DEVELOPER’s BLOG
技術ブログ
Kaggle初心者が「地震コンペ」をやってみた

目次
- このブログの対象者
- 地震コンペの概要
- 私が地震コンペを始めた理由
- Kaggle初心者が地震コンペをやるまで
- 地震コンペの情報収集
- 参考にするNotebookの解読
- 特徴量の作成
- モデルの作成
- 結果
- 考察
- 今後
1. このブログの対象者
- Kaggle初心者
- Kaggle入門者用のTitanicや住宅価格コンペの次に挑戦したいが進め方に悩んでいる人
- 地震コンペ(LANL Earthquake Prediction)のような時系列の信号データの分析に興味を持っている人
2. 地震コンペの概要
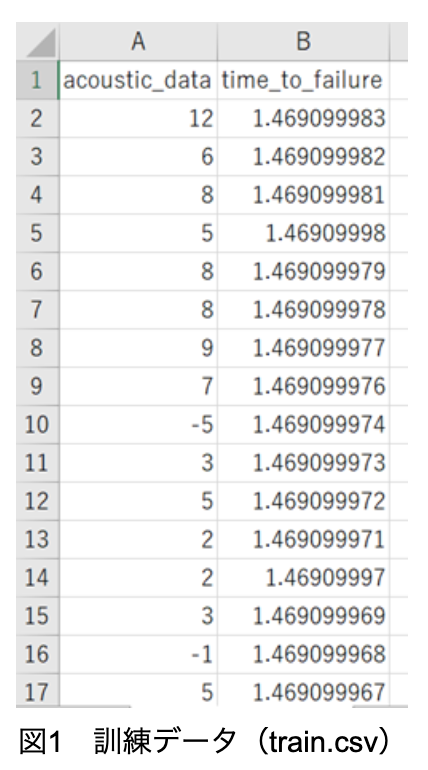
このコンペは、地震の研究でよく使用される実験装置から得られる「音響データ(acousticdata)」のみを使って、実験室で発生する「地震までの時間(timeto_failure)」を予測するコンペである。訓練データは一つのセグメント(一つの実験データの一部分)で、図1のように「音響データ」と「地震までの時間」から成る。
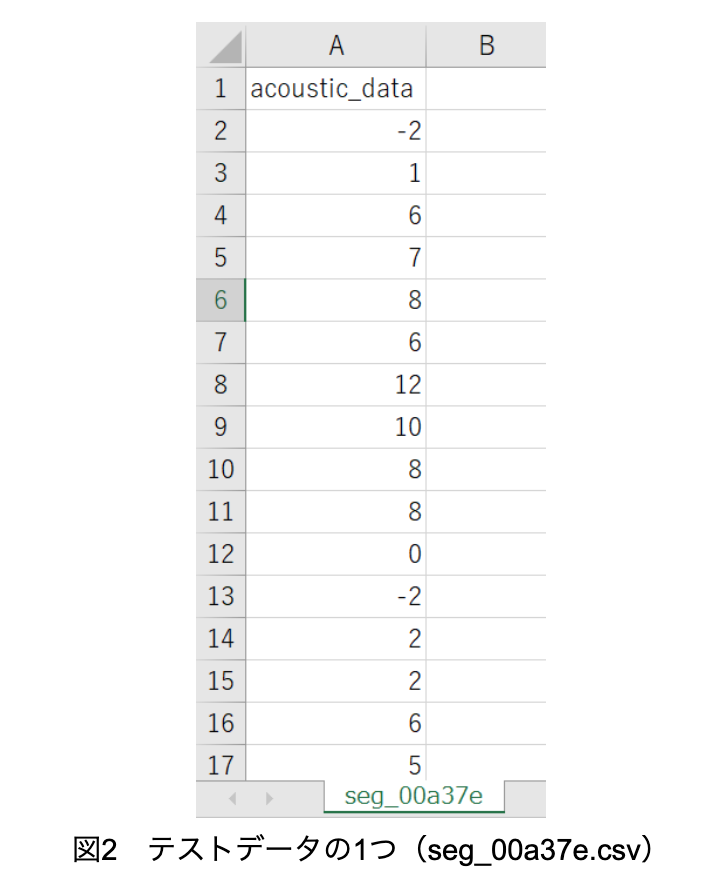
テストデータは2,624個のセグメント(それぞれseg_idが与えられている)で、各セグメント毎に1つのcsvファイルから成るため、2,624 個のcsvファイルから成り、図2のように「音響データ」のみで構成されている。また2,624 個のcsvファイルは1つのフォルダに入っている。
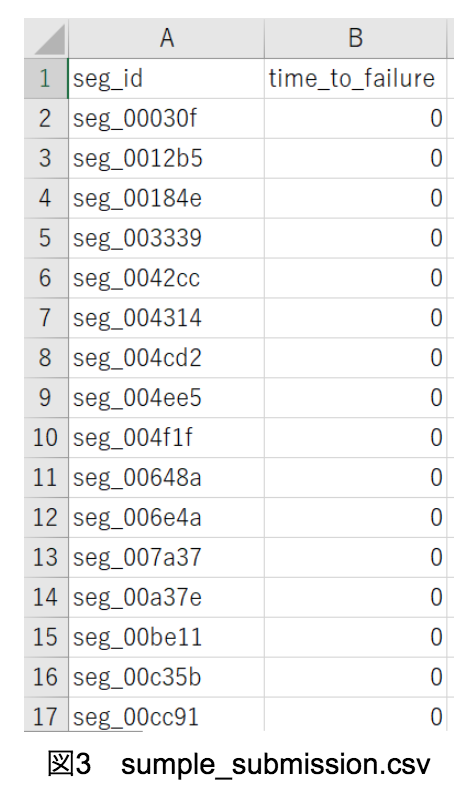
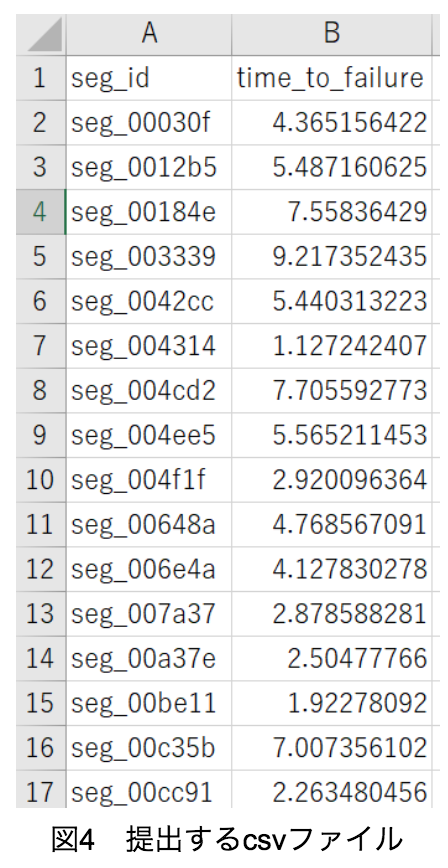
この2,624個の各セグメント(各segid)に対して、図3から4のように「地震までの時間」を予測し提出することが目的である。ここで注意すべきなのはsumplesubmission.csvのsegidの順番と2,624個のテストデータが入っているフォルダのsegidの順番が異なっていることである。しかし順番は異なっているが、共に2,624個のseg_idが正しくあるので心配する必要はない。
