DEVELOPER’s BLOG
技術ブログ
Googleが発表した自然言語処理モデルText-to-Text Transfer Transformer(T5)とは?

Googleが発表したBERTは記憶にも新しく、その高度な性能はTransformerを使ったことで実現されました。
TransformerとBERTが発表される以前の自然言語処理モデルでは、時系列データを処理するRNNとその発展形であるLSTMが使われてきました。このLSTMには、構造が複雑になってしまうという欠点がありました。こうしたなか、2017年6月に発表された論文「Attention is all you need」で論じられた言語モデルTransformerとAttentionと呼ばれる手法は、LSTMのような複雑な構造を使わずに高性能を実現したのでその後の言語モデル開発に大きな影響を与えました。
今回は転移学習モデルTransformerを用いた新しいモデルのText-to-Text Transfer Transformerを紹介します。
Text-to-Text Transfer Transformer(T5)とは
近年、自然言語処理の分野では、事前学習モデルを利用しfine tuningをする転移学習(transfer learning)が強力な技術として様々なタスクで少ないデータセットでも精度向上をもたらしています。特に2018年に発表されたBERT以降、研究が盛んに行われており、ベンチマーク(GLUEなど)のSoTAも頻繁に更新されています。この論文に「多様なアプローチ、手法、実践がなされている」と書かれているように、それぞれの研究によってアプローチのしかたも異なります。
その中で、この論文で紹介されているモデルT5は「Text-to-Text Transfer Transformer」の略で、Text-to-Textとある通り、入力と出力の両方をテキストのフォーマットに統一して、転移学習を行うモデルです。
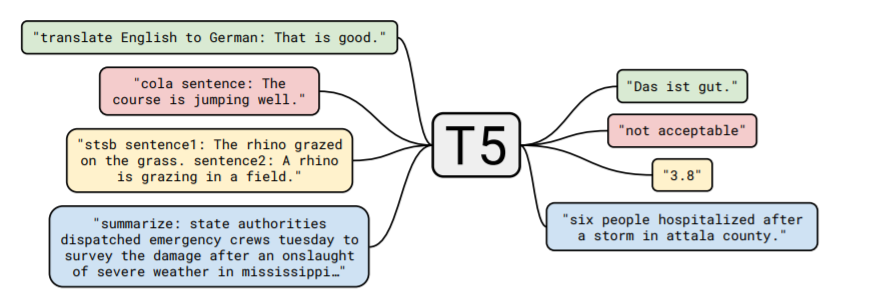
上図にあるように、翻訳、質疑応答、分類、要約などすべてのタスクで入力をテキストで受けて、出力もテキストの形で返しています。また、このモデルの特徴は一つのモデルで上で挙げたようなタスクをすべてこなせることです。実際にタスクを行わせる際には上の図にあるように"translate English to German:"とPrefixを与えてどのタスクかを知らせています。T5のモデル構造のベースはTransformerとなっていて、論文中でも特別新しい手法を紹介しているわけではありません。転移学習における研究が盛んに行われ、異なる手法の比較が難しい中で、どんなモデル構造やデータセットなどを用いれば良いのかを、T5を用いて比較していくことがこの論文の中心となっています。
精度比較
それでは論文中で行われている実証研究について見ていきます。
Baseline
まずベースラインについて見ていきます。
事前学習どの程度行ったなどの詳細はここでは述べませんが、基本的なモデルの構造としては一般的なTransformerを用いて、特徴的なのはすべてのタスクがtext-to-textの形式にされていることです。また事前学習にはC4(Colosal Clean Crawled Corpus)というデータセットを使っています。後にデータセットでの精度比較があるのでC4の詳細はそこで述べます。
