DEVELOPER’s BLOG
技術ブログ
【Redshift vs. BigQuery】「運用性でRedshift」という選び方

目次
結局、何が違うのか?
こんにちは、アクセルユニバース株式会社、データサイエンティストの世古大樹です。
クラウド環境にデータウェアハウス(DWH)を構築しようとする場合、まず候補に上がるのはAWSの Redshift と、Google Cloud(旧GCP)の BigQuery でしょう。Redshiftが選ばれるのは、主に組織がすでにAWS上にシステムを構築しており、DWHも同じAWS上に作りたいからだと思います。AWSのシェアは国内トップであり(出典1)、「クラウドサービスならAWS」と考える企業も多いです。
一方、データ分析基盤に詳しい人は、Google Cloud のBigQueryを好みがちかもしれません。AWSがクラウドサービス全体をリードしているのに対し、Google Cloud はデータ分析や機械学習の領域に特別な強みがあると知られています。2019年に「DWHにBigQueryを採用しないことは大罪である」と主張するブログ記事(出典2)が公開され、このような意見は今も根強く残っています。
とはいえ、この記事の時からは月日が流れ、データウェアハウスを取り巻く環境は大きく変わりました。上のブログでRedshiftがBigQueryより劣っているとされた理由は「自前のクラスタ管理が必要など、フルマネージドでない」「スケールしない」という運用性の面でしたが、2022年に Redshift Serverless がリリースされ、BigQuery同様のフルマネージド・サーバーレスサービスとして使えるようになりました(今でもBigQueryの長所に「サーバーレス」を挙げる記事は多いですが、Redshiftもとっくにサーバーレスなのです)。
今は、単純に「RedshiftよりBigQueryの方が良い」と言えない状況です。両者の差は縮まっており、ほとんど同じ物のように見えます。RedshiftとBigQueryで共通している主な機能を、筆者が調査できた限りで表にしてみます。1つ1つ読む必要はありませんが、「これほど多くの機能が共通しているならどちらでもいいのでは?」と感じられるのではないでしょうか。
| 機能ジャンル | 機能 | 備考 |
|---|---|---|
| 処理最適化 | 自動スケーリング | |
| 処理最適化 | ストアドプロシージャ | |
| 処理最適化 | クエリ結果のキャッシュ | |
| 処理最適化 | マテリアライズドビュー | |
| 運用効率化 | クエリのスケジューリング | |
| 運用効率化 | ウェブベースのクエリエディタ | Redshift:Redshift クエリエディタ v2 BigQuery:Google Cloud コンソール、BigQuery data canvas |
| 運用効率化 | クエリプランの取得 | 実行中のクエリを細分化したステージや進捗状況を表示する機能 SQLの EXPLAINステートメント |
| 運用効率化 | クエリの待ち行列(キュー) | Redshift:WLM BigQuery:クエリキュー Redshiftはショートクエリを自動で判断して 待ち行列をスキップさせる機能もある。(後述) |
| 運用効率化 | 手動のテーブル設計・ 自動のテーブル最適化 |
|
| 拡張性 | フェデレーテッドクエリ・ 外部テーブル |
DWH外部のストレージや関係データベースにクエリを かける機能と、そのクエリに必要な便宜上のテーブル |