3. 私が地震コンペを始めた理由
わたしは以前から「海洋波の波高予測」といった時系列の信号データの分析を行っている。その分析方法はその信号データのみを特徴量として分析する方法である。この方法をここでは「直接法」と呼ぶことにする。私は時系列の信号データの分析方法としてこの「直接法」以外を知らないため、今回地震コンペにチャレンジすることで、新しい手法を知ることができ、今後の分析に活かせるのではないかと思ったからである。
また地震コンペで扱う「音響データ」は時系列の信号データであるが、世の中の多くのデータは時系列であり、時系列データの分析をできるようになると、ありとあらゆる現象の分析が行えるようになる。なのでその練習の一環として、地震コンペを行うことにした。
4. Kaggle初心者が地震コンペをやるまで
▼必要なスキル
- Pythonの基本構文が書ける能力
- 機械学習の学習モデルの種類を知っており、実装できる能力
▼地震コンペをやる前にやった方が良いKaggle
Kaggleの基礎や提出方法などを分かっておくために、深堀りはせずとも以下をやっておいた方が良い。
- Titanic
私はネットで「Kaggle Titanic 入門」などと検索し、コードを理解して参考にした。
スコアが0.8を超えると、Kaggleの力がある程度付いたとよく評価されている。
- 住宅価格コンペ
私はネットで「Kaggle 住宅価格 前処理」などと検索し、コードを理解して参考にした。
5. 地震コンペの情報収集
- まずは何かを参考に
本来ならば、自力で提出できるのがベストであるが、私は地震コンペをやると言っても何から始めていいのか、特徴量をどうするか悩んだので、まずは既存のものを参考にすることにした。
- ネット検索は使えない
地震コンペはTitanicや住宅価格とは異なりマイナーなコンペなので、ネット検索では地震コンペについてしっかりと解説していたり、コードが書いてあるサイトがない。地震コンペに限ったことではないが、Titanicや住宅価格以外のコンペはネット検索をしても良い解説サイトは多分ないだろう。