教師なし学習の目的関数ついては、BERTで用いられたMasked Language Modelingなどに倣った"denoiding objective"を使用しています。上の図を見るとイメージしやすいと思います。

ベースラインの性能を簡単に表で見ていきます。一番上がベースラインの結果の平均、2番目が標準偏差、最後が事前学習を行っていないモデルの結果となっています。この結果の中で、GLUEとSQuADに関してはBERTのモデルと非常に近いスコアを出しているそうです。またEnFr(英語からフランス語への翻訳)に関しては、十分に大きな訓練データがあるために、事前学習で得られる情報が重要ではなくなっているため、ベースラインのスコアと事前学習をしなかったモデルのスコアがあまり変わらないという結果が出ています。
それではここからモデル構造などを変えての比較を見ていきます。
モデル構造
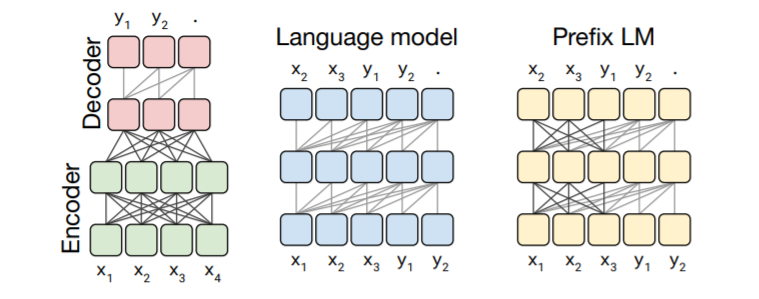
モデルのベースは上でも述べたようにTransformerで、今回の比較は次の三つについて行っています。
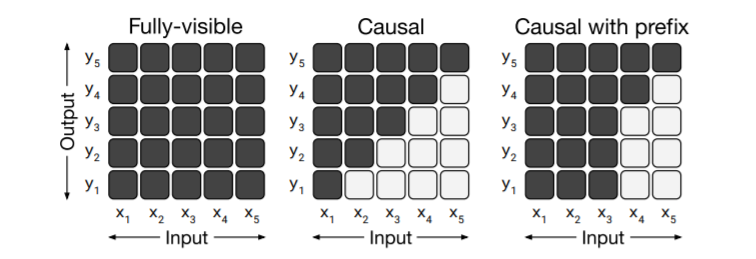
- Encoder-Decoder:基本的なTransformerで採用されているモデル Encoderはfully-visible attention mask(全ての入力を出力の予測に用いるマスクになっている)で、 Decoderはcasual attention mask(予測する単語を見えないようにしている)を採用したモデル
- Language Model:Encoder-DecoderでのDecoder部分のみを使ったようなモデル
- Prefix LM:Language Modelをベースに、Prefix部分はマスクしないという変更を与えたモデル
以下の図がそれぞれのモデル構造のイメージ図になっています。
また、attention maskのイメージ図は下のようになっています。
Transformerの詳細については、【論文】"Attention is all you need"の解説をご覧ください。検証結果は以下のようになります。
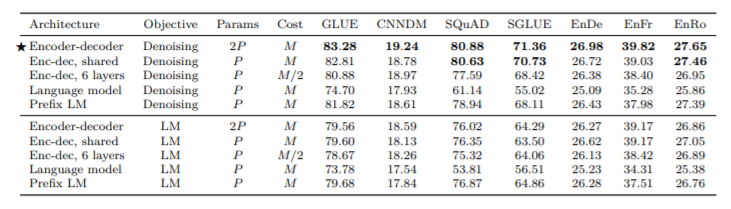
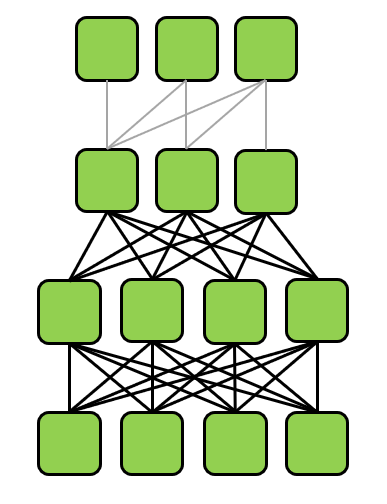
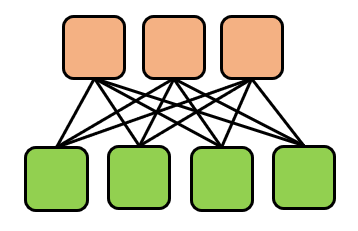
ここで教師なし学習の目的関数として、ベースラインと同様のdenoisingだけでなく、LM(通常の言語モデルで予測)も採用しています。また、モデルの構造で上の三つの他に"Enc-dec,shared"と"Enc-dec,6 layers"があります。Enc-dec,sharedはencoderとdecoderでパラメータを共有したもので、Enc-dec,6 layersはencoderとdecoderの層をそれぞれ12から6にして、パラメータを半分にしたもので、計算コストも半分になっています。それぞれのイメージ図は以下のようになります。
