DEVELOPER’s BLOG
技術ブログ
自然言語処理の歴史的背景を紹介! さらなる実用化に向けて

はじめに
最近のAIは音声認識や翻訳においては高い精度を出すことができます。
例えばAIが英語から日本語に翻訳する時、私達日本人が読んで多少の違和感があったりもしますが英文がどんなことを言っているのか理解することはできます。
もしも機械が言語を理解して、人間と違和感なく会話できたらどうでしょう。そのようなことが可能になると、機械がどのようにして言語を理解したかを見ることによって、人間には気づくことができなかった新たな言語に関する発見ができるかもしれません。
さらには私達が子供の頃、お母さんなどの周りの言葉を聞いて徐々に話すようになり言葉を理解し始めました。これがどのようなメカニズムで理解されているか発見できるかもしれません。また、極論を言えば人間が機械に言語理解を任せれば良いので人間は時間をかけて言語を勉強する必要もなくなるかもしれません。このブログでは機械が言語を理解するための学問に関して簡単に書きます。
目次
はじめに
機械が言語を理解するためには
自然言語処理とは
自然言語処理でできること
まとめ
機械が言語を理解するためには
機械が言語を理解するということは機械がただ翻訳できればよいというわけでわありません。機械が文から人間がどのようなことを伝えたいか理解するためにはどのような壁があるでしょう。
人間が話したり書いたりした文章から意味を理解する
意味を理解したら人間が必要としてる回答を見つける
回答を見つけたら人間にわかるように伝える
などなど...
上記で挙げたものは全て難しいです。このような壁を乗り越えるためにどうすればよいでしょう。そこで登場するのが自然言語処理です。
自然言語処理とは
自然言語処理とは、先程箇条書きであげた壁を乗り越えるための学問で機械に言語を理解させることを目標にしています。自然言語というのは人工言語(人工的に作られた言語、プログラミング言語)と対比させた言い方で人間が普段使っている言語のことです。
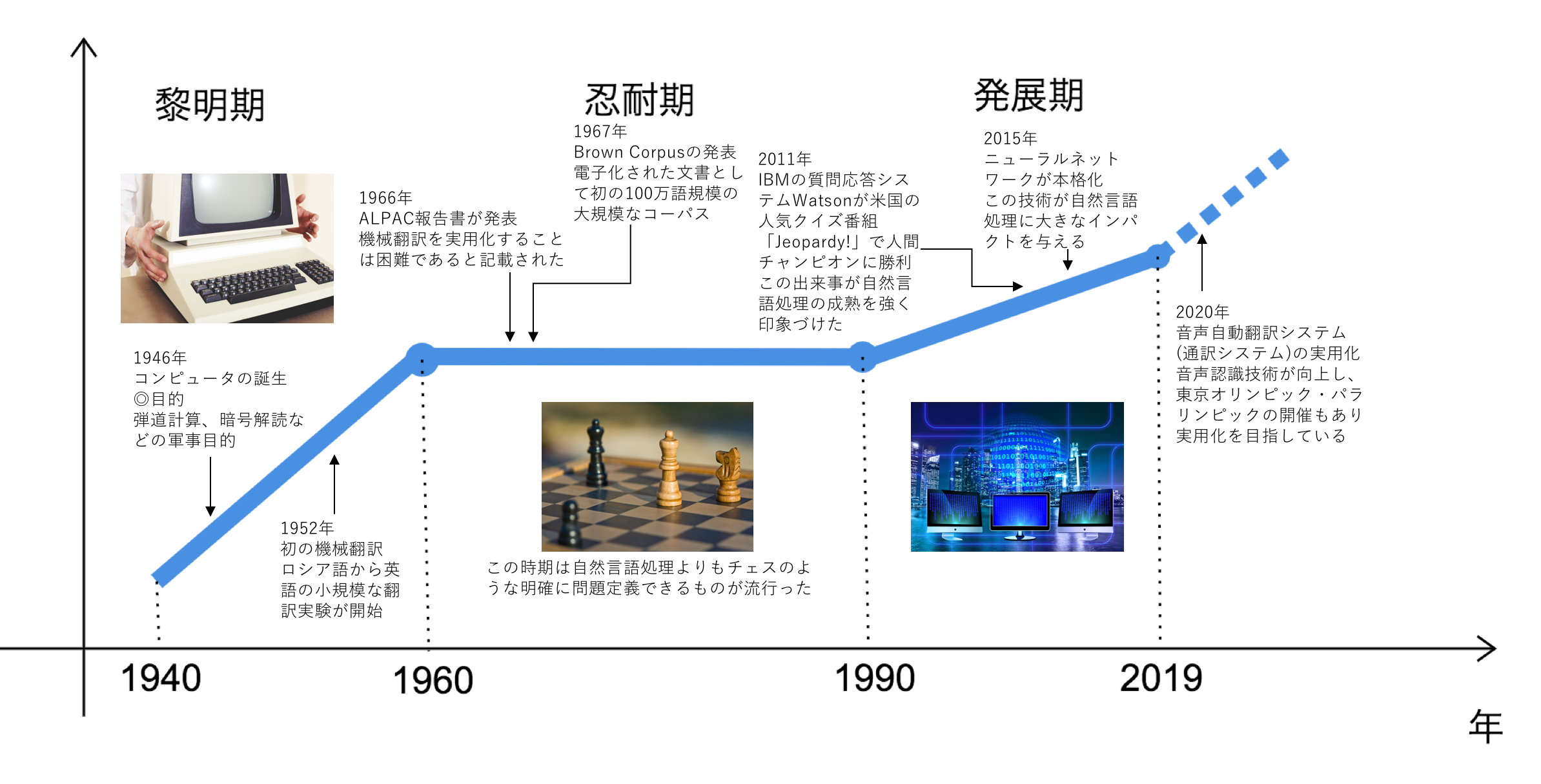
簡単に自然言語処理の歴史を説明します。
1940〜1960年ごろは黎明期と呼ばれ1946年に初めてコンピュータが誕生しました。当初の目的は、弾道計算や暗号解読などの軍事目的でした。このコンピュータが翻訳にも使えるのではないかとロックフェーラー財団のウィーバーが考えました。この考えをきっかけに米国内で機械翻訳への関心が高まり1952年ジョージタウン大学とIBMが共同で翻訳プロジェクトを立ち上げロシア語から英語への小規模な翻訳実験が始まりました。これが自然言語処理の始まりです。
その後、米国はソ連の科学技術の実態を知るべくロシア語から英語の翻訳に関する研究に関して多額の研究予算を投入しました。これにより機械翻訳は進展していきました。この時代は、コンピュータの処理能力が十分でなかったことも関係し研究者が自由な発想で夢を膨らましていたそうです。