- Notebooksを参考に
そこで参考にすべきなのがKaggleのNotebooksだが、当然英語で、読み進めていくには時間がかかる。また問題は英語で書かれていることだけではない。Notebooksは人によっては全く文字を書いて解説せず、ただコードを貼っている人もいる。人が書いたコードは、自分の書き方とは当然異なるので、本当に読めない。
- 良いNotebookを見つけるには
では、読みやすいNotebooksはどうやって探せばよいのか。まずはNotebooksの右上にあるSort byの所を、Most Votesにすると良い。良いNotebooksと投票されたものが上から順に並んで表示される。しかし、必ずしも一番上に表示されたNotebookが良いとも限らない。なので上から順にNotebookを見ていく。上から順に見て行き、英語ではあるができるだけ解説文が多いNotebookを探すとよい。コードだけのNotebookは上級者にしか読めないだろう。また、パッと見でコードの構文の形がなんとなく分かるものを選ぶとよい。この段階ですぐにコードの内容がすぐに理解できる必要はない。ただ構文の形がなんとなく分かるだけで、自分の書くコードと似ている可能性が高いのでよい。
6. 参考にするNotebookの解読
- 参考にするNotebookの決定
こちらのNotebookを最初に選んだ。後半部分は解説文はないし、コードもよく分からない。だが、前半部分は解説文があり、コードもなんとなく構文の形が分かるので、これを選んだ。
- 全部コピペして提出
そしてまず上記URLのコードをコピペして提出してみた。これは念の為、エラーが出ずに正常に実装でき、採点されるかを確認するために行った。 コピペしてもエラーが出て実装できないNotebookもあるのでこの作業はしたほうが良い。今回は正常に実装でき採点されたので特に問題はなかった。
- 解説文の解読
ここからが私の勉強である。Notebookの解説文をgoogle翻訳を使いながら読んだ。
- コードの解読
