アマゾンジャパン品川オフィス3階
森のようなアトリウム
1.はじめに
営業担当から突然、「この商品の半年分の売上推移のデータください」と言われ、思いがけないタイミングでデータ集計に時間を取られてしまう--。そんな依頼を様々な部署から受け、毎日追われている、というご経験がある方もいらっしゃるのではないでしょうか?
こうした課題を解決する手段として注目されているのがText2SQLです。
今回、アクセルユニバースは アマゾン ウェブ サービス ジャパン合同会社様(以下、AWS Japan)と共催し、 Text2SQLワークショップを開催しました。本記事では、その内容と当日の様子をご紹介します。
2.Text2SQLとは
Text2SQLとは、自然言語(プレーンテキスト)の質問を、Amazon RDS や Amazon Redshift などのデータベースで実行可能なSQLクエリに自動変換する技術です。
例えば、「先月の売上トップ10の商品を教えて」と入力すると、AIがSQLを生成し、データベースから結果を取得します。
このように、AIがユーザーの指示を理解し、事前に設定された目標を達成するために、自律的に計画・実行をする仕組みは「AIエージェント」と呼ばれており、DX領域で注目されています。今回のワークショップでは、Claude(Anthropic社が提供する生成AIモデル※)、 Kiro を利用し、Text2SQLの構築とカスタマイズを体験していただきました。
