DEVELOPER’s BLOG
技術ブログ
【論文】CBNet:A Novel Composite Backbone Network Architecture for Object Detection の解説

概要
物体検知の分野ではCOCOと呼ばれるデータセットを使って、検知手法の精度に関して数値的な評価が行われます。2020年1月現在、トップの正解率を示しているのが、2019年9月に発表されたCBNetを用いた手法です。
今回は物体検知に関して全くの初心者の方でも理解できるように、この論文を解説していきたいと思います。(原著論文はこちら)
目次
前提知識
CBNetを理解する上で必要な物体検知についての知識をまとめます。以下の3つを押さえればCBNetだけでなく、物体検知全体の概要もつかめると思います。
Backbone
CNNの構造は以下のようになっているのでした。
※図はここから引用
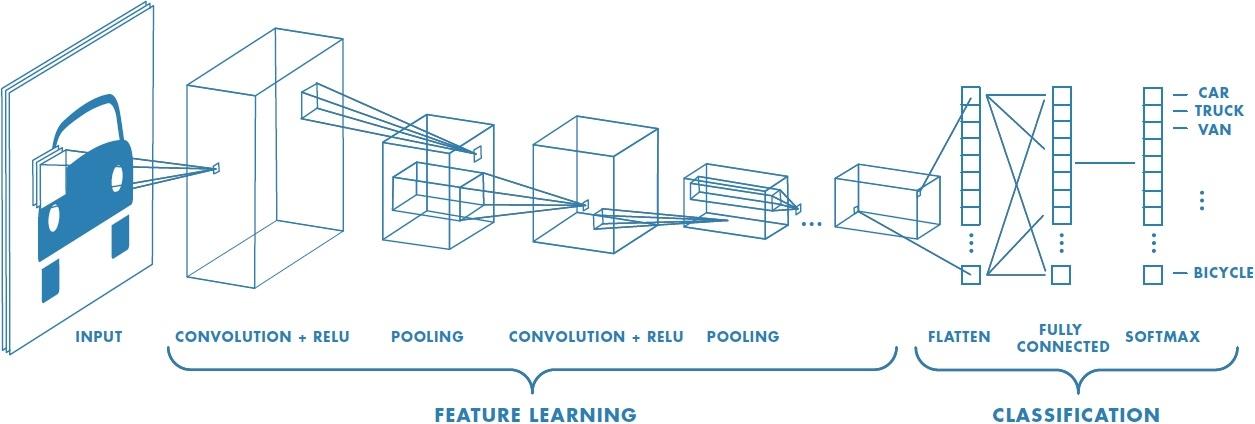
CNNの特徴は、上の図のFEATURE LEARNINGのように、ConvolutionとPoolingを繰り返して画像から特徴量を抽出することです。ここで得られた特徴量をもとにして、ニューラルネットワークで学習・予測を行うので、これをいかにうまく行うかが認識精度に直結します。その意味で、この特徴抽出の部分を論文に従って「Backbone」と呼ぶことにします。
CNNベースの物体検知
物体検知をするには、位置の検出と、物体の分類という、2つのタスクを行う必要があります。物体検知の手法はたくさんありますが、この2つのタスクを同時に行うか、別々に行うかで大きく2つに分かれます。
今回はこのうちで、後者の方法に注目します。例えば、最初期に使われていたR-CNNという手法では、まず物体がありそうな場所(これをRoIと呼びます)を見つけ、その後各RoIについてCNNを実行し分類を行います。ただ、これではすごく時間がかかってしまうので、これ以降の手法では様々な工夫をしていますが、基本的なアイディアは同じです。