その後Notebookのコードを上から解読していった。この作業が最も気合がいる作業であるが、読みにくくないNotebookを選んだため、なんとか読むことができた。ただ全ては理解できていない。特に後半の学習モデルの作成部分はよく分からない。そこでこれは私の工夫だが、特徴量を作り上げ、訓練データとテストデータの作成する部分だけNotebookを参考にすれば、後はなんらかの学習モデルを使用して学習すればよいのであって、学習モデルまで参考にする必要はないので、後半部分を解読することはしていない。つまり私は前半の特徴量を作り上げ、訓練データとテストデータの作成する部分だけNotebookを解読した。
7. 特徴量の作成
まず、モジュールや関数を読み込み、次にtrain.csv(図5ではearthquake_train.csvと改名している)を読み込む。

次に訓練データの特徴量を図6のように作成する。「音響データ」の特徴を保持して加工する必要があるため、当然、平均や標準偏差といった統計量を用いるのだが、時系列データであるので、「音響データ」150,000個毎の各セグメントの統計量を特徴量としていく。例えば、「音響データ」の0から149,999個目の統計量を一行目、150,000から299,999個目の統計量を二行目としていく。そしてその統計量を24種類扱う。このように信号データの特徴を保持して新しい特徴量を作る方法をここでは「間接法」と呼ぶことにする。


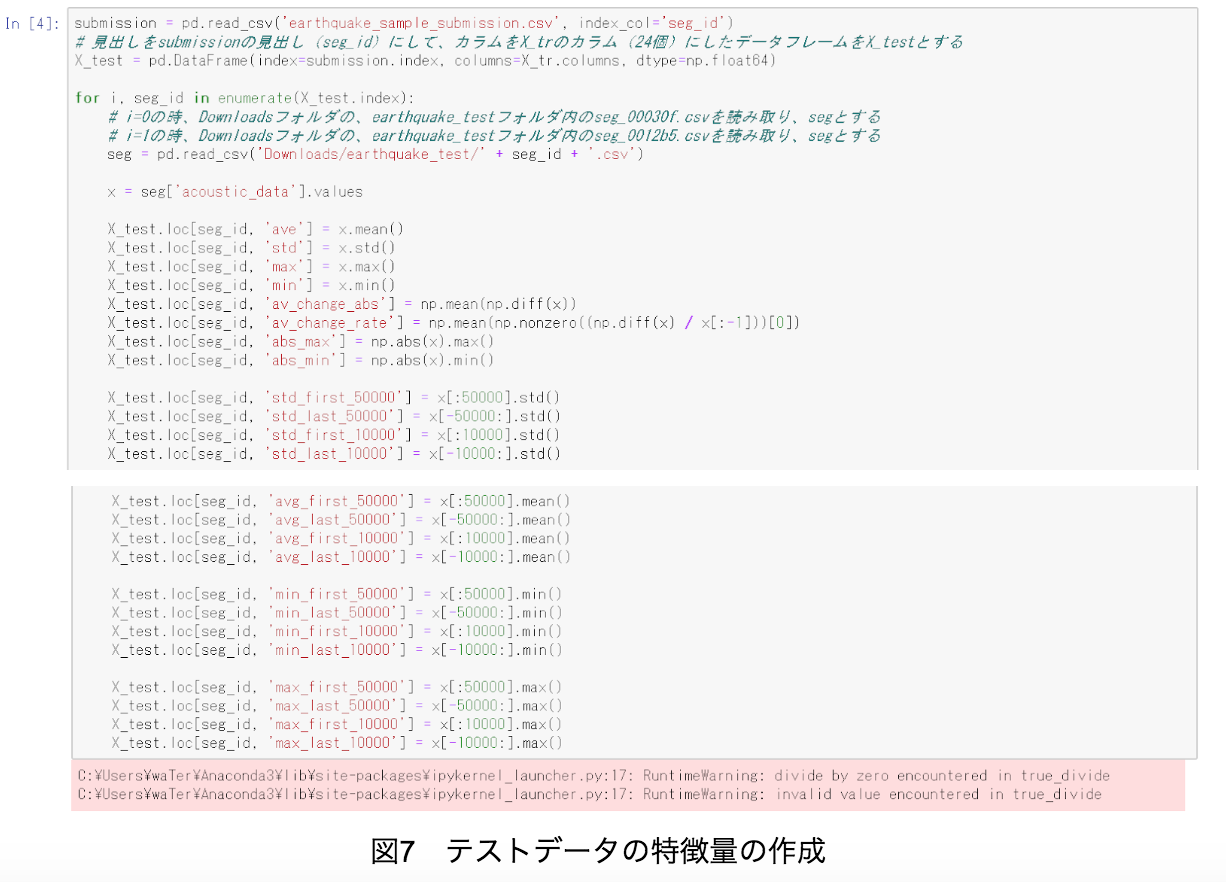
訓練データの特徴量の作成と同様に、テストデータも図7のように特徴量を作成する。但し、samplesubmission.csvとtest.csvはearthquakesamplesubmission.csv、earthquaketest.csvに改名している。
8. モデルの作成
まず図8のように、訓練データとテストデータの正規化を行う。ここで理由は分からないが、In [6]において、 scaler.fit(X_test) というコードを加えてしまうと精度が落ちることが分かったので、図8では加えていない。