Kiro は、AIを活用したアプリケーション開発を支援する開発環境であり、AIとの対話を通じて要件整理や処理設計、実装を進めることができます。これにより、従来は専門知識が必要だったデータ分析基盤の構築も、よりスピーディに試行・改善できるようになります。これにより、SQLを書けない人でもチャット形式でデータ分析が可能になります。
※ClaudeはAnthropic PBCの商標または登録商標です
3.ワークショップの内容
今回のワークショップは、参加企業の自社データを用いてText2SQLの構築とデータ分析を体験していただく内容で、2部構成で実施しました。
成果物としては、セミナーに参加された皆様に、翌日からどのようなエージェントでどのように業務を変え、それによりどんな強み / 価値が強化されるのかというストーリーがまとまる状態を目指して実施しました。
3-1.第1部:座学パート
まずはAIエージェント時代のビジネスについて理解するため 座学セッションを行いました。
3-1-1.AI BPR(ビジネスプロセス・リエンジニアリング)について

アマゾンウェブサービスジャパン合同会社
Senior Machine Learning Developer Relations
久保 隆宏様
AWS Japanの久保様より、AIエージェント時代のビジネスについてご講演いただきました。今回のワークショップでは、Text2SQLの構築だけでなく、AI BPR(AI-driven Business Process ReEngineering:AIを前提とした業務プロセスの見直し)が重要なテーマです。
生成 AI の技術は仕事を任せられる方向へ進化していますが、組織の差別化要因はこれからも人間です。AI BPR が目指すのは、人間の作業を置き換えることではなく、人間の強みをデータ x AI エージェントで強化 することです。
AI BPR は以下の3つの特徴で、従来の "BPR" や生成 AI 適用が抱えている課題を解決します。
- 「問題」から始めるのではなく、業務を通じた強みや顧客へのアウトカムの特定から始めること
- 技術的に可能か否かの議論に時間を費やすのではなく、担当者がどのように強み・価値に注力するかという適応を議論すること
- ヒアリングや要件調整に時間をかけるのではなく、ステークホルダーが同じ時間・場所に集まり、生成AIを用いてリアルタイムに成果物を作成すること
今回のワークショップでは、単にText2SQLの構築を体験するだけでなく、こうしたAI BPRの考え方を実際の手順の中で体験していただきました。
3-1-2.Text2SQLのデモ

アクセルユニバース株式会社 システム部
齋藤 敬明