Enc-dec,shared
Enc-dec,6 layers
結果を見てみると、まず目的関数については全体を見てもDenoisingのほうが良い結果を得ています。モデル構造については、Encoder-decoderが一番良い精度を出しています。Enc-dec,sharedはほとんど変わらず、パラメータを共有するしないは精度にあまり影響を及ぼさないことが分かり、Enc-dec,6 layersはその2つと比べて性能が劣り、層の数はある程度影響を与えています。また、Language ModelとPrefix LMもEncoder-decoderよる精度はわるくなっていて、2つを比べるとPrefix LMのほうが良い結果になっていてます。
Objectives
次に教師なし学習の目的関数について比較を行っていきます。
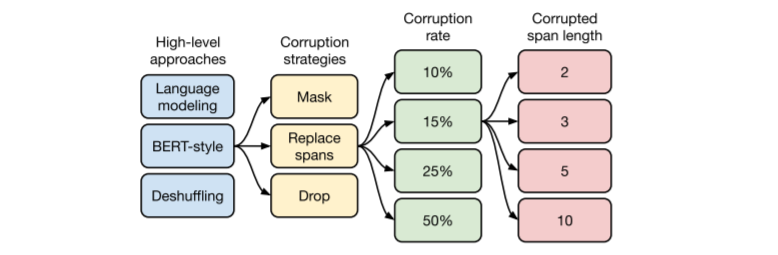
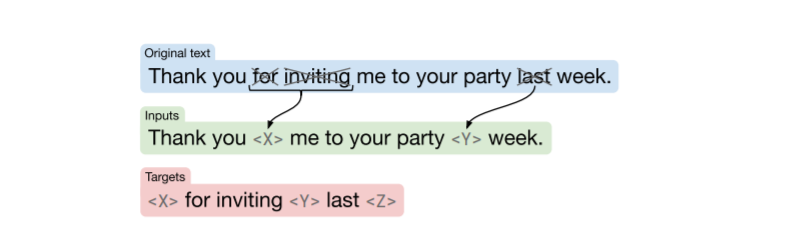
ここでは、上の図の左から順にそれぞれ検証していきます。下のような目的関数の例も記載されているので、逐次見ていきます。この例の元の文は"Thank you for inviting me to your party last week."です。

High-Level Approaches
ここで比較するのは次の三つの目的関数です。

- Prefix language modeling :オリジナルの文章の途中までを入れて、その続きの文章を予測
- BERT-style:一部の単語がマスクトークンに置き換えられた文章から、オリジナルの文章を予測
- Deshuffling:単語がランダムにシャッフルされた文章から、オリジナルの文章を予測
 結果をみると、BERT-styleが、翻訳タスクではPrefix language modelingと大差ないものの、全体で見ると一番優れていることが分かります。
結果をみると、BERT-styleが、翻訳タスクではPrefix language modelingと大差ないものの、全体で見ると一番優れていることが分かります。
Corruption Strategies
上の結果から、BERT-styleが優れていることが分かりました。ここでは、そのBERT-styleをベースとして、下の例のような三種類のトークンの入れ方を比較します。
![]()
- mask tokens:一部の単語がマスクトークンになっている文章から、全文を予測
- replase tokens:一部の単語がマスクトークンになっている文章から、マスクされた部分のみを予測
- drop tokens:一部分が抜かれた文章から、抜かれたところのみを予測
また、下の表中のMASS-styleは、BERT-styleに似た方式のものだそうです。詳細はMASS: Masked Sequence to Sequence Pre-training for Language Generationをご覧ください。