1960〜1990年頃は忍耐期と呼ばれ莫大な研究費をかけましたが、研究が進展するに連れ、問題の難しさが認識されるような状況になりました。
1966年には機械翻訳の現状と将来に関する調査結果をALPAC報告書と呼ばれる報告書にまとめ、そこには近い将来に機械翻訳をすることは困難であり、言語の理解を目指す基礎的な研究を行うべきである、という内容のものでした。この報告書を機に、米国では機械翻訳においてほとんど研究費が出なくなりました。
更にこの頃は、自然言語処理の研究の難しさが明確になり、チェスのような明確に定義された問題における探索などに興味の中心が移っていきました。
この頃の自然言語処理に関する重要な出来事といえば1967年のBrown Corpusの発表です。
これは米国の言語の使用を調査する目的で、電子化された文書として初の100万語規模のコーパス(簡単に言えばテキスト文書の集合にある種の情報を付与したものです)で、新聞、雑誌、書籍など様々なジャンルのテキストをバランスよく収集したものを発表しました。1970年頃からコンピュータの処理能力が向上し言語やテキストを扱う基本的な環境が整い出しました。しかし、機械翻訳に代表される知的処理についてはまだ実用には精度が足りない状況でした。

1990年頃から現在までは発展期と呼ばれ、この頃はインターネットが世界的に普及し、社会基盤になった時期です。Brown Corpusの経験に学び各地で数億語規模のコーパスが作られました。1993年にはBrown Corpusのテキストに解釈を与えたPenn Treebankが最初の論文として発表されました。これは今後の機械学習に基づく自然言語処理研究を牽引したデータになりました。機械翻訳においても1980年代後半から統計的機械翻訳の研究を行いました。しかし、当時のコンピュータの処理能力や対訳コーパスの不足により十分に研究は発展しませんでした。
ところが、1990年代後半あたりから計算環境や対訳コーパス環境が整い、米国が機械翻訳によって紛争地域の素早い情報収集をするなどの目的から再度、多額の研究費を出すようになったこともあり、2000年以降、機械翻訳研究の大きな進展が見られました。またこの頃は、音声自動翻訳システムいわゆる通訳システムの研究も始められました。日本では東京オリンピック・パラリンピックが開催される2020年を目標に実用システムの開発を目指しています。このような自然言語処理の発展を強く印象づける出来事として2011年、Watsonが米国の人気クイズ番組「Jeopardy!」で人間チャンピオンに勝利しました。Watsonは約3000個のCPUからなる並列コンピュータによって、自然言語による質問を理解し、ウィキペディアなどの大量の情報の中から適切な回答を選択するシステムでした。更に、自然言語処理に大きな技術革新として2015年頃から本格化し始めたニューラルネットワークです。ニューラルネットワーク自体は1940年代に提案されていましたが当時のマシンパワーでは計算力が足りず難しい状況でした。
2000年代に入り、マシンパワーの増大、ビックデータの利用、アルゴリズムの改良などから再び注目されました。2010年代に入り画像認識、音声認識などの様々なタスクで大きな精度向上が見られるようになりました。特に、ニューラルネットワークを用いた翻訳手法、ニューラル機械翻訳は大きな精度向上をもたらし、機械翻訳を一気に実用レベルの技術に押し上げました。