従って、当然ですがCNNの精度を上げることが、物体検知の精度を上げることにつながります。

モデルの評価
モデルの性能を評価するには、どの程度正確に物体検知ができているかという精度の面と、どれくらいの早さで物体検知ができるのかというスピードの面の、両方を考慮する必要があります。例えば自動運転に使うモデルでは、いくら精度が高くても処理スピードが遅いと使い物になりませんよね。
スピードの指標は簡単で、1秒当たり何枚の画像を処理できるか、で決まります。例えば、高速で知られるYOLOというモデルは、条件にもよりますが、1秒で30枚ほど処理できますので、スピードは 30 fps ということになります。
では、精度についてはどのように測るかというと、位置の精度と分類の精度に分けて考えます。まず、位置の精度を求めるには以下のように計算します。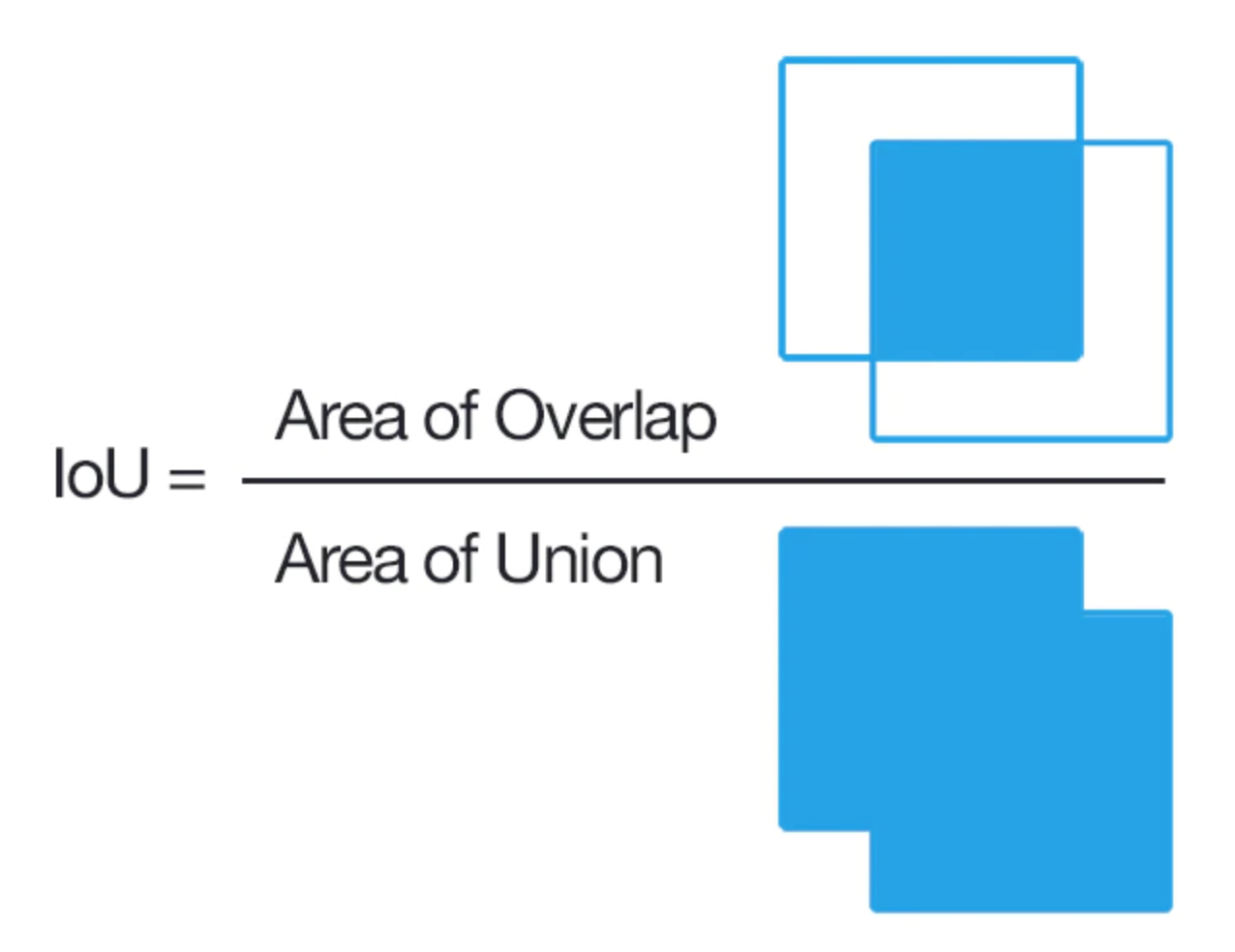
※図はここから引用
モデルが予測した位置と実際の位置の重なり具合を評価するわけです。完全に一致すると IoU = 1、全く違っている場合はIoU = 0 となります。
分類の精度については、AP や mAP といった数値が用いられます。これらを求めるのは少し複雑なのでこちらを参照してください。「単純にいくつ正解したか、じゃダメなの?」と思うかもしれませんが、それは正確ではありません。例えば画像の中に、リンゴが3つと梨が1つあったとします。いくつ正解したか、を精度の指標にしたとすると、全ての物体を「リンゴ」と予測するモデルが仮にあったとしても 0.75 という高い精度が出てしまうからです。
APもmAPも数字が大きいほど分類精度が高いことを意味します。
実際の評価では、位置の精度と分類の精度を組み合わせて、例えば \(AP_{50}\) のように表します。これは IoU が 0.5 以上の場合のみを考える、という意味です。
CBNetの構造
これまでの議論を踏まえた上で、いよいよ最新の手法CBNetについて解説したいと思います。
