DEVELOPER’s BLOG
技術ブログ
SRE:コスト抑制のための異常値検知機構の実装

目次
- 実装前の課題
- 採用した技術と理由
- 実装した内容の紹介
- 改善したこと(抑制できたコスト)
実装前の課題
SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。
弊社では2021年2月からSRE活動を行っており、セキュリティ対策、サーバーのスケールイン/アウト運用化、アラートトリアージ運用化などを行っています。
そういったSRE活動をしていく上で、お客様から「AWSのコストを適正にしたい!」という要望を頂きました。
ヒアリングをしていく上で見えた課題が大きく分けると下記の4つありました。
①コストは月末にチェックしており、月中でコストが急激に上昇した場合発見が遅れてしまう。
② 不要なリソースが放置されていたり、新たなリリースによって生じたコストを確認していない。
③ AWSが提供するベストプラクティスによるコスト最適化が行われていない。
④ コストに対する意識が薄い。
これらの課題からAWSコストにおける活動視点が2つ見えました。
1. AWSコストの異常値の検知(課題①、②)
2. AWSコストの抑制活動(課題②、③、④)
2のAWSコストの抑制活動は現存する全てのAWSリソースに対して行う必要があり、手を付けやすく実装に時間がかからない1のAWSコストの異常値の検知を先に実装することに決めました。
(現在も2のAWSコストの抑制活動は継続中です。)
採用した技術と理由
AWSコストの異常値の検知の実装をするにあたり条件として、全てのAWSサービスを監視できる、なるべく人の手が入らないような運用ができるといったようなことが考えられます。
そのような条件で調査をしていく上で、以下の2つのAWSサービスが候補になりました。
①Cost Anomaly Detection
②AWS Budgets
これらのAWSサービスを簡単に説明します。
機械学習によって平均コストからの偏差の異常値を検知しそれらの異常値を通知するシステム
1ヶ月の予算を設定し、使用状況を追跡して予算を月中で超えた場合にアラートが発生する
どちらのサービスがお客様の状況に合っているかを考えるために、各サービスの長所・短所を洗い出しました。
| サービス | 長所 | 短所 |
| Cost Anomaly Detection |
・コスト異常が発生した場合にすぐに通知される ・閾値を設定し超えたコスト異常のみを通知する |
・どのコスト異常が検知されるかは機械学習任せ ・プロモーション時のスパイクなどの一過性の |
| AWS Budgets |
・全体のコストを把握しやすい ・実際のコストが予算の閾値に対してどのような |
・予算の設定が必要 ・AWSサービス毎のコスト異常が検知できない |
これらの長所・短所を考慮した結果、月中での検知ができ、アカウントやサービス毎に詳細に設定ができる①Cost Anomaly Detectionを採用することに決定しました。
短所は運用でカバーすることを考え、設計しました。次の章で実装の詳細を記述します。
実装した内容の紹介
今回実装に選んだサービスはCost Anomaly Detectionです。
主要な機能は以下の3つです。(2023年4月時点)
コストモニター
- 機械学習により平均からの上昇値を異常値として検出
- 検知する異常の種類は4つから選択(複数作成可能)
| 種類 | 詳細 |
| AWSのサービス | AWSで使用している各サービスについて個別で異常を検知する |
| 連結アカウント | 選択したアカウント(最大10個)の合計コストからの異常を検知する |