 結果を見てみると全体的に似たようなスコアを出していて、特別優れているものはありません。ただ、BERT-styleとMASS-styleは全文を予測する目的関数なのに対して、replace tokenとdrop tokenはマスクされた部分のみを予測するので、より短い時間で訓練可能となり、その点でいうと優れていると言えます。また単純に一番良いスコアを出した数でいうと、drop tokenを使用したものになりますが、SuperGLUEでは、replace tokenのほうが良い結果を出していて、この2つのことからreplace tokenを用いるのが一番良い手法だと結論付けています。
結果を見てみると全体的に似たようなスコアを出していて、特別優れているものはありません。ただ、BERT-styleとMASS-styleは全文を予測する目的関数なのに対して、replace tokenとdrop tokenはマスクされた部分のみを予測するので、より短い時間で訓練可能となり、その点でいうと優れていると言えます。また単純に一番良いスコアを出した数でいうと、drop tokenを使用したものになりますが、SuperGLUEでは、replace tokenのほうが良い結果を出していて、この2つのことからreplace tokenを用いるのが一番良い手法だと結論付けています。
Corruption Rate
次にマスクする割合を10%,15%,25%,50%と変えて比較します。
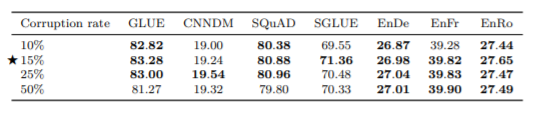 結果を見てみると、それぞれであまり大きな精度の違いは見られず、マスクする割合はモデルの性能に大きな影響を与えないということが分かります。ただし、50%に関しては特にGLUEとSGLUEで精度が悪くなっており、マスクする割合が大きすぎると、モデルの性能に悪影響を与えてしまうことが分かります。このことから、従来の研究に沿ってBERTでも採用されている15%が適切としています。
結果を見てみると、それぞれであまり大きな精度の違いは見られず、マスクする割合はモデルの性能に大きな影響を与えないということが分かります。ただし、50%に関しては特にGLUEとSGLUEで精度が悪くなっており、マスクする割合が大きすぎると、モデルの性能に悪影響を与えてしまうことが分かります。このことから、従来の研究に沿ってBERTでも採用されている15%が適切としています。
Corrupted Span Length
次に、マスクするトークンの平均の長さを変えて比較します。
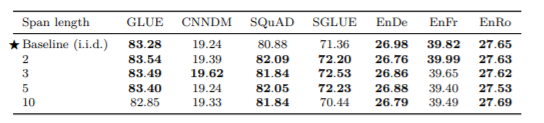
結果を見ると、10の場合はあまり良くなっていないので、長すぎると性能が下がっていくことが分かります。ただ、それ以外は、あまり性能に差はなく、ベースラインのものをそのまま採用することにしています。
結論
ここまで、目的関数に関する4つの項目について比較を見ました。結果的に上で示した図のフローになります。
この検証で一番モデルの性能に影響を与えたのは、最初に見た3つ目的関数の選択でした。性能だけを見ると他の要素はあまり重要でないように感じますが、マスクトークンの取り方で、予測する文・単語は短い方が学習にかかる時間が短く、計算コストも抑えられることも大切なポイントになります。
Dataset