| 拡張性 | 半構造化データへのクエリ | Redshift:SUPERデータ型 BigQuery:JSONデータ型 |
| 拡張性 | ユーザー定義関数(UDF) | Lambda/Cloud Function を呼び出せるのも同じ。 |
| 拡張性 | ほぼ全てのBIツールとの円滑な統合 | |
| 拡張性 | SQLでの機械学習モデル構築 | Redshift:Redshift ML BigQuery:BigQuery ML |
| セキュリティ | 保存時暗号化 | Redshift:KMSキーでの暗号化(オプション) BigQuery:Google管理のAESキーでの暗号化(デフォルト) |
| レジリエンス | デフォルトの地理的分散 | Redshift:複数AZへの分散 BigQuery:複数ゾーンへの分散 |
| レジリエンス | 自動バックアップ | Redshift:30分毎の復旧ポイントを0〜35日の設定期間にわたり保持 BigQuery:全時点のタイムトラベルを7日間保持 |
| レジリエンス | リージョンレベルの災害復旧 | Redshift:スナップショット(手動バックアップ)と 復旧ポイント(自動バックアップ)のクロスリージョンレプリケーション BigQuery:クロスリージョン・データセットレプリケーション (プレビュー中の機能) |
実際のところ、「どちらを使ってもあまり変わらない」というのも一つの見識だと思います。自社や担当者が詳しい方のクラウドを選択するのも手、です。
しかし、より詳しく見ていくと、両者には明確な違いもあることがわかります。このブログでは、それを 「運用性ならRedshift、コスパならBigQuery」 という視点に整理し、2回に分けて説明します。1回目の今回はRedshiftの運用性を解説します。読者の方が適切なクラウドサービスを選べる助けになれば幸いです。
Redshiftの運用性
Redshiftの運用性が高いと言える根拠は、「1. AWS上の対向システムとの統合容易性」「2. 機械学習ベースの管理タスク自動化」「3. Glue/Lake Formation による一元的なメタデータ・アクセス権限管理」の3つです。
1. AWS上の対向システムとの統合容易性
前述した通り、AWSは国内シェアが高く、クラウドサービス業界を牽引する存在です。そのため多くの組織のITシステムはすでにAWS上に構築されており、オンプレミスでホストされていても、AWSへの移行が検討される場合が多いです。DWHには、これらのITシステムからデータを受け取るための連携が必要なので、DWHも同じAWS上に立てると簡単になります。構成としては、データソース・データレイク・データウェアハウス・データマートをはっきり分けて構築する、以下のようなものが考えられます(あくまで一例です)。
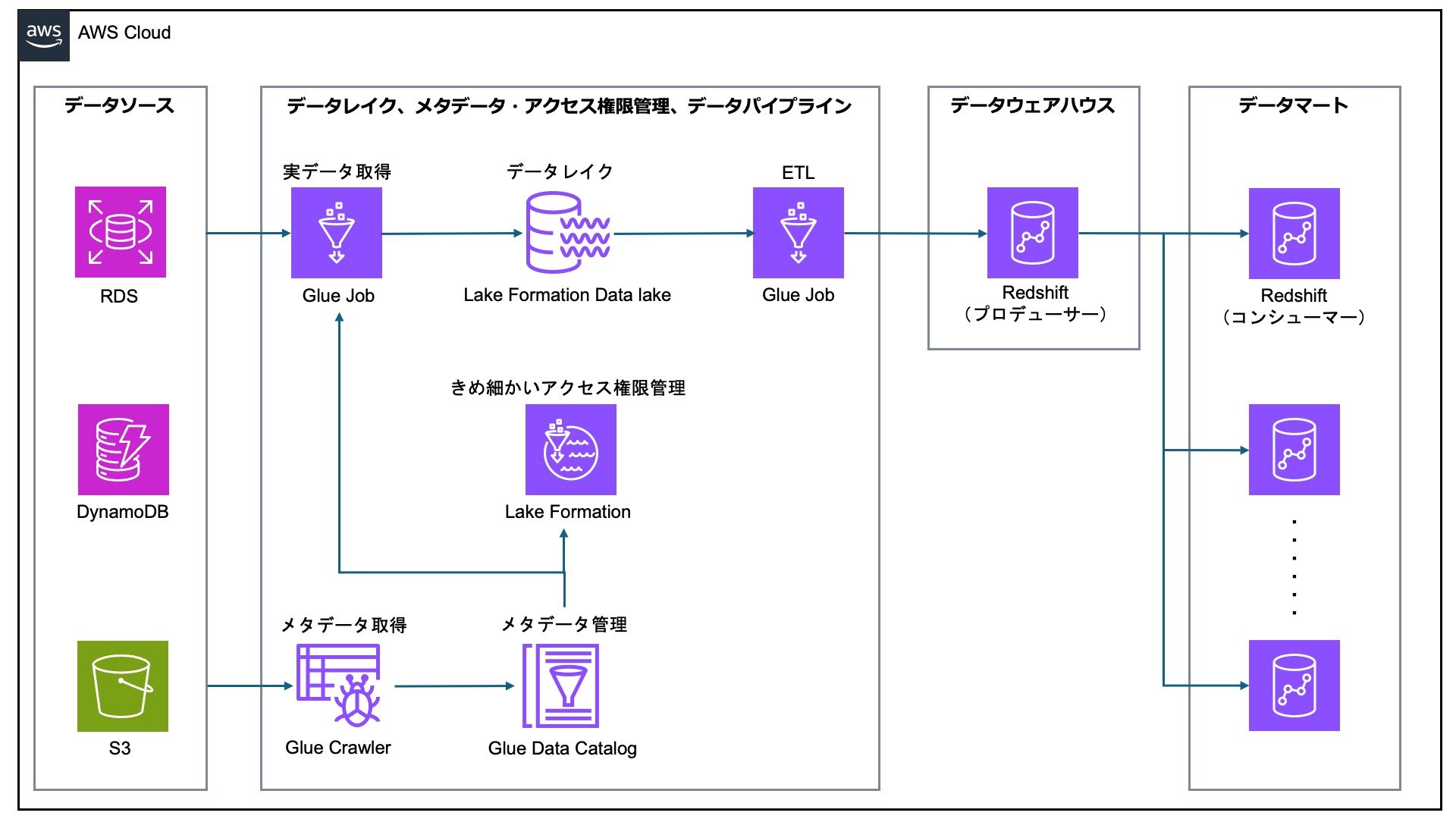 (筆者作成)
(筆者作成)
Glueが複数種類のデータソースを横断して、簡単にデータ収集・データレイク構築をしてくれるのが見て取れると思います。一方、AWSから Google Cloud へのデータ連携は複雑です。一般的なマルチクラウド構成の複雑さ(クラウド相互の認証認可、学習コスト、運用体制等)はもちろんのこと、RDSから Google Cloud へのデータ転送など、構築自体が大きく複雑になります。
AWS上のシステムと容易に統合できるRedshiftには、 運用簡素性・開発工数・自由度 の面でメリットがあるのです。
2. 機械学習ベースの管理タスク自動化