| コストカテゴリ | 選択したコストカテゴリ(最大10個)の合計コストからの異常値を検知する |
| コスト配分タグ | 選択したコストタグ(最大10個)の合計コストからの異常値を検知する |
アラートサブスクリプション
- 検出対象の通知要否に異常値の閾値($100、$1000など)を設定可能
- アラート頻度は3つから選択
| 種類 | 詳細 |
| 個々のアラート | 異常が検出された場合にすぐにアラートが表示される 通知にはAmazonSNSを使用 |
| 日次アラート | 1日に一度アラートが表示される 通知にはEメールを使用 |
| 週次アラート | 1週に一度アラートが表示される 通知にはEメールを使用 |
検出履歴
- 異常値として検出された履歴
検出を評価することでコストモニターの精度を向上させる
以下にどのような仕組みでコスト異常を通知させるのか説明します。
まず、平均からのコスト異常をコストモニターが機械学習で検知します。
下図の例では2つの異常値を検知しています。
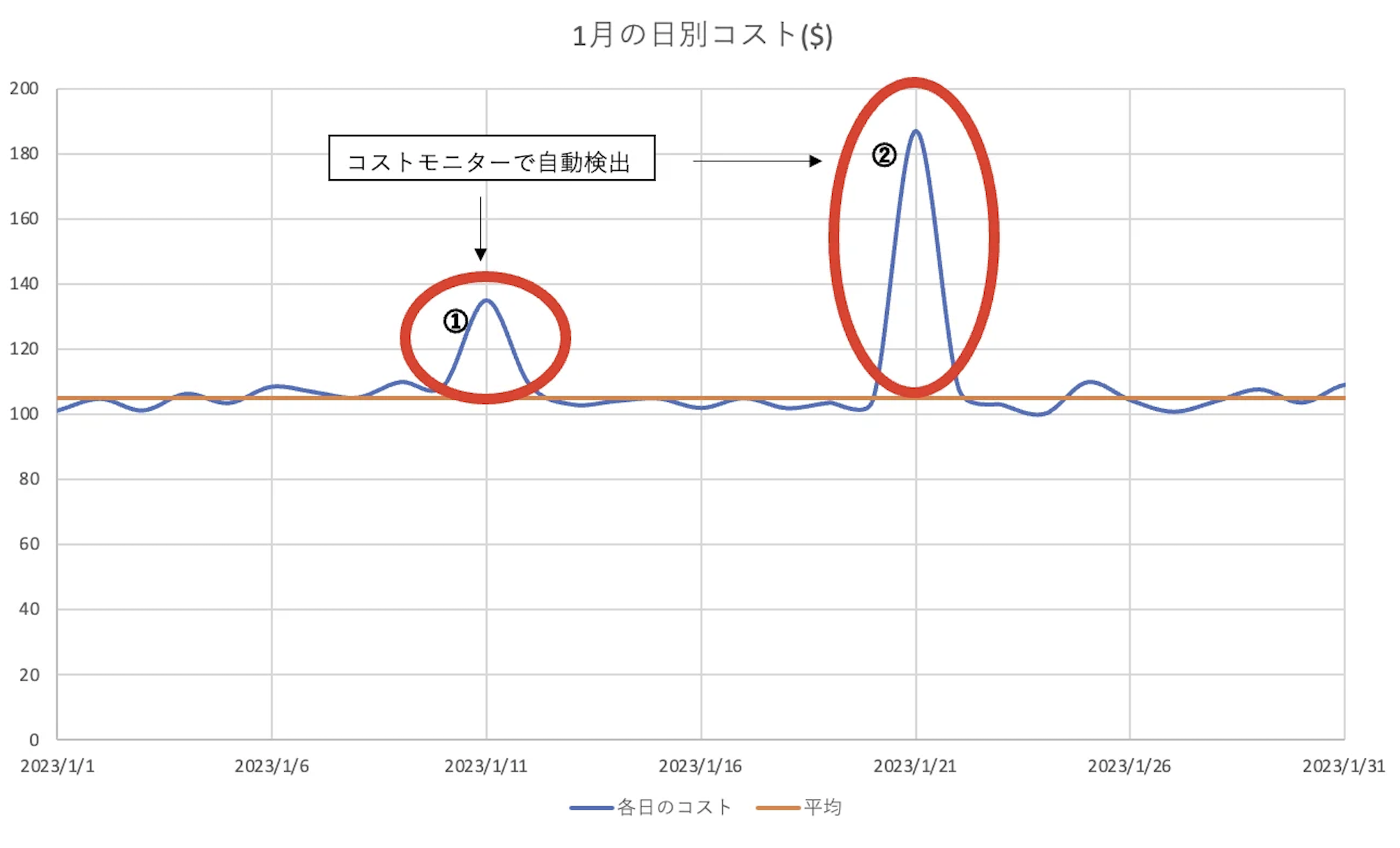
異常値の閾値として、アラートサブスクリプションに$50を設定したとします。
①の異常値は$30で閾値より低いため、通知されません。
②の異常値は$90で閾値より高いため、通知されます。
このようにして、通知されるコスト異常をフィルターすることができます。
通知された異常に関しては、CostExplorerやCloudWatchを使用して原因を解明し対処します。
また、月の初めに検出履歴を使用し、コストモニターで検知した異常が正確なものであったか評価を送信します。
通知されなかった異常も検出履歴を送信する段階でチェックし、通知はされなかったもののインパクトが大きいものは通知されたものと同様の対処を行います。
以上の実装・運用によりコスト異常をキャッチし、コストを抑制することに成功しています。
最後の章でCost Anomaly Detectionによってコストが減少した例を紹介します。
改善したこと(抑制できたコスト)
通知された異常としては、プロモーション時のスパイク起因による一過性のコスト上昇のものと、新しいAWSサービスのリリース起因によるコスト上昇があります。
プロモーション時のスパイク起因によるコスト上昇は一過性のものなので対処せず、新しいAWSサービスのリリース起因によるコスト上昇のみ対処します。
検知したコストの例としては、リリース起因により月初にDynamoDBのコストが上昇し、Cost Anomaly Detectionがそのコスト異常を検知しました。
原因を調査したところ、WriteRequestが増加してることがわかり、不要な書き込みをしない実装を行い、月末に対処が終わりました。
このコスト異常は月$2500のコストであり、早期発見によって抑え込むことができました。
コスト異常検知の紹介は以上になります。
コスト抑制活動は現在も行っており、抑制活動の一例としてはCloudWatchのログ出力が多く、不要なログ出力を削除することにより、月$4000のコスト削減に成功しています。
これらの活動により、コストインパクトが大きいリソースを対処していけば全体のコストが下がり、コスト異常検知の精度も上昇していくと考えています。
全てのAWSリソースを最適化することは長い道のりですが、売上を上げることと同様に、コストを下げることも大事なことであるので、AWSインフラの有効活用・改善をこれからも続けていきたいと思っております。
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)