CBNetは"Composite Backbone Network"の略です。Compositeは「複合された」という意味なので、複数のBackboneを合わせた構造をしている、ということです。CBNetの新しいところはCNNによって得られた特徴マップを用いて物体検知を行う部分ではなく、CNNそれ自体に階層的な構造を導入したことです。(物体検知部分は他のモデルを使います。)
AHLC
CBNetの本質は以下の図に集約されているので、これを説明します。
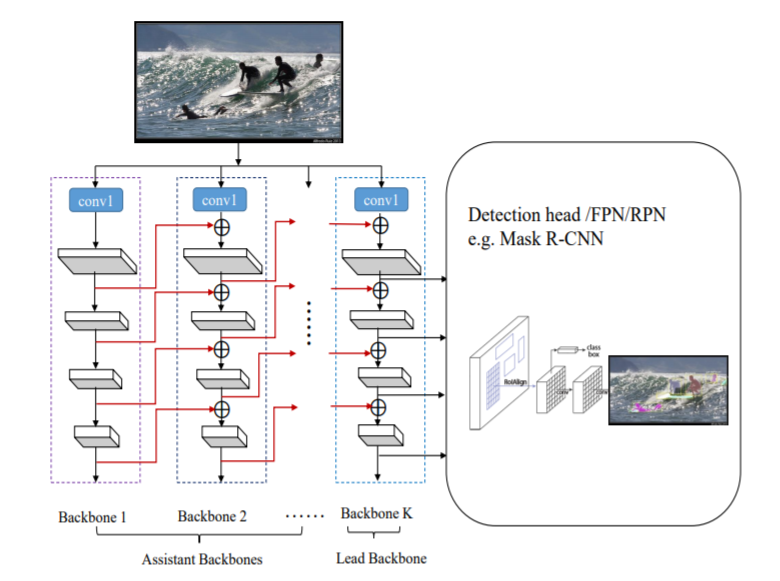
普通のCNNではBackboneは一つだけです。図でいうと、右端の一列しかありません。一方のCBNetでは複数のBackboneを用意し(通常2つか3つ)、一つのBackboneの出力を次のBackboneへと入力するという方法をとっています。最終的に右端のBackbone(Lead Backbone)に左にあるBackbone(Assistant Backbone)の効果がすべて反映されます。そしてLead Backbone の出力を最終的な特徴マップとして使い、物体検知を行います。
言葉では分かりにくいので数式で表現します。まず、通常のCNNの場合
\[ x^l = F^l \left(x^{l-1}\right),\,l\geq 2 \]
と表現できます。左辺の \(x^l\) は \(l\) 層目の出力を表しています。\(x^l\) はその前層の入力 \(x^{l-1}\) に何らかの処理(畳み込みやプーリング) \(F^l\) を施すことで得られる、ということを意味します。
続いてCBNetの場合は、次のように表現できます。
\[ x_k^l = F_k^l \left(x_k^{l-1} + g\left(x_{k-1}^l\right)\right),\,l\geq 2 \]