先ほどRedshiftとBigQueryで共通している機能の表を載せましたが、どちらかにしかない機能もあります。それらの機能の一つ一つは細々としたものですが、「機械学習ベースの管理タスク自動化」とまとめると、塵も積もれば山となる、Redshiftの強みと言って差し支えないものになります。
このことをより具体的に言うと、Redshiftは、 利用しているだけでデータやクエリの状況を自動的に判定し、DWHを最適化してくれる のです。他方のBigQueryは自動最適化の機能が限定的で、BIツールによるクエリを最適化する BI Engine がある程度です。基本的には、モニタリングを行って、その結果を判定し、手動でメンテナンスを行わなければなりません(出典3参照)。Redshiftであれば、機械学習などによって監視・判定・メンテナンスを自動化し、放っておくだけで処理を効率的にしてくれる様々な機能が提供されています。詳しく見ていきましょう。
バラしてしまうと、この節の元ネタは Black Belt(出典4) の、主に pp.20-33 です。この Black Belt 資料自体、Redshiftを理解するうえで必読のものなのでぜひ読んでいただきたいのですが、それはそれとして、この記事では Black Belt をもとにRedshift独自の(=BigQueryにはない)管理機能をまとめ、筆者の観点から補足を行います。
Redshift独自の自動管理機能のまとめ
- カラム(列データ)の最適化
- ゾーンマップとソートキー:カラムをあらかじめソートし、ディスクの物理ブロックごとに最小値と最大値を記憶しておくことで、不要なブロックを読み飛ばして処理する。
- 圧縮エンコードの自動管理:カラムごとに最適なエンコード方式を自動で判定し、圧縮する。(手動選択も可能)
- テーブルの最適化
- 自動テーブル最適化:利用状況を判定し、ソートキーや分散キーを必要に応じて自動設定する。(手動設定も可能)
- Vacuum Delete 自動化:Delete・Update 後の削除領域の開放を、適切なタイミングで自動実行する。(手動実行も可能)
- ソート自動化:テーブル全体のソートは負荷が高くなるが、機械学習によってソートが必要な部分だけをピンポイントに、適切なタイミングでソートすることで、パフォーマンスやアクセスに影響なくソートできる。(手動ソートも可能)
- ネットワークの最適化
- データを均等分散して並列処理に最適化するだけでなく、JOINするレコード同士を同じ場所に置くことで、I/Oを削減できる。
- データを均等分散して並列処理に最適化するだけでなく、JOINするレコード同士を同じ場所に置くことで、I/Oを削減できる。
- クエリ実行の最適化
- Analyze 自動化:テーブルの統計情報を適切なタイミングで自動更新することで、最適な実行計画のもとにクエリを行える。
- Auto WLM:ワークロードごとに、物理リソース(メモリ・CPU等)の割当を自動で最適化する。
- ショートクエリアクセラレーション:クエリの実行時間を予測し、短時間と判断されたクエリは、特別な領域でスムーズに処理される。(オフにもできる)
「ゾーンマップとソートキー」「自動テーブル最適化」について
たとえばテーブルの列 date: DATE がちゃんと日付順に並んでいないと、普通は WHERE date >= '2024-01-01' のようなWHERE句を含むクエリに対してフルスキャンを行う必要があり、応答時間や課金額が無駄に大きくなってしまいます。そこで列をいくつかの塊(1MBのブロックごと)にまとめ、塊の中の最大値と最小値をメモリに保存しておけば、最大値が 2024-01-01 未満である部分を読み飛ばして処理することができ、効率が上がります。これがゾーンマップです。