次に、使うデータセットを変えることでの性能の違いを見ていきます。まず、使用するデータセットについて、T5で重要となるC4について説明したいと思います。
C4(Colosal Clean Crawled Corpus)
C4はColosal Clean Crawled Corpusの略で、Webから取得できるCommon Crawlを元に以下の前処理したものです。
- ピリオド、クエスチョンマーク、ビックリマーク、コーテーションマークで終わる文のみを使用する。
- 汚い言葉、不適切な語を含むページは取り除く。
- javascriptの単語を含む行は取り除く。
- ダミーテキストがあるページは取り除く。
- ソースコードなどは取り除く。
- 重複文は取り除く。
C4の一番の特徴は、データのサイズがかなり大きいことです(データが多様)。Common Crawlが1か月に20TBになるようなデータで、ここでののC4は前処理をすることで、750GBにしたデータセットです。これは結果の表にも書いてありますが、他のデータセットに比べてかなり大きなデータとなっており、ここでの比較により、データサイズによりどんな違いが出るのかを見ることができます。
比較の結果は以下のようになります。
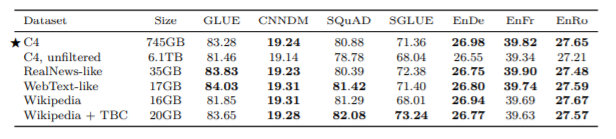
まず、C4とC4,unfiltered(前処理をしていないC4データセット)を比べると、当たり前ですがC4のほうが精度が良く、前処理が重要であることが分かります。
次に、C4と他のデータセットを比べると、タスクによって精度の良いデータセットが違っているように感じます。まず分かることは、データのサイズが単純に大きいだけでは、必ずしも精度は上がらないことです。また、このような結果になった要因として、使ったデータセットがあるタスクに適応しやすいデータだったということが挙げられます。このことから、それぞれのタスクに対して適したデータセット、ドメイン固有のデータセットを使ったほうが精度が高くなることも確認できます。
また一般的にドメイン固有のデータセットのサイズは小さくなりますが、そういったサイズの小さいデータを繰り返し学習させるのと、より大きな多様性のあるデータを繰り返さずに学習させるのでは、どちらが良いのかを検証したのが、次の表とグラフです。
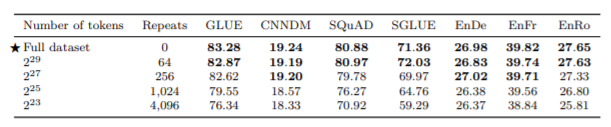
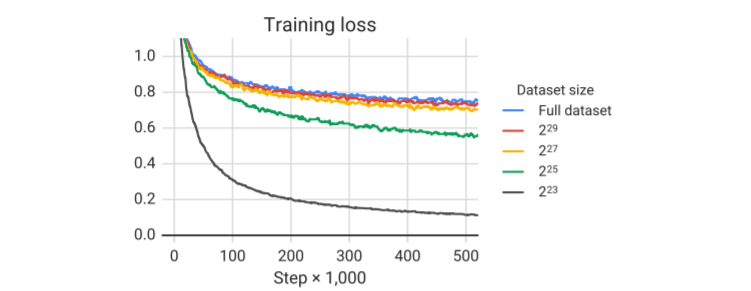
結果を見ると、データの大きさを小さくして、リピートの回数を増やすほど、Training lossの収束が速くなるものの、精度が低くなっていることが分かります。どんどん過学習になりやすくなっているということです。このことから、可能であればより大きなデータセットを使って、データに多様性を持たせたほうが良いことが確認できます。
Fine-tuning
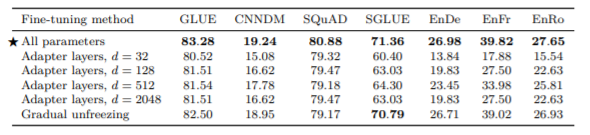
次に、fine-tuningの仕方について以下の3つを比較しています。
- All parameters:モデルのすべてのパラメータをfine-tuningして調節する