となります。\(x\) や \(F\) の右下に新しい添字 \(k\) が付きましたが、これは \(k\) 番目のBackboneであることを表します。また、新たに \(g\left(x_{k-1}^l\right)\) という項が加わりましたが、これは前の( \(k-1\) 番目の)Backboneの \(l\) 番目の出力に、(サイズを変えるなどの)処理 \(g\) を施したものも入力として加味することを意味します。このタイプを論文では AHLC (Adjacent Higher-Level Composition = 隣の上位層との合成)と呼んでいます。
CBNetの本質はこれで尽くされていますが、一つ前のBackboneの出力をどのように次のBackboneに入力するかによっていくつかのパターンがあります。順に見ていきましょう。
SLC (Same Level Composition = 同じ階層同士の合成)
以下の図を見て先程のAHLCと比べると分かりやすいです。
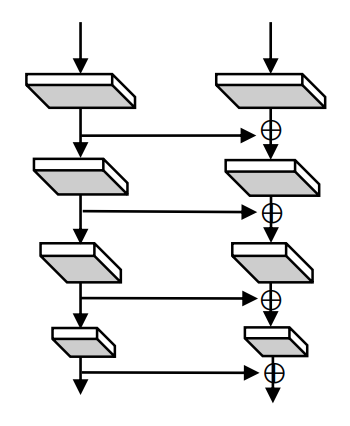
数式で表現すると次のようになります。
\[ x_k^l = F_k^l \left(x_k^{l-1} + g\left(x_{k-1}^{l-1}\right)\right),\,l\geq 2 \]
ALLC (Adjacent Lower-Level Composition = 隣の下位層との合成)
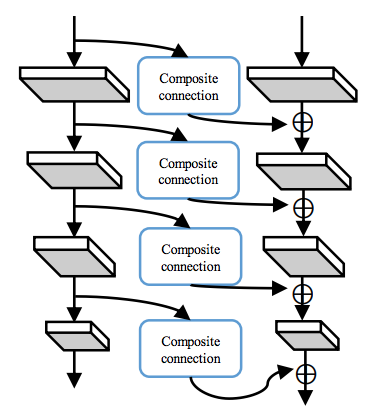
数式で表現すると、
\[ x_k^l = F_k^l \left(x_k^{l-1} + g(x_{k-1}^{l-2})\right),\,l\geq 2 \]
※論文中では \(g(x_{k-1}^{l+1})\)となっていますが、誤植だと思われます。
DHLC (Dense Higher-Level Composition)
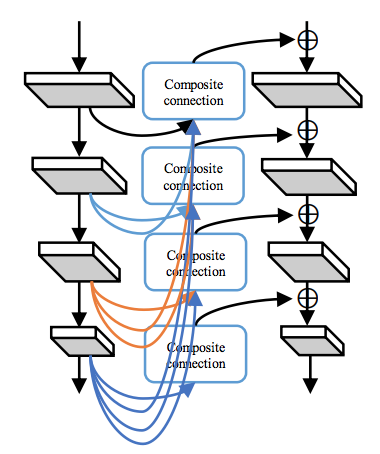
数式で表現すると、