しかし、これだけではまだ無駄があります。読み込むブロックに含まれる全てのデータが 2024-01-01 以上とは限らないからです。例えば100件中1件のみが 2024-01-01 以上で、99件のスキャンは無駄だった、ということもありえます。そのため、さらに列のデータを降順にソートしておけば、少なくとも最大値が 2024-01-01 以上である最後のブロックの1つ前のブロックまでは全て 2024-01-01 以上ということになるので、効率的な処理が可能です。このようにソートする列を指定するものがソートキーで、適切なソートキーを自動設定してくれるのが自動テーブル最適化です。
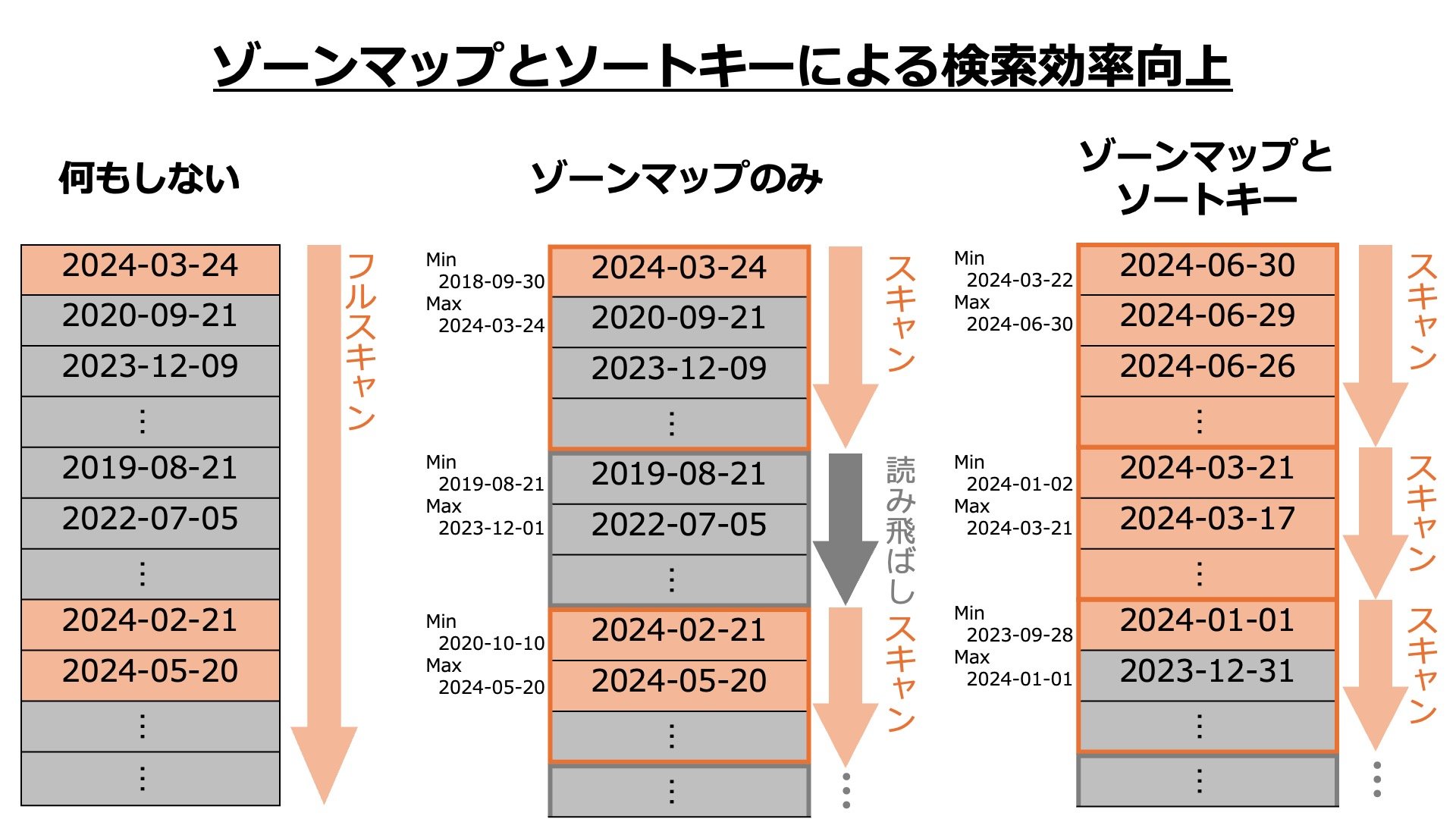 (筆者作成)
(筆者作成)
これらの機能は検索の効率を上げるという点で、インデックスに似ています。BigQueryにはインデックスがあり、一度作成したインデックスを自動管理してくれる機能もあります。しかし、最初にインデックスを作るには手動のDDLコマンドが必要であり、適切なインデックスを作るためにクエリパターンの監視・解析も必要です。管理の簡素さという点で、Redshiftに軍配が上がるところです。
3. Glue/Lake Formation による一元的なメタデータ・アクセス権限管理
これは厳密にはDWHの機能ではありませんが、AWSで多くの場合Redshiftと併用されるサービスのメリットとして挙げます。
「メタデータ」とは何かというと、データレイクやDWHに保存されているデータ(実データ)を説明する情報です。具体的には、テーブル・列・データ型・データソース・データ作成日などの説明です。そしてメタデータは「データカタログ」というデータベースに保管されます。データカタログを調べてメタデータを見れば、どのデータが「使える」データなのか、どの列が何を意味しているのかなどがわかります。DWHに蓄積される膨大なデータを活用するためには、「どこにどんなデータがあるのか」がわかることが重要です(わからないと使えるデータも埋もれてしまいます)。
データに対するアクセス権限管理についても、メタデータが重要な役割を果たします。たとえば、メタデータに「センシティブデータであるかどうか」という列を加え、それを利用してセンシティブデータを閲覧できるユーザーを制限する、というような運用が可能になります。また、(あまり無いことですが)機密情報に関わるメタデータ自体へのアクセスを制限することも考えられます。
AWSではETLとメタデータ・アクセス権限管理が一体化している ため、このあたりの管理が大きく省力化されます。先ほどの構成例をもう一度見てみましょう。
まず、下の Glue Crawler がデータソースを探索し、メタデータを作って Glue Data Catalog に保管します。保管されたメタデータの使い道は2つあります。1つはGlueのJob(ETLタスク)において、取得対象のデータを特定するために使われます。もう1つは Lake Formation で、テーブルの列単位などのきめ細かい粒度でのアクセス権限を設定するために使われます。Lake Formation のアクセス権限管理はデータレイクだけでなく、データマートにも及びます。Redshiftデータ共有と統合することで、コンシューマーRedshiftのアクセス権限を Lake Formation で管理することができるのです。