弊社エンジニアの齋藤より、 Text2SQLについてご説明しました。自然言語で質問すると、AIがSQLを生成し、データベースから結果を取得する様子をご覧いただきました。
特にデモのときには、参加者の皆様に興味をもってみていただき、参加者の皆様は「自社データで試してみる」ことへの期待が大きくなっているようにみえました。
3-2.第2部:Text2SQLの構築ハンズオン
後半は、実際にText2SQLを構築するハンズオンを実施しました。

アマゾンジャパン品川オフィス
ハンズオン会場
今回はこんな素敵な空間にある5つのお部屋で、参加企業ごとに部屋を分け、 それぞれのデータを使って構築を進めました。
3-2-1.ハンズオンの手順
- Kiro IDEの環境構築
- ノンカスタマイズのText2SQLをデプロイ
- Kiro IDE を使った自社業務プロセスの分析
- Kiro IDE が生成した文書を使って Kiro で Text2SQL のカスタマイズ
- チャット形式でデータ分析
- 分析結果のまとめ(最終レポート作成)
3-2-2.参加企業の例
参加者
情報システム部の方と、分析実務担当の方
課題
営業担当から突然「例)この商品の半年分の売上推移のデータください」と依頼があり、想定外のタイミングでデータ集計作業が発生する
当日使用したデータ
市場データ(2か月分)
3-2-3.体験中の様子
最初はAIの集計結果に半信半疑の様子でしたが、手元の手動集計データと比較した結果、正確な集計であることが確認できました。
