DEVELOPER’s BLOG
技術ブログ
【論文】"Reformer: The Efficient Transformer"の解説

概要
小説を丸ごと理解できるAIとしてReformerモデルが発表され話題になっています。今回はこのReforerモデルが発表された論文の解説を行います。
自然言語や音楽、動画などのSequentialデータを理解するには広範囲における文脈の依存関係を理解する必要があり困難なタスクです。"Attention is all you need"の論文で紹介されたTransformerモデルは広くこれらの分野で用いられ、優秀な結果を出しています。
例えば機械翻訳などで有名なBERTはTransferモデルが基になっており、数千語にも及ぶコンテキストウィンドウが使われLSTMに比べて長い文脈を考慮することができます。しかし、このようにモデルの規模が大きくなってくるとリソースの問題が発生し、大きな研究機関以外はモデルの訓練が行えない状況です。
ReformerはTransferを改良し軽量化することで、1つのアクセラレータ、16GBのメモリで100万ワードに及ぶ文章を扱えるようにしました。
この記事ではTransformerモデルがどう改善されたかを解説していきますので、Transformerモデル自体の解説については過去の記事を参考にして下さい。
【論文】"Attention is all you need"の解説
大規模なTransformerモデルが抱える問題
まずは従来のTransformerモデルを大規模化したときにどういった問題が起こるか説明します。
Attentionの問題
Transformerモデル内のAttentionの計算にはscaled dot-product attentionが使われています。
$$ \rm{Attention}(Q, K, V) = \rm{softmax}(\frac{QK^T}{\sqrt{d_k}})V $$
トークンの長さを\(L\)とすると内積\(QK^T\)は計算量、メモリ量ともに\(O(L^2)\)となります。
例えば、\(Q\)、\(K\)、\(V\)のサイズがすべて\([batch\_size, length, d_k]\)だと仮定すると、トークンの長さが64Kの場合バッチサイズが1だったとしても
$$ 64\rm{K} \times 64\rm{K} \times 32 \rm{bit} \ \rm{float} \approx 16 GB $$
とメモリ消費が激しくなります。
このように小説のような非常に長い文章をTransformerで扱いたい場合に、Attention層で必要な計算量、メモリ量が問題になります。
