DEVELOPER’s BLOG
技術ブログ
文系学部2年生の私がコンペ初参加で「SIGNATE」上位8%に入った話(解法)

この記事では、3ヶ月前までデータサイエンスと無縁だった私が、
マイナビの家賃予測コンペで上位8%(スコア14953)に達した解法について紹介したいと思います。
始めまして、 アクセルユニバース株式会社、インターンの土井です。


ここで紹介するSIGNATEの解法は、私が始めて間もないこともあり、シンプルな解法ばかりです。
幅広いレベルの方の参考になれると思います。
コンペの概要
 https://signate.jp/competitions/182
https://signate.jp/competitions/182
東京23区における賃貸物件の家賃予測が目的です。
少ないカラムに多くの情報が詰められており、このままでは有効にモデルを適用することができません。
丁寧に各カラムの前処理を行い、いかに有効な特徴量を作り出すかがこのコンペの肝です。
目的
私がこのコンペに参加した理由は以下の通りです。
- SIGNATE(Kaggle)の流れを理解したい
- 短期間で実績を残したい
- 上位者発表会でスカウトされたい
以下がその結果です。
- pythonの基礎文法が書けるようになった
- SIGNATE(Kaggle)の全体の流れを把握した
- データサイエンス、プログラミングが楽しくなった
残念ながら発表会に参加できる順位に達しませんでしたが、短期間で成長できる素晴らしい経験でした。
ここからは、上位8%に達するための具体的な解法を時系列に沿って10月1日から解説していきます。

前処理
実はこの期間、スコアが全く上がりませんでした。


下位20%くらいだったような。 スコアが上がらない原因がわからず、3週間ひたすら前処理を行います。
この期間の終盤の頃は、前処理をもう一度やり直してみたり、綺麗に書き直してみたりと、 スコアに関係のないことばかりをしていました。(おかげでコーディング力は爆上がり)
使っていたモデルはRandom Forestで、モデルに関する知識が無かったためパラメータは全てデフォルトです。
モデル作成
スコアが上がらず悩んでいたときに、運命の出会いがありました。
Lightgbm
テーブルデータコンペではLightgbmが強いという情報があったので、
モデルをLightgbmに変え、パラメータもkaggleのnotebookを参考に調整しました。
そしてモデルを回してみると、