要するに、AWSではETLとメタデータがGlueという1つのサービスに合体しており、さらにGlueが統合的なアクセス権限管理を行う Lake Formation と高度に接続されていることで、データの管理負担が抑えられる、ということです。これは大きな特長です。
Google Cloud ではこうは行きません。ETLサービスであるDataflowにはメタデータ管理などの機能がなく、Data Catalog というサービスで別途データカタログを作成する必要があります。また、アクセス権限管理も Data Catalog、Cloud Storage(データレイク)、BigQuery(DWH)で個別に行わなければなりません(かなり大変そうじゃありませんか?)。特に Cloud Storage できめ細かいアクセス権限管理を行うことは、煩雑なため公式に非推奨とされています。Cloud Storage のきめ細かいアクセス権限管理はACL(Amazon S3 のACLと同様のものであり、現在はAWSでも Google Cloud でも非推奨とされている方式)で行う必要があるためです。
きめ細かいアクセスでは、2 つの異なるアクセス制御システム間で調整が必要になります。このため、意図しないデータ漏洩が発生する可能性が高くなり、リソースにアクセスできるユーザーの監査は複雑になります。特に、個人を特定できる情報などの機密データを含むオブジェクトが存在する場合は、均一なバケットレベルのアクセスを有効にしてバケットにデータを保存することをおすすめします。
(出典5)
......と言われても、一部のユーザーから隠さなければならない機密データを含むバケットで均一なアクセスを有効にするとなると、
- 機密データを見てはいけないユーザーがそのバケット(=データレイク)全体を見られなくなるか、
- 機密データを保管するバケットをデータレイクから分割し、そのバケットにアクセス制限をかけるか
しかありません。1だとそのユーザーのデータ利用が制約されてしまいますし、2だと「すべての生データを1箇所に集約する」というデータレイクのコンセプトそのものに反してしまいます。Google Cloud ではデータレイクのアクセス権限管理に課題があると言わざるを得ないでしょう。
まとめと次回予告
今回の記事では、BigQueryと比較したときのRedshiftの運用性について解説しました。ポイントをまとめておきます。
- RedshiftもBigQueryも、多くの機能が共通しているが、詳しく見ると「運用性ならRedshift、コスパならBigQuery」という違いがある。
- Redshift中心の構成では、AWS上の対向システムからデータ収集を行うのが簡単。
- Redshiftは、自動管理機能によって設定・監視・メンテナンスの負担が小さくなる。
- AWSでは、ETL・メタデータ・きめ細かいアクセス権限管理が Glue/Lake Formation に一元化されており、効率的な運用が可能。
次回は、実際にクエリを投げてかかった費用と応答時間を比較しながら、「BigQueryのコスパ」について解説します。「BigQueryはコストパフォーマンスに優れている」とはよく言われますが、必ずしもRedshiftより安くて速い訳ではありません。それでもBigQueryにあるコスパ上の利点とは何でしょうか?(次回記事はこちら)
出典(いずれも記事公開時点閲覧)