- Adapter layers:事前学習のモデルを壊さないで保持するために、Dense + ReLU + Denseの層からなるAdapter layerを各層の間に入れてfine-tuningする
- Gradual unfreezing:徐々にチューニングするパラメータを増やして学習範囲を広げていく
結果は、下のようになり従来の手法の通り、全てのパラメータをfine-tuningしたほうが精度が高くなっています。
Multi-task
次に、Multi-taskという名の通り、まとめて一度に様々なタスクを学習させることにより、精度がどのように変化するかを検証していきます。つまり、普通はあるタスクに対してひとつの教師なし学習を行わせるのに対して、タスクをミックスさせることにより、全てのタスクで同じパラメータを共有するということになります。 ここで比較するのは、
- Equal:全てのタスクを同じ割合で学習させる方法
- Examples-proportional:各タスクのデータのサイズに上限Kを与えて、その中でランダム得たデータを学習させる方法
- Tempereture-scaled:一番でデータの少ないタスクと一番データの多いタスクの差に制限をかけたデータで学習させる方法
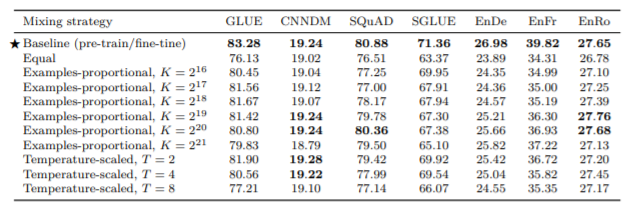
結果を見ると、タスクごとに教師なし学習により事前学習+fine-tuningしたのに比べて、全体的に性能は劣っていて、特にEqualのときが一番悪くなっていて、GLUE、SGLUEのタスクに関してはすべて良い性能が出ていません。ただし、Examples-proportionalとTempereture-scaledについては、パラメータをうまく調節できた場合に限って、CNNDM、SQuADなどで精度が良くなっていることが分かります。 次に、ここで分かった性能の差を埋めることができないかということで、multi-taskとfine-tuningの様々な組み合わせ方について検証していきます。 ここで比較する手法は、通常の事前学習+fine-tuningとMulti-task含めて5つあります。
Unsupervised pretrining + fine-tuning
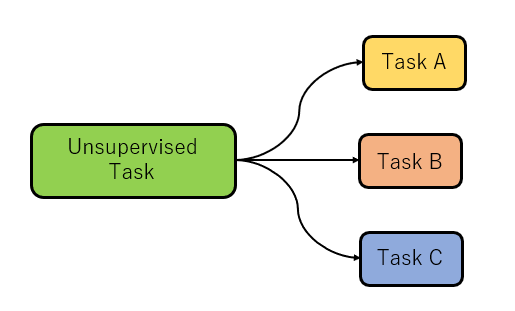
Multi-task
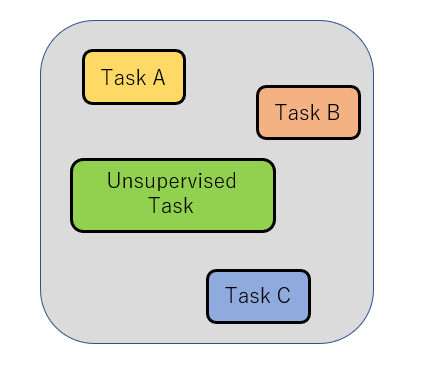
Multi-task pre-training + fine-tuning:すべてのタスクを事前学習させる方法
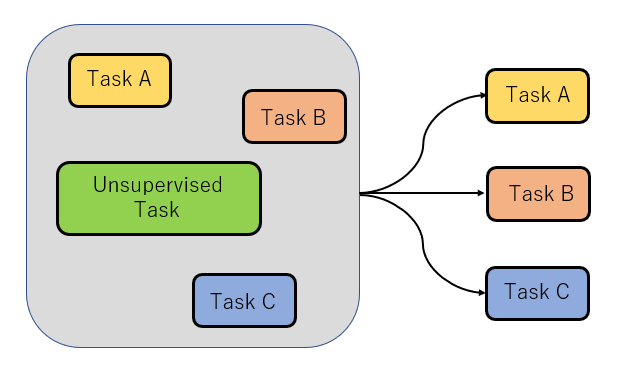
Leave-one-out multi-task training:1つのデータを除いたもので事前学習を行い除いたタスクでの性能を図る方法
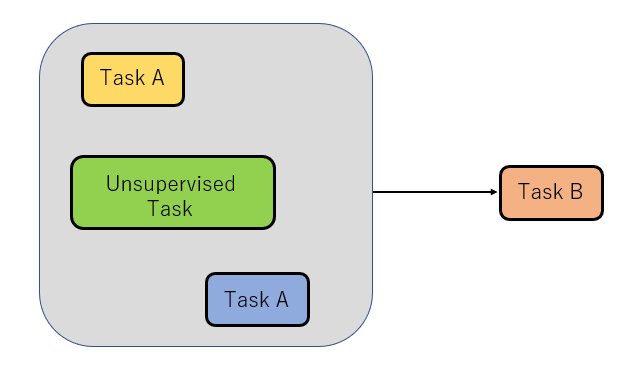
Supervised multi-task pre-training:教師あり学習のみを事前学習させる方法
