DEVELOPER’s BLOG
技術ブログ
機械翻訳の歴史と今後の可能性

目次
- 機械翻訳とは
- 機械翻訳の手法
- 現在の機械翻訳の欠点
- 欠点が改善されると
- 今後の展望
機械翻訳とは
機械翻訳という言葉を理解するために2つ言葉を定義する。
系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。
系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。
この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)に変換する方法論の総称のことをいう。例えば、日本語の文章という系列を英語の文章という別の系列に変えることである。特に、系列変換モデルの考えを使った機械翻訳をニューラル機械翻訳と呼ぶことがある。
機械翻訳の手法
歴史的には、以下のような翻訳方法がある。
ルールベース翻訳
登録済みのルールを適応することで原文を分析し、訳文を出力する機械翻訳の方法。ここでいう「ルール」は、各言語の「文法」に置き換えられる。定めたルールに則っていなければ翻訳ができないが、則ってさえいればしっかりと翻訳可能である。現在は、旧時代的な機械翻訳方法として認識されている。
ルールに基づく機械翻訳の基本になるのはルールである。ルールによる構文解析の仕組みを、ツリーによる機械翻訳の例を挙げる。
まず以下のルール
NP → ART N (名詞句 は 冠詞 名詞 で構成される)
VP → V NP (動詞句 は 動詞 名詞句 で構成される)
S → NP VP (文 は 名詞句 動詞句 で構成される)
を使って以下の英文を解析してみる。
A client sent the form
ルールベース機械翻訳では、辞書もルールとして扱う。理論を考える場合だけでなく、実用的な機械翻訳システムを設計する場合にも辞書をルールとして扱うほうが良いとされている。ここでは、辞書として以下のルールも用意する。
ART → a (冠詞 は a で構成される)
ART → the (冠詞 は the で構成される)
N → client (名詞 は client で構成される)
N → form (名詞 は form で構成される)
V → sent (動詞 は sent で構成される)
まず、原文にある単語それぞれの品詞を判定する。
ART - a
N - client
V - sent
ART - the
N - form
次に、当てはまるルールを探して順次適用する。左端のARTとNに
NP → ART N (名詞句 は 冠詞 名詞 で構成される)
が当てはまるため、左端のARTとNからNPを作れる。
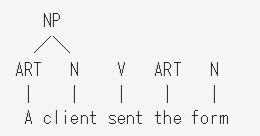
同様に、右端のARTとNからもNPを作れる。
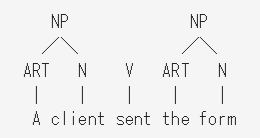
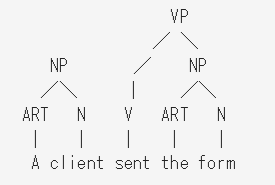
次に、
VP → V NP (動詞句 は 動詞 名詞句 で構成される)
を当てはめることができ、VとNPからVPを作れる。
最後に以下のルール
S → NP VP (文 は 名詞句 動詞句 で構成される)
が当てはまるため、NPとVPからSを作れる。
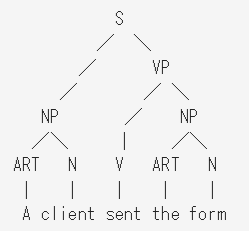
これ以上適用できるルールはなく、最終的な目標としていた文 (S) を検出できたので、これで解析成功である。最終的に、原文の構造を表すツリーを作ることができる。
用例ベース翻訳
入力文の各部分に対して類似した用例を選択し、それを組み合わせて翻訳を行う。
この方法はほかの方法よりも自然な翻訳文の生成が可能であると考えられている。理由としては、人間も翻訳する際に様々な用例から翻訳をしているからである。また、用例の追加により容易にシ ステムを改善可能である。
しかし、用例ベース翻訳は入力文や用例を解析するのに高精度なものを必要としているが、十分な精度をもつものが存在しなく、用例ベース翻訳は実現されていなかった。現在は木構造により用例ベース翻訳は研究されている。
原文を解析して木構造を作り、その木を置き換えながら翻訳する。
下図のように木構造を作る。
原文: OK button sends the form to the remote server.
訳文: [OK] ボタンはフォームをリモート サーバに送信する。
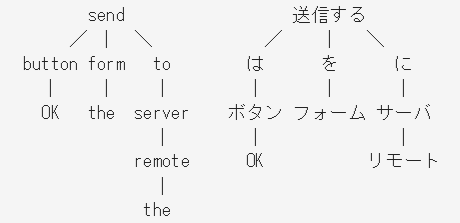
このようにして、様々な用例パターンを抽出している。この方法は、日本発祥である。
必ずしも文法に従って原文を解析する必要はないが、ツリー構造を使うと柔軟な翻訳が可能である。
この方法の長所は先ほどのルールベース翻訳のように膨大な量のルールを機械に覚えさせる必要がない点である。
統計翻訳
コンピュータに学習用のコーパスを与え、統計モデ ルを学習させることで訳文を出力させる方法。ルールベース機械翻訳の弱点をカバーするとして、注目された方法である。
具体的には、対訳コーパスという、例えば日本語でよくある言い回し
0001
日: Xではないかとつくづく疑問に思う
英: I often wonder if it might be X.