\[ x_k^l = F_k^l \left(x_k^{l-1} + \sum_{i=l}^L g_i\left(x_{k-1}^i\right)\right),\,l\geq 2 \]
ここで \(L\) は各Backboneの階層数です。
まとめとして、以上の4つのモデルを並べてみます。
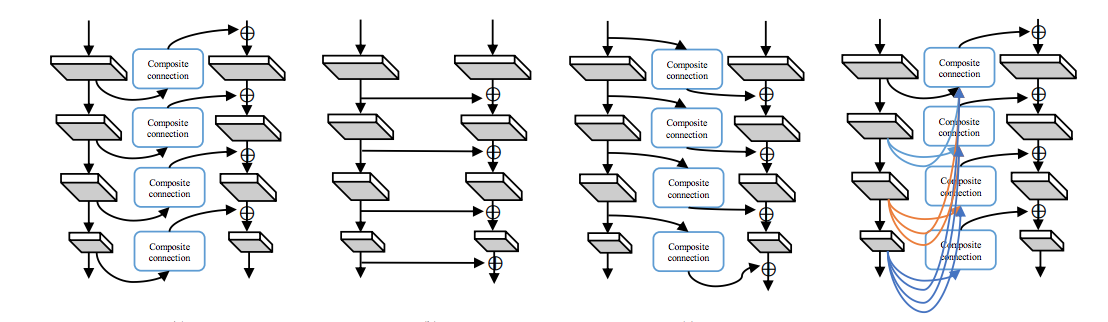
結果
最後に色々なパラメータを変えたときのCBNetの結果について示します。実行環境などの条件は論文を参照してください。
変えるパラメータは以下の3つです。
-
CBNetの種類
-
得られた特徴マップから物体検知を行うモデル
-
Backboneの数
1. CBNetの種類を変えた場合
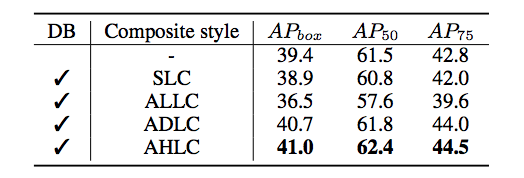
これを見ると、一番最初に示したAHLCが最も高い精度を示しているといえます。
ADLCとAHLC(DHLCと同じです)との比較から、単にパラメータを増やせば精度が上がる、という問題ではないことが言えます。
2. 物体検知を行うモデルを変えた場合
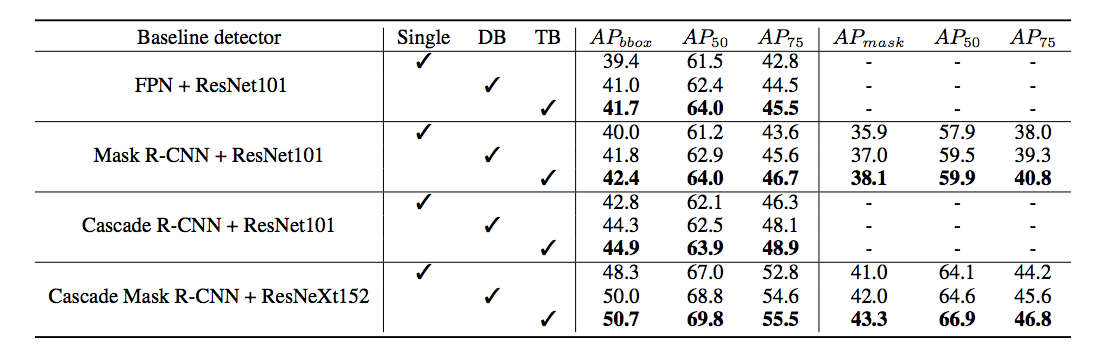
Singleは普通のCNN、DBは2層のBackbone、TBは3層のBackboneを表しています。これを見ると、どのモデルを使ってもCBNetが有効であることがわかります。これはCBNetによって画像の特徴がより良く抽出されていることを示唆しています。
3. Backboneの数を変えた場合
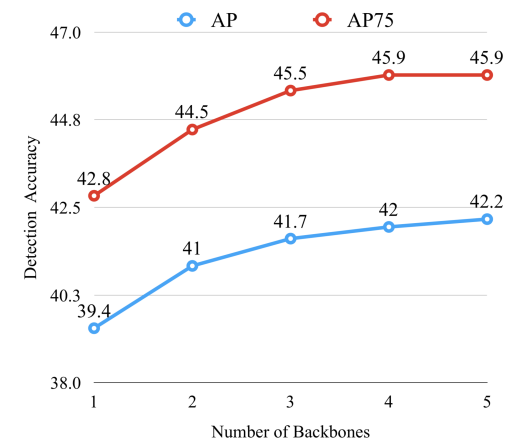
Backboneの数を増やすほど精度が上がっているのが見て取れます。計算量とのトレードオフも考慮すると、2層か3層にするのが良さそうです。
最後に、CBNetを用いた物体検知モデルと、他の有力な物体検知モデルとの比較です。
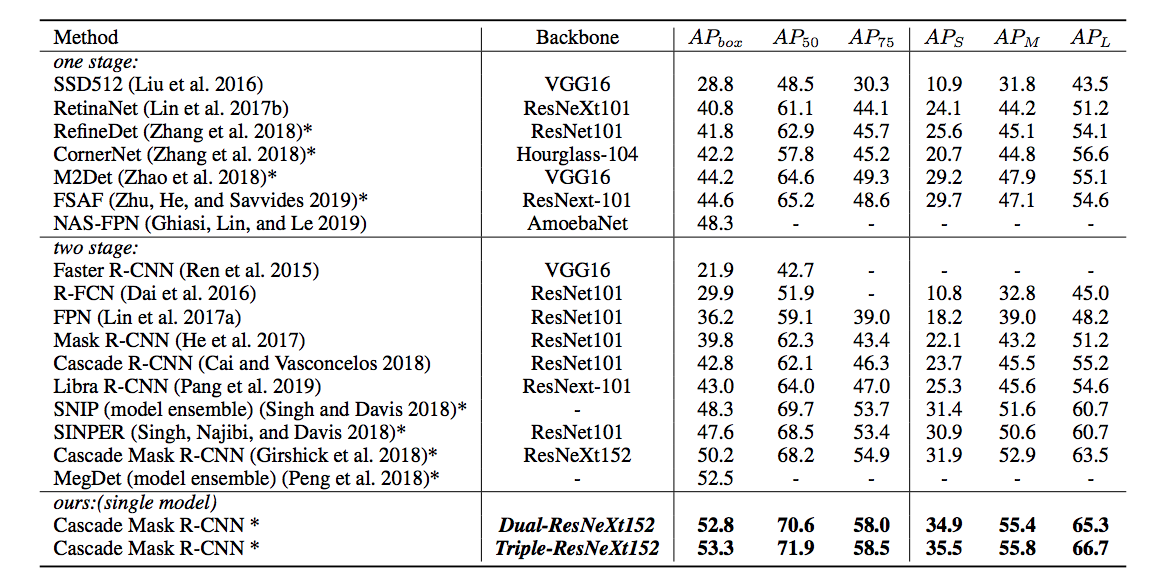