その後は積極的にAIへ質問を行い、「商品種別ごとの傾向」や「注目ポイント」などをチャットで会話しながら確認され、その回答に今後の活用への期待感を抱いていただけたようでした。参加者からは「営業担当と一緒に使えば、さらに価値が出そう」という感想もいただきました。

ハンズオンの一場面
環境構築の様子
4.参加者の声
環境構築を終え、Kiroが生成した最終レポートを確認した際には、自然と拍手が起こる場面もありました。
アンケートでは以下の声をいただきました。(一部抜粋)
- AIと対話しながら業務プロセスを分解し、改善のイメージを持つことができた。
- やりとりの質が高く、言語化できていない要素を整理・言語化するのに最適だと感じた。
- ハンズオンでアプリを作れたことで理解が深まった。
- グラフなど、視覚的な分析ができる点が良いと感じた。
- AIが自動でクエリを再生成する仕組みに驚いた。
「業務プロセスの分解や言語化に役立つ」「AIとの対話を通じて活用イメージが具体化した」といった感想もあり、AI BPRの考え方が実体験を通して伝わっていたことがうかがえました。
一方で、データ準備や環境構築に関する課題も一部挙がっており、実運用に向けて検討すべきポイントも明らかになりました。 こうしたフィードバックは、今後のワークショップ内容の改善や実践支援を行う上での貴重な示唆となりました。