 結果をみると、Multi-task pre-training + fine-tuningによって性能の差を埋めることは出来ました。また、Leave-one-out multi-task training性能がそこまで下がっていないことから、様々なタスクに対して事前学習+fine-tuningをすると新しいタスクに対して、ある程度対応できる可能性を示しています。そして、Supervised multi-task pre-trainingの結果を見ると、翻訳のタスクのみ良い性能を示していることから、教師なし学習による事前学習は、それ以外のタスクに重要な影響を与えていることが分かります。
結果をみると、Multi-task pre-training + fine-tuningによって性能の差を埋めることは出来ました。また、Leave-one-out multi-task training性能がそこまで下がっていないことから、様々なタスクに対して事前学習+fine-tuningをすると新しいタスクに対して、ある程度対応できる可能性を示しています。そして、Supervised multi-task pre-trainingの結果を見ると、翻訳のタスクのみ良い性能を示していることから、教師なし学習による事前学習は、それ以外のタスクに重要な影響を与えていることが分かります。
Scaling
最後に、学習ステップ数・バッチサイズ・モデルの大きさ・アンサンブルについて比較を行っています。
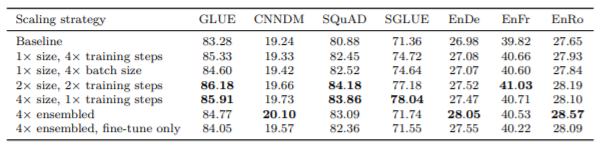 結果を見ると、ベースラインと比較して、それぞれ大きくすることで精度が良くなっていることが分かります。予想できた結果ですが、より大きなモデルを使って、学習もそれなりに行ったほうが良いことが確認できます。
結果を見ると、ベースラインと比較して、それぞれ大きくすることで精度が良くなっていることが分かります。予想できた結果ですが、より大きなモデルを使って、学習もそれなりに行ったほうが良いことが確認できます。
実験のまとめ
最後に、以上の実験から得た結果を反映したモデルの性能を、様々なベンチマークで検証した結果を見てみます。
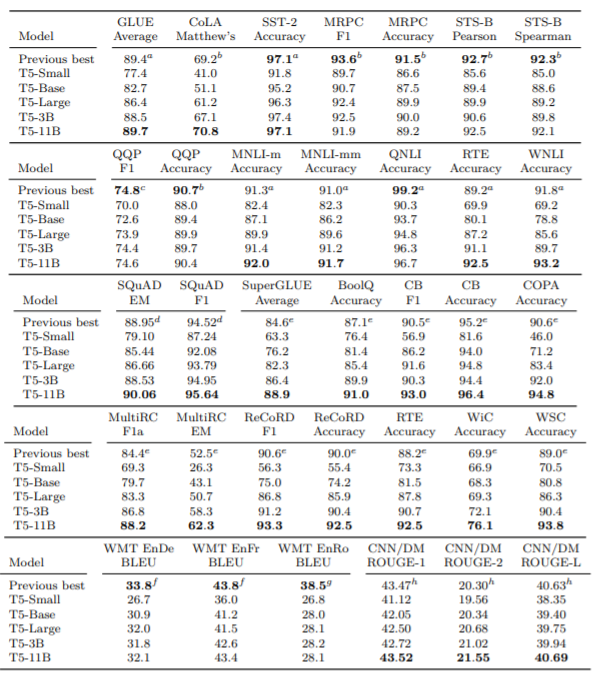 それぞれのモデルのパラメータ数はこちらです。
それぞれのモデルのパラメータ数はこちらです。
- T5-Base : 220million
- T5-small : 60million
- T5-Large : 770million
- T5-3B : 2.8billion
- T5-11B : 11billion
今までの検証からも予想できるように、パラメータ数の多いもののほうが性能が良くなっています。また、様々なベンチマークでSoTAを獲得できていることから、検証して得た結果は正しかったことが分かります。ただし、翻訳タスクに関しては、事前学習に英語のみのデータセットを使ったために、これまでのSoTAには届いていないようです。
それぞれのベンチマークによる考察は長くなるので省きますが、興味があれば是非論文を読んでみてください。
まとめ
今回はT5の論文について紹介しました。T5モデルのポイントはText-to-Textの形式を採用したこととC4というかなり大きなデータセットを使ったことですが、NLP分野は研究が盛んで次々に新たなモデルが発表されているので、整理するという意味でも、こののように検証を行っていくことも今後重要になってくると思います。