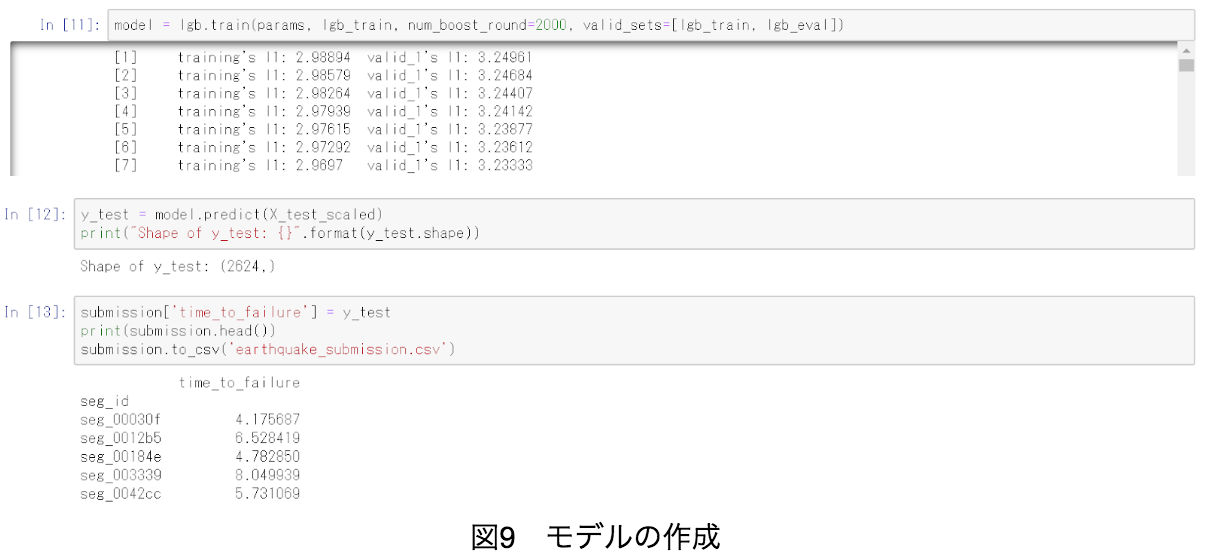
その後、学習モデルはNotebookを参考にせず、図9のようにLightGBMを採用した。但し、LightGBMのパラメータだけはNotebookでLigghtGBMを行っているであろう箇所の値と同じにした。
9. 結果
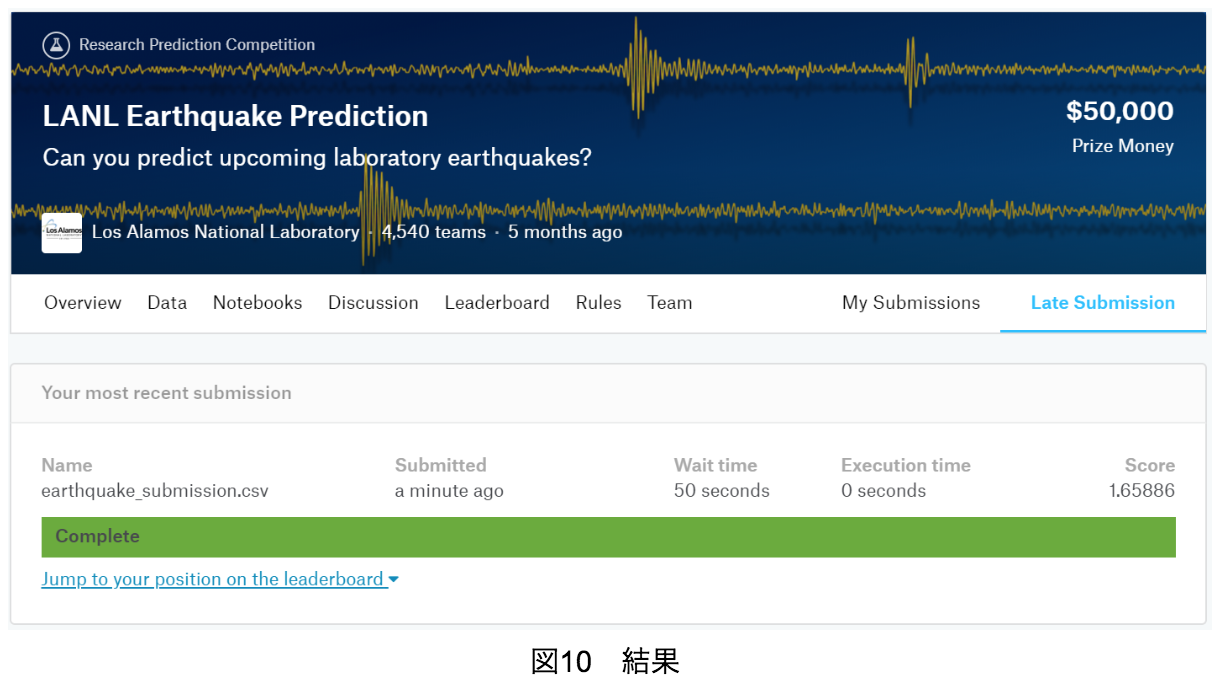
上記のコードを実装することで、図10のようにスコアが1.65885となった。
10. 考察
今回は上記のURLのNotebookを参考に地震コンペを行ってきたが、このNotebookには同じ人が作成した第二弾 があり、ここでは今回作成した特徴量に加え、更に多くの特徴量を追加して、精度を上げている。つまり、特徴量を増やし、「音響データ」の特徴をより正確に統計量として抽出することによって精度が上がるのではないかと私は考えている。
11. 今後
この地震コンペは、使用できるデータとして、一つの時系列の信号データしか与えられていない。このような場合、その信号データを唯一の特徴量と見なす「直接法」(LSTMなどの時系列データに特化したモデルを使用するなど)は当然あるが、実際にやってみるとデータ数が非常に多いため処理しきれなかった。つまり「音響データ」をそのまま使うというのはなかなか厳しい事が分かる。そこで、今回参考にしたNotebookのように、その信号の特徴を抽出して統計量にし、それを特徴量にするという「間接法」が有効であった。
今後も私は時系列データの分析を主に行って行くが、このような状況に出会った場合、「直接法」だけでなく、「間接法」というアプローチもあるということを念頭に入れて分析にあたりたいと思う。また逆に、今のところLSTMによる「直接法」で地震コンペの処理はデータ量が多すぎるためできていないが、なんとかできる方法がないのか今後も探ってみたいと思う。
当社では定期的にメルマガでも情報配信をしています。
ご希望の方は問い合わせページに「メルマガ登録希望」とご連絡ください。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

