷信一 長屋優子 : "表情と音声を用いたサポートベクタマシンによる感情認識"2014
短時間発話からの音声感情認識のための音声データ選択法に関する検討
SVMを用いた自発対話音声の感情認識における学習データの検討
関連記事

はじめに ポイント1:設計書を書いてもらいましょう ポイント2:Geminiを使うときの指示の出し方 ポイント3:自分で修正したら「読み直して」と必ず伝える まとめ はじめに 生成AIを使ってコード生成や修正を行うことは、もはや特別なことではなくなってきました。 Gemini や CodeX、Copilot、Cursor など、選択肢も増え、「うまく使えばかなり楽になる」という実感を持っている方も多いと思います。 一方で、実際に使い込

はじめに 復旧キーとは? 「復旧キーがない場合」を試す まとめ はじめに 先日、私用のMacBook Proにログインできなくなる問題が発生しました。 経緯としては、2台あるMacBook Pro AとMacBook Pro Bを取り違えてしまい、MacBook Pro AにMacBook Pro Bのパスワードを入力し続け、パスワード入力の試行可能回数を超過してMacBook Pro Aにロックがかかりました。 Macのログインパスワー

はじめに SSM統合コンソールによる一元管理 OSなど構成情報の可視化 Patch Managerによるパッチ運用の標準化 証明書有効期限の集中監視と自動通知 導入効果と業務改善イメージ 導入時の設計上の留意点 継続的改善を支える「運用の仕組み化」 1.はじめに クラウド活用が拡大し、AWS環境が複数アカウントで利用されたり、複数システムにまたがって利用されることは、システム運用における構成の一貫性を維持することの難易度を

はじめに 可用性設計の基礎:リージョンとAZの仕組みを理解する 止まらない設計を妨げる単一点障害:単一AZ構成の限界 マルチAZ構成:同一リージョン内での止まらない仕組み マルチリージョン構成:事業継続(BCP)のための冗長化 まとめ:設計段階で「どこまで止めないか」を決めよう 1. はじめに AWSは、数クリックで仮想サーバー(EC2)を立ち上げられるなど、手軽にサービスを構築できるクラウドです。システム企画や開発の初期段階では