参考文献
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- T5①(論文のAbstractの確認)|言語処理へのDeepLearningの導入の研究トレンドを俯瞰する #26
- T5(Text-toText Transfer Transformer)②(Introductionの確認)|言語処理へのDeepLearningの導入の研究トレンドを俯瞰する #27
- T5(Text-toText Transfer Transformer)③(Section2_Setup)|言語処理へのDeepLearningの導入の研究トレンドを俯瞰する #28
- T5(Text-toText Transfer Transformer)④(Section3_Experiments)|言語処理へのDeepLearningの導入の研究トレンドを俯瞰する #29
- T5(Text-toText Transfer Transformer)⑤(Section4_Reflection)|言語処理へのDeepLearningの導入の研究トレンドを俯瞰する #30
- T5(Text-to-Text Transfer Transformer)について少し説明してみる
- Colin Raffel: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
関連記事

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)

概要 今回は、以前ブログで紹介したText-to-Text Transfer Transformer(T5)から派生したWT5(Why? T5)を紹介します。 Text-to-Text Transfer Transformerとは、NLP(自然言語処理)のタスクをtext-to-text(テキストを入力して、テキストを出力する)形式として考えたもので、様々なタスクでSoTA(State of the Art=最高水準)を獲得しました。こちらの記事で詳し

フェイクニュースは珍しいものではありません。 コロナウイルスの情報が凄まじい速さで拡散されていますが、その中にもフェイクニュースは混ざっています。悪意により操作された情報、過大表現された情報、ネガティブに偏って作成された情報は身近にも存在しています。 これらによって、私たちは不必要な不安を感じ、コロナ疲れ・コロナ鬱などという言葉も出現しました。 TwitterやInstagramなどのソーシャルメディアでは嘘みたいな衝撃的なニュースはさらに誇張な表現で拡散

最近はGoogleを始めとする翻訳サービスにも機械学習が取り入れられ、翻訳精度が向上しています。 しかし、完璧な翻訳を求めるには精度が足りず、確認作業に時間がかかったり、翻訳されたものが正しいのか見極めるスキルが必要なケースがほとんどです。 このような課題がある中、高精度な翻訳ができる「DeepL」が、日本語と中国語の翻訳に新しく対応したので、日本語での翻訳機能を試してみました。 DeepLとは DeepLはドイツのケルンで開発された深層学習(ディープラー