Activationを保持しておくためのメモリ量の問題
もう1つの問題が逆伝播に必要な各層のActivationを保持しておくためのメモリ量の問題です。
まずTransformerモデル全体で32-bit floatのパラメータ数0.5B (Billion) を保持するのに約2GB必要です。
これに加えてトークンの長さが64KでEmbeddingのサイズが1024、バッチサイズが8とすると
となるので、1つの層についてActivationを保持するためにさらに2GMのメモリが必要になります。
典型的なTransformerモデルが12個以上の層を持つので、Activationを保持しておくだけで24GB以上必要になります。
このようにモデルに与える文章が長くなるとすぐにメモリを使い果たしてしまいます。
Attentionの計算を効率化 (LSH Attention)
内積\(QK^T\)の処理が問題ですが、結局のところ知りたいのは\(softmax(QK^T)\)の結果です。
softmaxの結果は内積の値が大きい要素に寄与するため、queryとkeyの内積が大きくなるペアの計算結果だけを用いて近似値を求めることができます。つまりqueryとkeyのすべてのペアについて内積を計算するのではなく、queryに対して類似したkeyだけを考慮すればよいので処理が効率化されます。
このとき、queryと類似したkeyを選ぶのにLSHを使います。詳しい解説はここでは避けますが、LSHは高次元のデータを確立的処理によって次元圧縮する手法です。Reformerではハッシュ値の計算は次のようにして求めます。
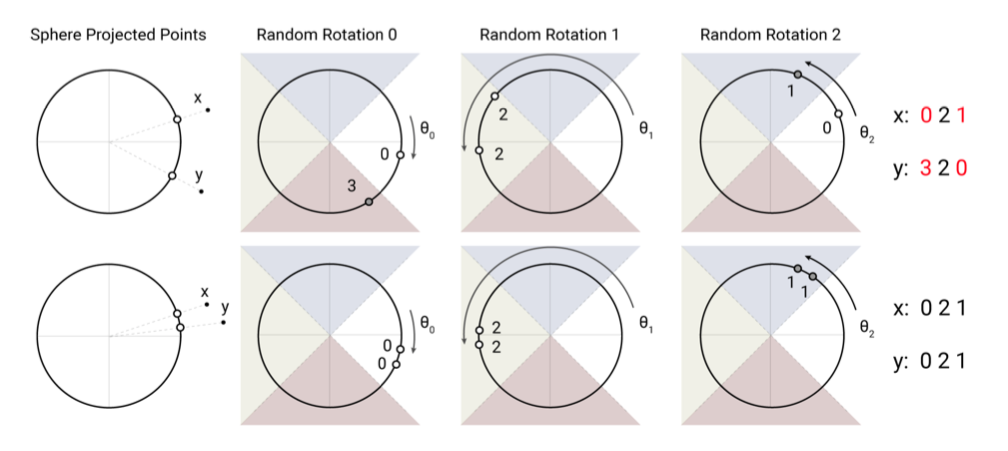
以下の画像で示すようにベクトルをランダムに回転させてどの領域に移るかによってどのバケットに入れるかを決定します。画像内の上の例ではRandom Rotation 1 以外、xとyの移る先が異なるためそれぞれ違うバケットに入ります。一方で下の例では、xとyが3回の回転ですべて同じ領域に移るため同じバケットに入ります。
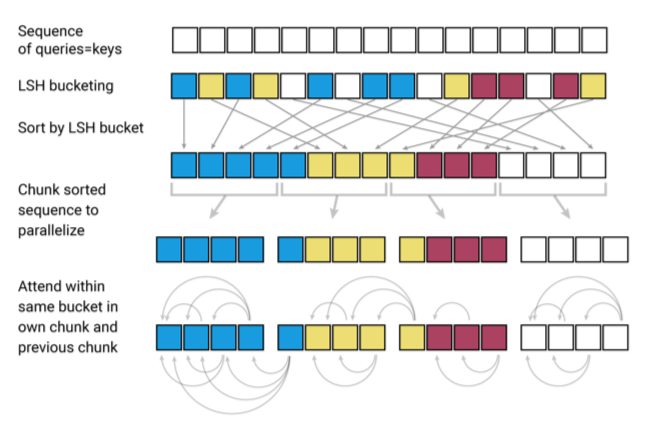
次にLSHを利用してどのようにAttentionの計算を効率化するか具体的なステップを以下の図とともに説明します。図中の色はどのハッシュに割り当てられたかを示しており、似た単語は同じ色で表されます。
まずLSHによってハッシュを割り当てて、ハッシュ値によって単語を並べ替えます。並べ替えた後、小さな塊に分割することで並列処理を可能にします。そしてAttentionの処理を同じ塊の中および1つ前の塊に対して行うため大幅な計算不可の軽減ができます。