・・・・・・・????
前処理をひたすらしていた3週間を嘲笑うかのようにスコアが上がりました。
この時点ではほとんど特徴量エンジニアリングはしていません。
Lightgbmの破壊力、恐るべしです。
特徴量エンジニアリング part1
ようやく前処理が終わったので、本格的な特徴量エンジニアリングのステップに入ります。
主に以下のような特徴量エンジニアリングを行いました。
- 数値変数×カテゴリ変数
- 数値変数×数値変数
- TargetEncoding
数値変数×カテゴリ変数
数値変数同士を組み合わせた特徴量生成は思いつきやすいのですが、カテゴリ変数と組み合わせた特徴量も実は強力です。
例として、各カテゴリごとに対する数値変数の平均や標準偏差を計算し、特徴量にします。
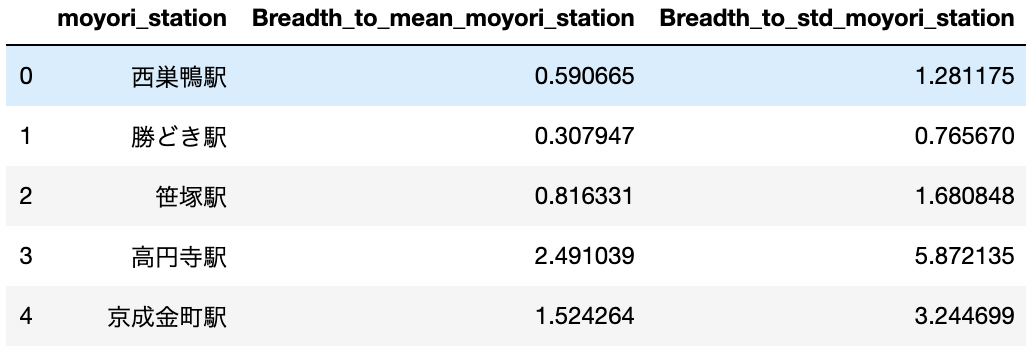
0行目の「Breadthtomeanmoyoristation」が「0.590665」というのは、
西巣鴨駅の近くにあるこの賃貸は、西巣鴨駅の賃貸の平均の面積の0.59倍であることを示しています。
このように、周辺の賃貸と比較した面積の大小を表しています。
他にも色々な組み合わせが考えられます。
- 部屋の面積×住所
- 部屋の面積×部屋の間取り
- 部屋の階数×最寄り駅
数値変数×数値変数
これは、2つの数値変数を乗除することで新たな変数を生み出します。
その例として、以下のカラムをつくりました。
- 部屋の広さと部屋の間取りで一部屋あたりの面積を求める
- 賃貸の面積 * 階数を計算する
TargetEncoding
TargetEncodingは、目的変数を利用して特徴量エンジニアリングを行います。
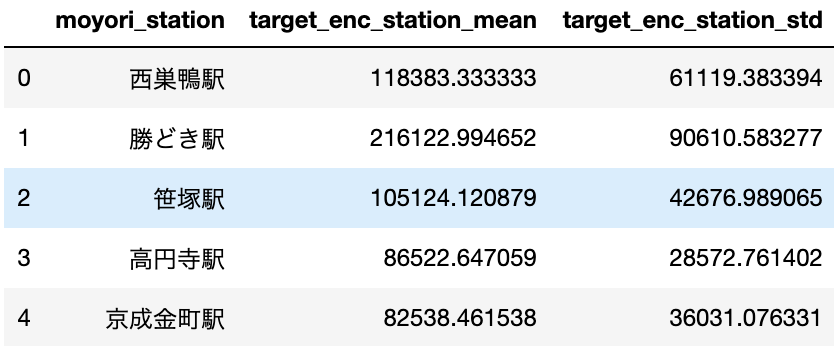
例えば、各駅に対する賃料の平均を計算した値を特徴量にします。
ただし、この方法は正しい処理(Leave One Outなど、ここでは割愛)を行わないと精度が落ちてしまう可能性があります。
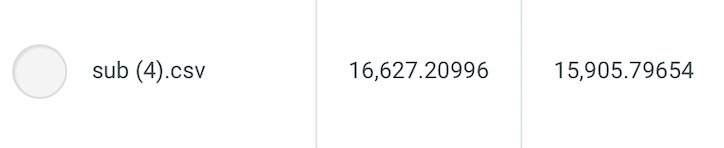
以上の特徴量エンジニアリングを行うと、以下のスコアが出ました。
モデルはLightgbmのままです。

特徴量エンジニアリング part2
SIGNATEのフォーラムを見ると、「地価データを利用した」という情報を公開されていたので、早速取り入れてみました。
地価データも価格への影響が強く、スコアに貢献してくれました。


これが私の最終提出スコアです。
解法まとめ
モデル
Lightgbm
特徴量エンジニアリング
- 数値変数×カテゴリ変数
- 数値変数×数値変数
- targetencoding
最後に
家賃予測コンペでは、他のコンペでもよく使用される基本的な手法を行うことで、上位8%まで上がりました。
私のようなKaggle初心者は、Kaggleで紹介されている高度な解法を理解し活用することが難しいので、
データの特徴を深く理解し、基本的な解法を最大限に活用することが効果的です。
これからも、データサイエンティストとしてKaggleコンペにたくさん参加し、Kaggleの解法についてアウトプットしていきたいと思います。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

ご挨拶 AWS全冠エンジニアの小澤です。 今年の目標はテニスで初中級の草トーナメントに優勝することです。よろしくお願いいたします。 本記事の目的 本記事では、生成AIでVOC分析を行うことで得られた知見を共有したいと思います。 昨今、生成AIの登場など機械学習の進歩は目覚ましいものがあります。一方、足元では自社データの利活用が進まず、世の中のトレンドと乖離していくことに課題感を持たれている方も多いかと思います。また、ガートナーの調査(2024年1月)による

なぜ機械学習で双対問題を学ぶのか 結果から述べるのであれば、SVM(サポートベクトルマシーン)の原理で双対問題を使いたいからです。 これから実際どのように双対問題が使われているのか、また、双対問題の簡単な具体例を交えて説明していきたいと思います。 まずSVMについて簡単に説明したいと思います。 予測には過去のデータを使います。 しかし、外れ値のような余計なデータまで使ってしまうと、予測精度が下がるかもしれません。 そこで「本当に予測に必要となる一部のデータ

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)