- 総務省『情報通信白書令和6年度版 データ集』「第4章第8節 7. PaaS/IaaS利用者のAWS、Azure、GCP利用率」 https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r06/html/datashu.html#f00281
- データエンジニアの酩酊日記『近年のデータ分析基盤構築における失敗はBigQueryを採用しなかったことに全て起因している』 https://uma66.hateblo.jp/entry/2019/10/17/012049
- Google Cloud『BigQuery 管理の概要』 https://cloud.google.com/bigquery/docs/admin-intro?hl=ja
- Amazon Web Services『Amazon Redshift 運用管理 AWS Black Belt Online Seminar』 https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt2023Amazon-Redshift-Management0331v1.pdf
- Google Cloud『アクセス制御の概要』 https://cloud.google.com/storage/docs/access-control?hl=ja
X(旧Twitter)・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

アマゾンジャパン品川オフィス はじめに AI BPRとは ワークショップの内容 参加者の声 組織への展開と本格導入 1.はじめに 売上や現場の数字を見ながら、次々と判断を下す毎日。「これAIでやってくれないかなぁ」と感じたことはありませんか。 生成 AI のニュースは毎日のように流れてきますが、自社の業務で「使える」という実感を持てている方は、まだ少ないのではないでしょうか。業務の中で日々判断を重ねている方ほど、目の前の業務を AI が

はじめに 環境構築手順 Store Manager Agentで実現できること まとめ 1.はじめに 店舗運営において、こんなお悩みはありませんか。 売上データは見ているが、次に何をすべきか判断に迷う 売場づくりや品揃えが、どうしてもベテラン頼みになってしまう 在庫・売上・時間帯など、考えるべき要素が多すぎる 数字の振り返りはしているものの、改善アクションに落とし込めない こうした課題は、特定の業種だけのものではありません。 例えば、 ス

目次 「費用対効果」で選ぶには? 結果:BigQueryは「安定」している 実験条件 データセット データウェアハウス設定・計測条件 クエリ コード集 前処理 データロード等 計測記録の取得(BigQuery) リザルトキャッシュの無効化(Redshift Serverless) クエリ1-1:小規模構造化データ、単純集計 クエリ1-2:小規模構造化データ、集計+ウィンドウ関数 クエリ1-3:小規模構造化データ、ウィンドウ関数+CTE+集計 クエリ2-1:

データ分析基盤構築とは、大量のデータを蓄積・変換・分析するためのインフラを開発することです。主軸となるデータレイク・データウェアハウス・BIツールの他、NoSQLデータベース、データパイプラインツール、ETLツールなど様々な要素があり、それぞれ様々なベンダーから多種多様な製品が出ています。 比較項目は膨大で、複雑です。性能・機能・セキュリティ・コスト......一体何を基準に選べばよいのでしょうか。当社には一つの戦略があります。それは、 " 分析ツール