LSH Attentionの計算を式で表すと
\(i\) はQの\(i\)番目の要素を表しており、\(\mathcal{P}_i\)はi番目のqueryに近いkeyの集合を表しています。また、\(\mathcal{z}\)はsoftmaxの分母の部分だと考えて下さい。
これらの処理により、計算量を\(O(n^2)\)から\(O(n\log n)\)まで削減することができます。これでAttentionの問題を解決することができました。
Activationを保持しておくためのメモリ量の削減 (Reversible Transformer)
Attentionの問題は解決されましたが、学習時に逆伝播のためにActivationを保持しておかなければならずメモリ消費が大きくなる問題が残っています。Reformerではこの問題を解決するために順伝播時にActivationをメモリ内に保持しておくのではなく、逆伝播時に再計算する方法を取りました。
この方法を実現させるためにGomez et al. (2017)で示されたReversible Residual Network (RevNet)を応用します。RevNetでは出力側から順次1つ先の層の結果を元にActivationを再計算します。
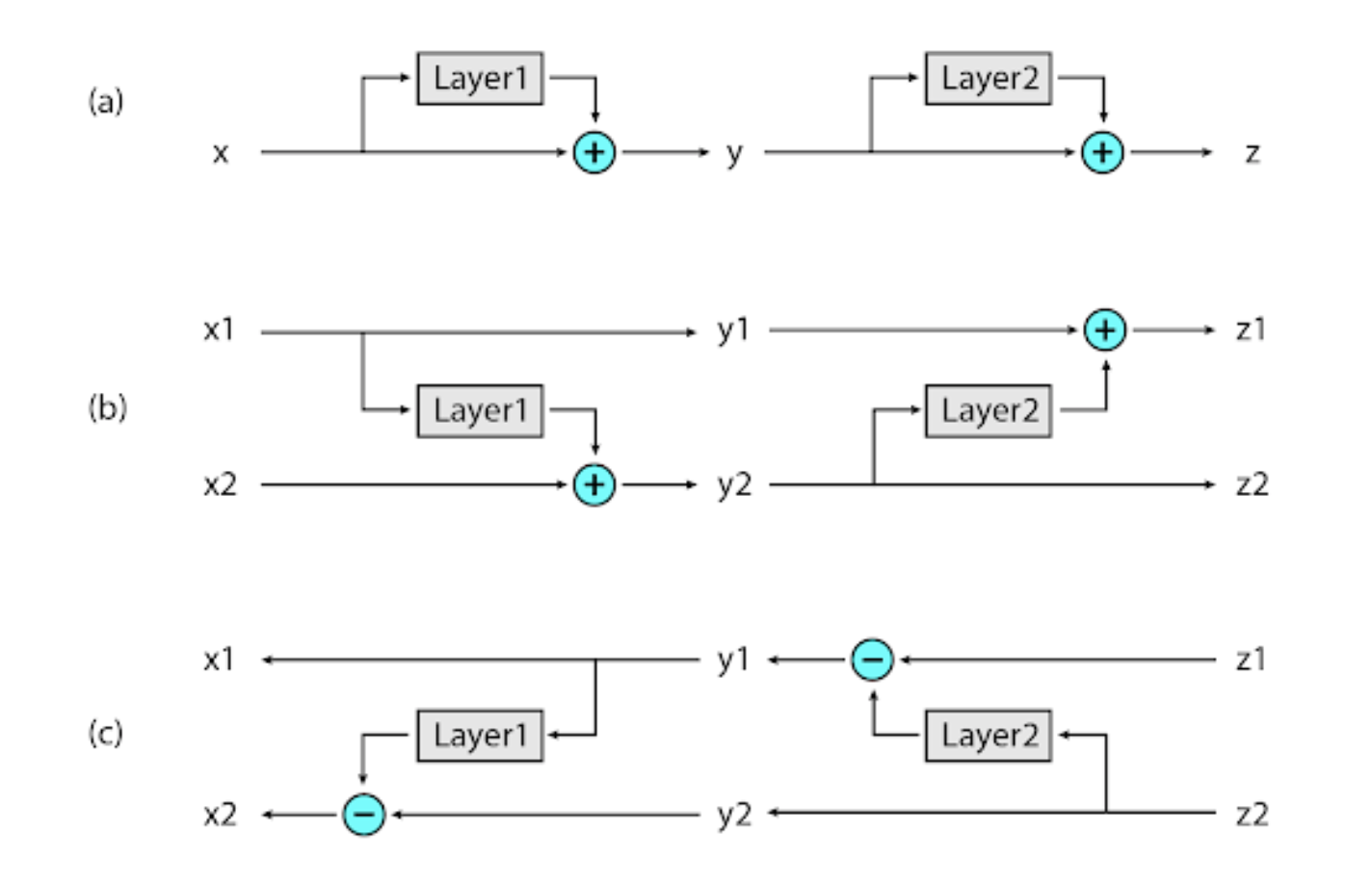
通常のネットワークでは(a)のようにベクトルが通過するスタックに各層が追加されていきます。一方でRevNetでは各層において2つのActivaltionを持ちます。そして(b)のようにそのうち1つだけが通常のネットワークと同じように更新されます。もう1つのActivationは(c)のようにもう一方のActivationとの差分を捉えるために使われます。
これにより順伝播時にActivationを保持する必要がなくなり、逆伝播時に出力側から順次再計算することでActivationを再現することができます。これでActivationを保持するためのメモリを削減することができました。
実験
最後にReformerのパフォーマンスを見てみましょう。実験には以下の入力のサイズが非常に大きいタスクに対して行われました。
- enwik (テキストタスク) - 入力トークンの長さ64K
- imagenet64 (画像生成タスク) - 入力トークンの長さ12K
まず、Reversible Transformerと通常のTransformerの性能を比べてみましょう。
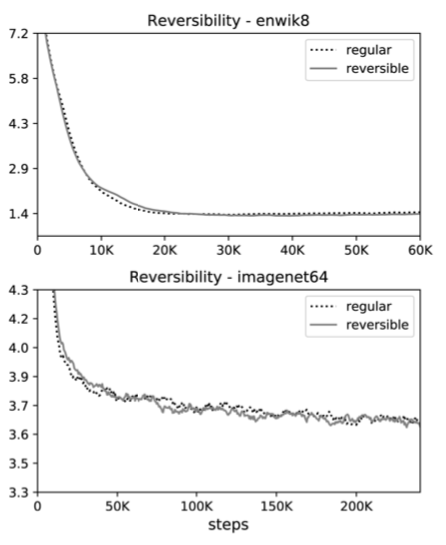