5.PoCから本格導入まで
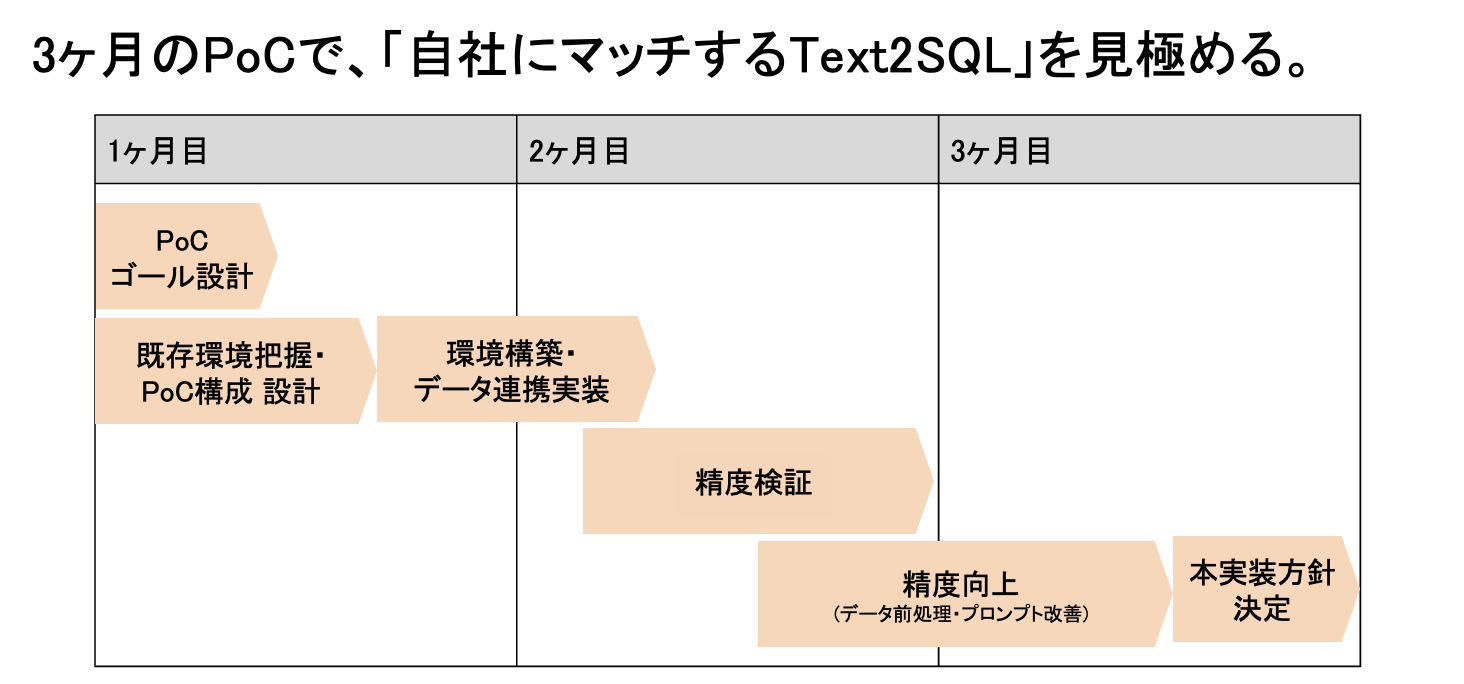
アクセルユニバースでは、今回のデモ環境をベースにPoCから本格導入までの支援を行っています。
一例ですが、約3か月のPoCを通して、
- 自社データでの検証
- 活用シナリオの検討
- 定着化
を進めることが可能です。
AIの活用が重要になることは感じていても、
- どこから始めればよいのか分からない
- 何を作ればいいのか分からない
という方も多いと思います。
そうした段階でも、課題整理から一緒に検討させていただきます。ぜひお気軽にご相談ください。
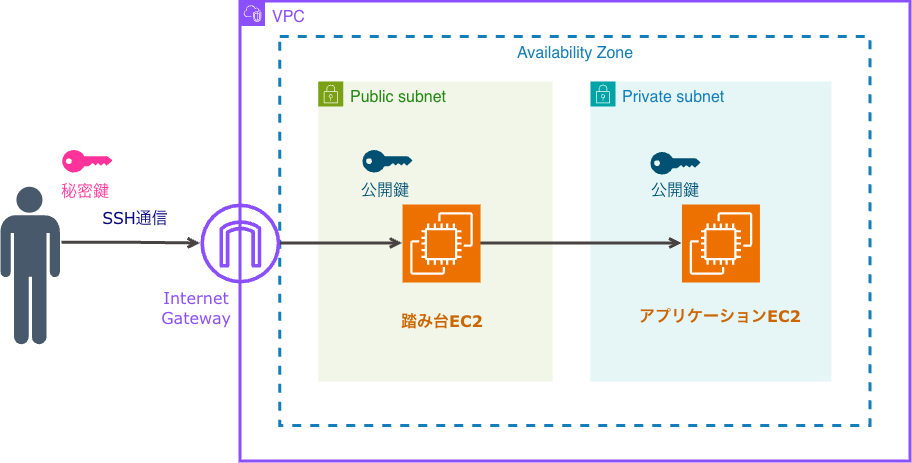
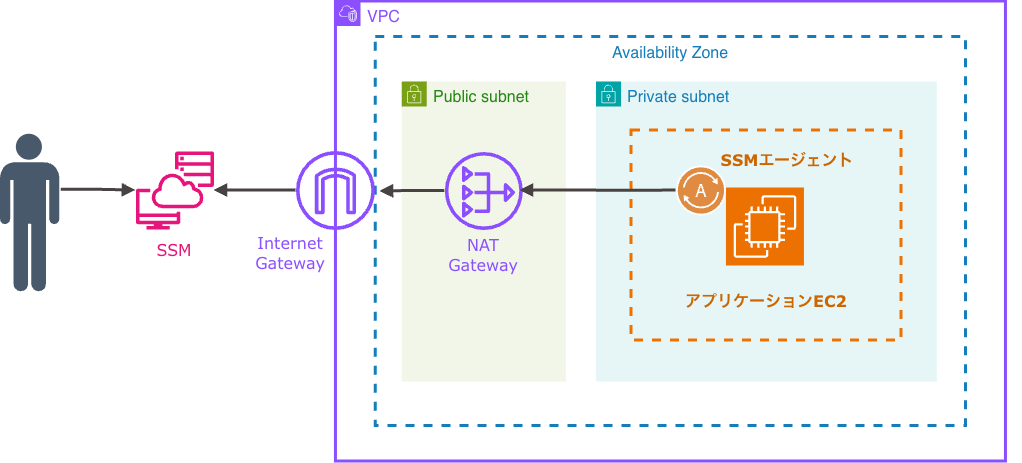



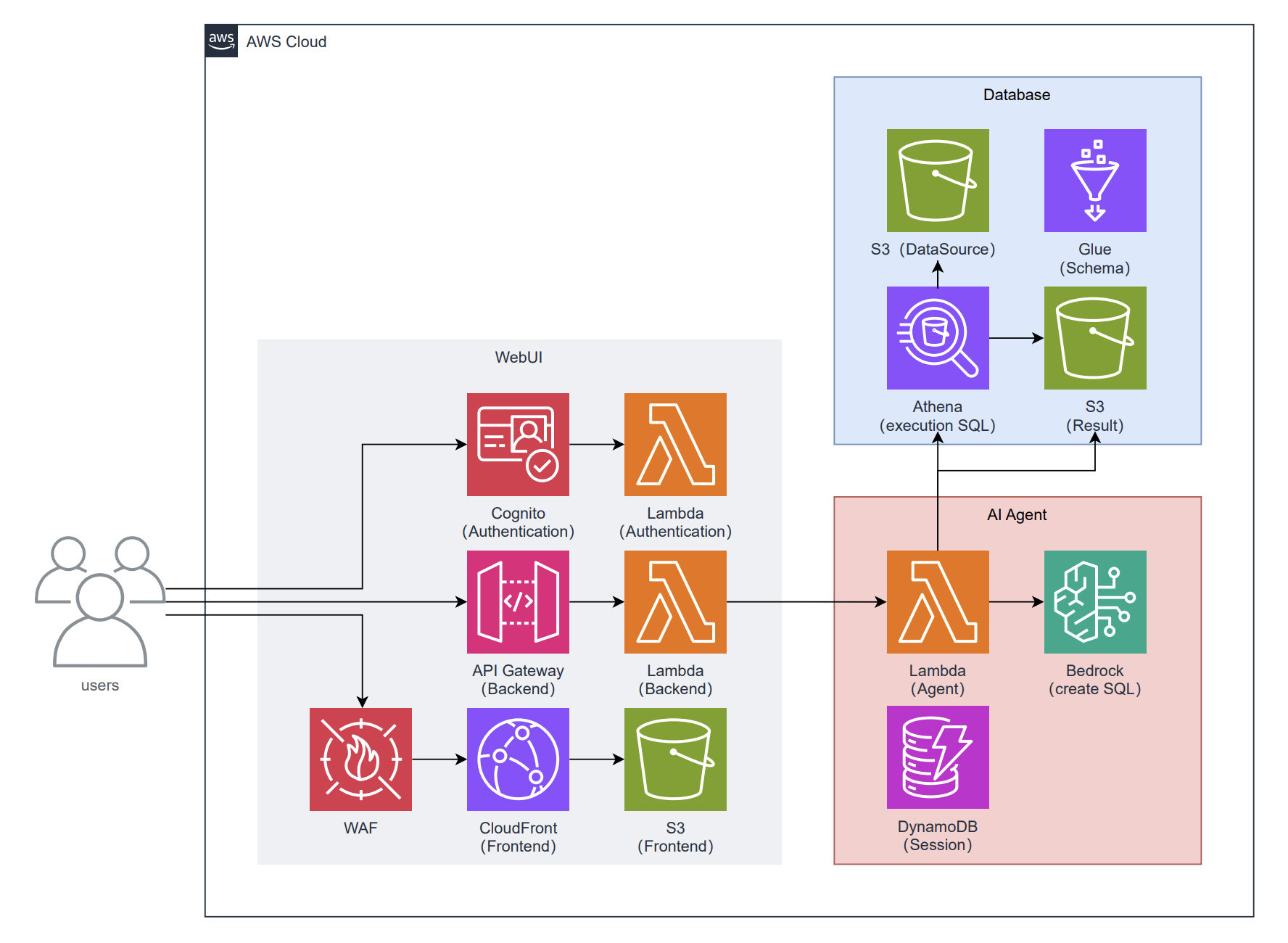

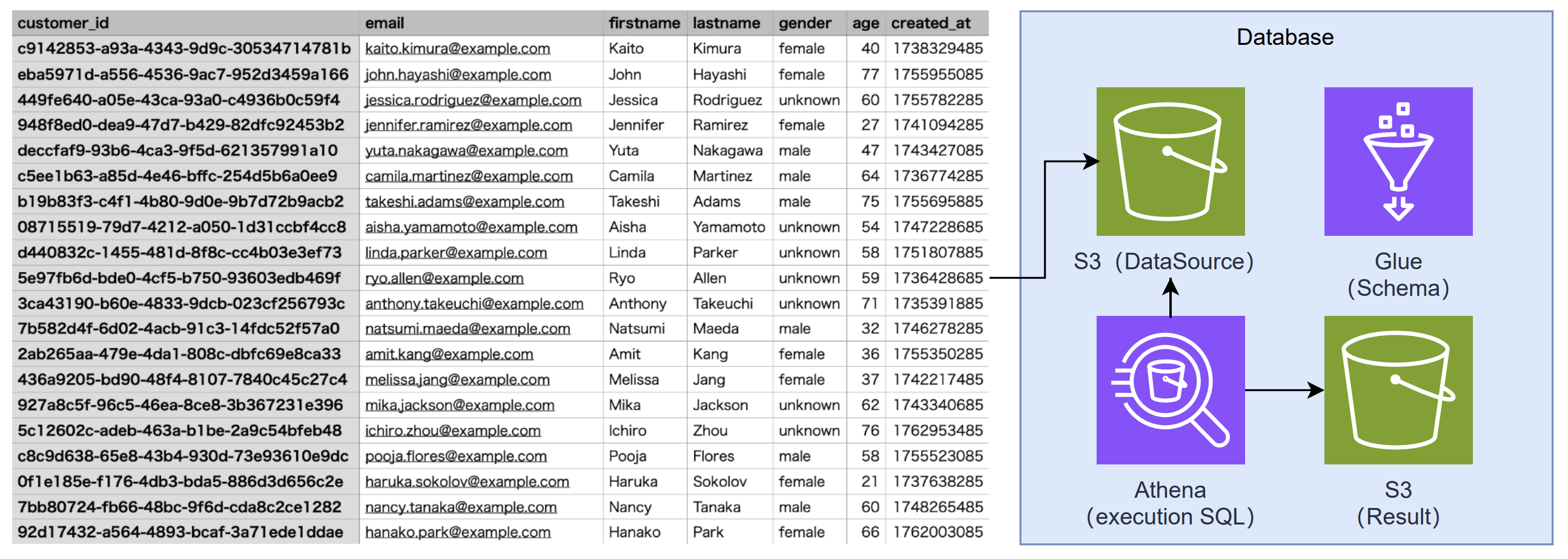
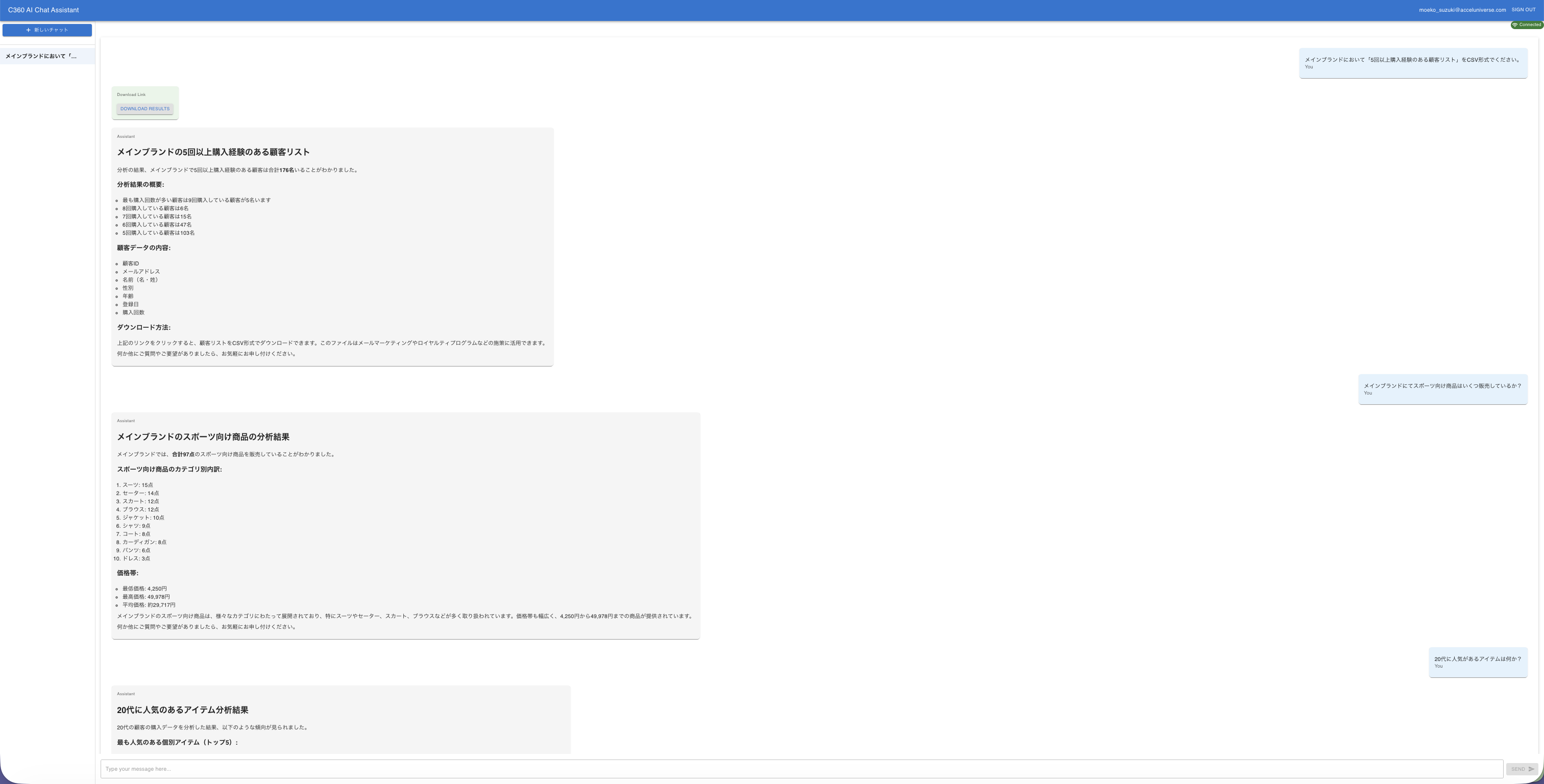 AIエージェントと会話ベースでのやりとり
AIエージェントと会話ベースでのやりとり
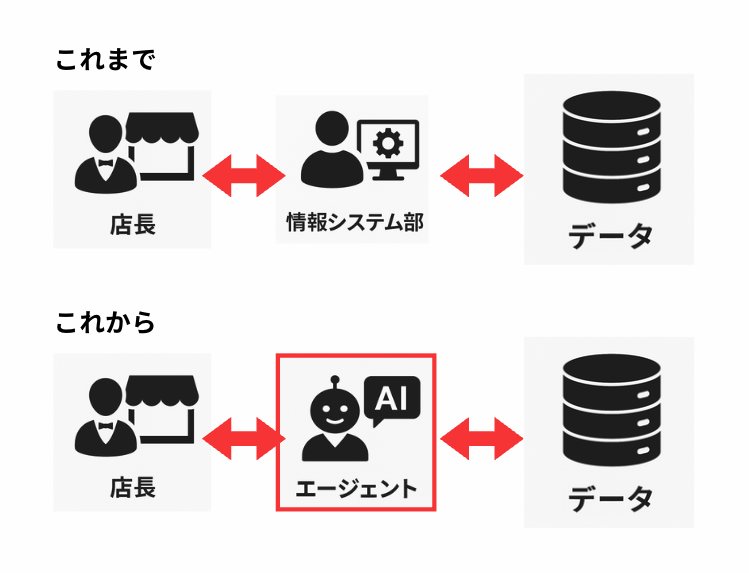 情報システム部→AIエージェント
情報システム部→AIエージェント