NCAAコンペ概要 全米大学体育協会バスケットボールトーナメントの試合の勝敗を予測するコンペでした。男女別にコンペが開かれました。リーグ戦の試合結果の詳細とトーナメントの試合結果のデータが年ごとに与えられ、今年のトーナメントの試合結果を予測します。評価指標はLoglossでした。 結果 新型コロナウイルスの影響で、大会自体がキャンセルになってしまいました。リークなしのLBの最も良いスコアは0.52586です。 取り組み内容 コンペの内容を理解してから

はじめに 昨日まで開催されていたKaggleの2019 Data Science Bowlに参加しました。結果から言いますと、public scoreでは銅メダル圏内に位置していたにも関わらず、大きなshake downを起こし3947チーム中1193位でのフィニッシュとなりました。今回メダルを獲得できればCompetition Expertになれたので悔しい結果となりましたが、このshake downの経験を通して学ぶことは多くあったので反省点も踏まえて

はじめに KaggleのNFLコンペで2038チーム中118位となり、銅メダルをとることができました。以下に、参加してからの取り組みや、反省点を書いていきたいと思います。 コンペ参加前の状況 10ヶ月ほど前にTitanicコンペに参加してから、「Predicting Molecular Properties」と「IEEE-CIS Fraud Detection」というコンペに参加してみましたが、公開されているカーネルを少しいじってみた程度でメダルには到底届

アクセルユニバース株式会社(以下当社)では、人が対応している業務を画像認識、音声認識、文字認識等を活用して効率化する機械学習ソリューション開発をおこなっています。 インターン生は業務の一環としてKaggleに取り組んでおり、先日のASHRAE - Great Energy Predictor IIIにて銅メダルを獲得しました。 メダルを獲得した田村くんのコメントです。 今回は、他の方が提出したもののブレンド(混ぜる)の仕方を工夫しました。 まずはなるべ