グラフを見て分かるようにテキストと画像どちらのタスクにおいてもReversible Transformerが通常のTransformerとほぼ等しい性能を見せました。
Reversible Transformerによってメモリ消費を抑えても性能が犠牲になることはないとわかります。
次にLSH AttentionがTransformerの性能にどう影響するかみていきましょう。
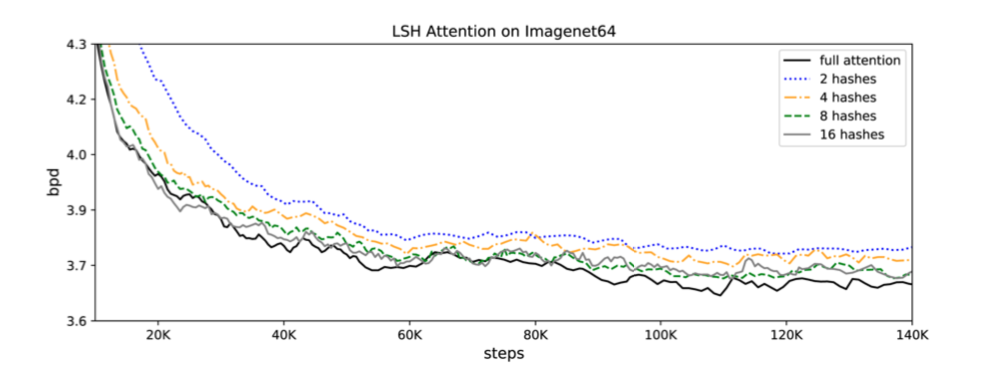
次のグラフはfull attention (通常のAttention)とLSH Attentionとの比較です。グラフ中のn hashesはLSHでのハッシュの割り当て処理を何回行うか示しています。割り当てを複数回行った後、それぞれのラウンドでqueryと同じバケットに入ったすべてのkeyをAttentionの計算に利用します。なぜこのようなことをするかというと、LSHでは確率的にハッシュを割り当てるので、確率は低いですが類似した要素がちがうバケットに入る可能性があるからです。
グラフを見ると8 hashes以上でfull attentionと同じ性能になっています。
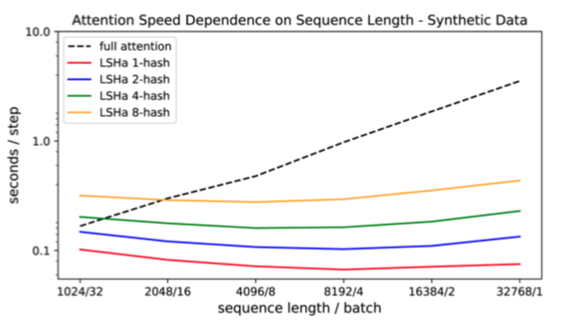
最後に、以下のグラフは入力シーケンスの長さに対する学習にかかる時間を示しています。
入力シーケンスが長くなるとfull attentionでは指数関数的にかかる時間が増加する一方で、LSH Attentionはほぼ一定になっていることが見てとれます。
まとめ
ReformerはTransformerモデルをリソース面で改善することで16GBのメモリ、単一のアクセラレータで最大で100万語の文章の処理を可能にしました。また文章だけでなく画像や動画を扱うタスクへの応用も期待できます。さらに大きな研究機関以外でも非常に長いシーケンスを扱えるようになる可能性も秘めており、AIの民主化という観点でも今後期待が高まりそうです。
参考文献
- Kitaev, N., Kaiser, Ł., & Levskaya, A. (2020). Reformer: The Efficient Transformer. arXiv preprint arXiv:2001.04451.
- Gomez, A. N., Ren, M., Urtasun, R., & Grosse, R. B. (2017). The reversible residual network: Backpropagation without storing activations. In Advances in neural information processing systems (pp. 2214-2224).