自然言語処理の現状としてDeepLearningの登場もあり、文章を単語単位に分割し単語がどのように並んでいるかパターンを捉えることや、似ている単語を把握する事ができます。これに関しては実用化もされていて有名なものだと新聞記事の単語の関係性などを機械が学習し記事の重要な部分を抜き出してまとめてくれる要約サービスがあります。しかし、機械が言語を理解することはDeepLearningを用いた最新モデルとされているBERT(バート)でさえ実現することはできませんでした。機械が言語を理解するにはまだまだ研究段階であり時間を必要としているのが現状です。
自然言語処理でできること
自然言語処理でできることを今回は3つ紹介します。
コールセンターの対応を自動化
コールセンターの業務はマニュアル通りに電話応対をし人間がマニュアルを参照し適切な回答を選択しています。マニュアルで対応できない質問に対しては後日回答や担当の者に電話をつなげるなどの対処が必要です。自然言語処理を用いれば今まで人がマニュアル通りに応対していたところを、機械で実現できます。音声認識により機械が質問を理解し、自然言語処理を用いて質問にあった適切な回答を選択します。
教育現場において生徒のSNSを分析しいじめ発見
SNS分析をする際も自然言語処理は有効です。自然言語処理の中の文書分類を用い、SNSに書き込まれた文章に対してこの文章はいじめに関係しそうな単語がどの程度含まれているか確率的に分析し、その確率が高いときはいじめに関係している文章とし、生徒のいじめ早期発見につなげます。
コンビニやスーパーでアンケートを自動で分類するシステム
コンビニやスーパー等においてアンケートを自動で分類する際もクラスタリングを用いることで可能です。大量のアンケートから項目ごとに似た回答をしているものをグループ化し、アンケートの分類を自動化する事が可能です。具体的な手法としてはK-means方というのがあり詳しくはこちらを参考にして下さい。
まとめ
最近の話題だと、東ロボくんというロボットが東大に入れるかというプロジェクトがあります。これは、機械が言語を理解できたら確実に合格できると言われています。あくまで想像ですが、入学後も常に成績トップで人間には到底かなわない存在になってしまうかもしれません。
それほど自然言語処理という学問はかなり難しいとされています。難しい分、研究が進み機械が言語を理解したら私達の常識が変わったり、人間の言語に対する理解が深まり様々な場面で応用できることが期待されており、私達はその難問に挑戦します。
参考文献
チャットボットAIの現状を解説!自然言語処理は今なにができるの?
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 機械翻訳とは 機械翻訳の手法 現在の機械翻訳の欠点 欠点が改善されると 今後の展望 機械翻訳とは 機械翻訳という言葉を理解するために2つ言葉を定義する。 系列 : 記号の列のことで自然言語処理の世界だと文を構成する単語の列になる。 系列変換モデル : 系列を受け取り、それを別の系列に変換する際の確率をモデル化したもの。系列変換モデルはseq2-seqモデルとも呼ばれている。 この2つの言葉から機械翻訳は、ある言語の文章(系列)を別の言語の文章(系列)

概要 今回は、以前ブログで紹介したText-to-Text Transfer Transformer(T5)から派生したWT5(Why? T5)を紹介します。 Text-to-Text Transfer Transformerとは、NLP(自然言語処理)のタスクをtext-to-text(テキストを入力して、テキストを出力する)形式として考えたもので、様々なタスクでSoTA(State of the Art=最高水準)を獲得しました。こちらの記事で詳し

フェイクニュースは珍しいものではありません。 コロナウイルスの情報が凄まじい速さで拡散されていますが、その中にもフェイクニュースは混ざっています。悪意により操作された情報、過大表現された情報、ネガティブに偏って作成された情報は身近にも存在しています。 これらによって、私たちは不必要な不安を感じ、コロナ疲れ・コロナ鬱などという言葉も出現しました。 TwitterやInstagramなどのソーシャルメディアでは嘘みたいな衝撃的なニュースはさらに誇張な表現で拡散

Googleが発表したBERTは記憶にも新しく、その高度な性能はTransformerを使ったことで実現されました。 TransformerとBERTが発表される以前の自然言語処理モデルでは、時系列データを処理するRNNとその発展形であるLSTMが使われてきました。このLSTMには、構造が複雑になってしまうという欠点がありました。こうしたなか、2017年6月に発表された論文「Attention is all you need」で論じられた言語モデルTran