中: 难道不会是X吗,我实在是感到怀疑。
1000
日: 私はXを視野にしっかり入れています
英: I put more focus on X.
中: 我非常重视X。
2000
日: 彼がレストランで昼食をとる
英: He eats lunch at a restaurant.
中: 他在餐馆吃午饭。
を英語や中国語に翻訳した大量のコーパスから学習をし、評価対象の文を翻訳する方法である。
統計翻訳において統計的モデルを学習するアルゴリズムは、言語に依存しないため、大量の対訳データがあれば多言語化が容易であり、開発コストを抑えることが可能である。
現在の機械翻訳の欠点
系列変換モデルに基づくニューラル翻訳システムの弱点の1つに、語彙数の問題がある。扱う語彙数を多くすると計算量が大きくなりすぎて現実的な速度での学習や評価ができなくなる。
また、語彙数が多くなるということは、語彙選択問題がより難しくなるため、不用意に語彙を増やしても翻訳精度が低下するだけということも起こる。
さらに、イベント名など時間とともに新語が出現するので、本質的に未知語を完全になくすことは不可能である。機械翻訳タスクでは未知語をどのように扱うかは永遠のテーマとなっている。
統計翻訳時代の考え方から、未知語と判定されたものを後処理で何かの語に置き換えるという方法が用いられている。いくつかの論文の実験セクションでは「RnkRep」のような用語を使ってその結果を示して いる。
一方、ニューラル翻訳に移行してからは、新しい考え方も使われるようになった。
1つは、入出力の単位を「単語」ではなく「文字」にしてしまう方法である。「文字」であれば使われる文字集合は事前に網羅できかつ、新語に比べて新文字の出現は限りなく低いことから、増えることはないという仮定ができる。一方、個々の文字選択問題が簡単になっても、系列長は単語の時と比べて圧倒的に長くなるので、そちらで予測誤りが多くなる問題が発生する。
次に、文字単位はあまりにも細かすぎるという考え方から、文字単位と単語単位の丁度中間に相当する方法論として、バイト対符号化という方法も提案されている。この方法はニューラル翻訳を行う前処理とし て、与えられたデータを使い出現頻度が最も大きい文字ペアを1つの文字としてまとめるという処理を事前に決めた語彙数まで繰り返し処理する。これで得られた文字の結合ルールは、未知の文に対しても、得られた順番で適用していけば、必ず一意に同じ符号化された文を獲得するこ とができる。
文字単位、単語単位、バイト対符号化の 3 種類のうち、どれが総合的に優れているかは決着がついていないが、最近はバイト対符号化が良いのではないかということが言われている。
欠点が改善されると...
未知語に関しての欠点が改善されると、扱う語彙数をうまくコントロールした翻訳が可能になる。
扱い語彙数が多くなると計算量が多くなるため、現実的な速度で計算が不可能であったが、語彙数をうまくコントロールし翻訳をすれば、計算速度が速く、語彙選択問題も簡単になることから高精度に翻訳が可能であると考えられる。
さらに、翻訳をするために高性能なコンピューターを必要としていたが、計算量を減らすことで、安価なコンピューターを用いても高性能な翻訳が可能になるだろう。
今後の展望
機械翻訳タスクは、現在の自然言語処理分野の深層学習/ニューラルネットワーク研究の中心的な位置を占めていると考えられている。
多くの研究成果が報告されており、どの技術が最終的に生き残るか現状見極めるのが難しい。しかし、2015年、2016年で、系列変換モデルによるニューラル翻訳の基礎的な理論が出来上がり、統計翻訳よりも有意に良いと認められるに至っている。研究の余地は非常に多く残されている研究領域であり、独自技術を開発する必要があると考えられている。
機械翻訳がさらに発展すると以下のことが実現するだろう。
コストを抑えてスピーディーな翻訳が可能
機械翻訳の最大のメリットとして、よりスピーディーに、コストを抑えた翻訳が可能になったという点が挙げられる。翻訳速度が速い翻訳家に依頼しても、英文の日本語訳の場合、1日1500〜2000語が目安といわれている。しかし、人間が8時間かけて翻訳する作業を、Google翻訳は数十秒足らずで処理してしまう。さらに、翻訳家に翻訳サービスを依頼すると、一文字5円の場合、2000文字の英文の翻訳に10,000円かかるのに対し、Google翻訳なら、100を超える言語を無料で翻訳が可能である。
翻訳結果を文書として残せる
ビジネスの世界では、文書の配布や、保管、管理を行うために記録として残す必要があり、正確さも求められる。こうした場合、文書から別の言語の文書に翻訳できる機械翻訳が適している。ポストエディットという言葉があるが、これは機械翻訳を利用した後に行われる人間の翻訳者による修正作業のことである。機械翻訳が発展したらポストエディットの作業も徐々に減っていくと考えられ、人間が行う作業を効率的に減らすことが可能である。
参考文献
深層学習による自然言語処理 坪井祐太/海野裕也/鈴木 潤・著
ニューラル機械翻訳以前を支えた「ルールベース機械翻訳(RMT)」と「統計的機械翻訳(SMT)」
ルールベース機械翻訳の概要 (4)
用例ベース機械翻訳の概要 (1)
機械翻訳と自動翻訳に違いはある?使い分けはどうすればよい?
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数