- Kitaev, N., Kaiser, Ł. (2020). Reformer: The Efficient Transformer. Retrieved from https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html?m=1
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

概要 今回は、以前ブログで紹介したText-to-Text Transfer Transformer(T5)から派生したWT5(Why? T5)を紹介します。 Text-to-Text Transfer Transformerとは、NLP(自然言語処理)のタスクをtext-to-text(テキストを入力して、テキストを出力する)形式として考えたもので、様々なタスクでSoTA(State of the Art=最高水準)を獲得しました。こちらの記事で詳し

機械学習のアルゴリズムがつくりだす状況を利用して、自然実験に近い分析をおこなった事例を紹介します。 このような事例を応用すれば、実際に実験をおこなわなくても介入効果などが分かるかもしれません。 はじめに 昨今、AI・機械学習の進歩のおかげで、様々な予測をおこなうことができるようになりました。 みなさんも機械学習を使った株価の予測などニュースでみかけることも増えたと思います。 株価だけでなく、交通量からチケットの売上・電力消費量etc......なんでも予測

概要 物体検知の分野ではCOCOと呼ばれるデータセットを使って、検知手法の精度に関して数値的な評価が行われます。2020年1月現在、トップの正解率を示しているのが、2019年9月に発表されたCBNetを用いた手法です。 今回は物体検知に関して全くの初心者の方でも理解できるように、この論文を解説していきたいと思います。(原著論文はこちら) 目次 前提知識 Backbone CNNベースの物体検知 モデルの評価 CBNetの構造 AHLC SLC ALLC D

機械学習では、訓練データとテストデータの違いによって、一部のテストデータに対する精度が上がらないことがあります。 例えば、水辺の鳥と野原の鳥を分類するCUB(Caltech-UCSD Birds-200-2011)データセットに対する画像認識の問題が挙げられます。意図的にではありますが訓練データを、 水辺の鳥が写っている画像は背景が水辺のものが90%、野原のものが10% 野原の鳥が写っている画像は背景が水辺のものが10%、野原のものが90% となるように