Cascade Mask R-CNNとCBNetを組み合わせたモデルが、精度の面では最高の成績を残しています。とはいっても未だに50%強の成績であり、改善の余地は十二分にあります。また、肝心な点である、なぜこうすると精度が上がるのか、ということは分かりません。現在の機械学習のモデルでありがちですが、よく分からないけどこうすると精度が上がったよ〜、というのが現状です。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

概要 今回は、以前ブログで紹介したText-to-Text Transfer Transformer(T5)から派生したWT5(Why? T5)を紹介します。 Text-to-Text Transfer Transformerとは、NLP(自然言語処理)のタスクをtext-to-text(テキストを入力して、テキストを出力する)形式として考えたもので、様々なタスクでSoTA(State of the Art=最高水準)を獲得しました。こちらの記事で詳し

機械学習のアルゴリズムがつくりだす状況を利用して、自然実験に近い分析をおこなった事例を紹介します。 このような事例を応用すれば、実際に実験をおこなわなくても介入効果などが分かるかもしれません。 はじめに 昨今、AI・機械学習の進歩のおかげで、様々な予測をおこなうことができるようになりました。 みなさんも機械学習を使った株価の予測などニュースでみかけることも増えたと思います。 株価だけでなく、交通量からチケットの売上・電力消費量etc......なんでも予測

概要 小説を丸ごと理解できるAIとしてReformerモデルが発表され話題になっています。今回はこのReforerモデルが発表された論文の解説を行います。 自然言語や音楽、動画などのSequentialデータを理解するには広範囲における文脈の依存関係を理解する必要があり困難なタスクです。"Attention is all you need"の論文で紹介されたTransformerモデルは広くこれらの分野で用いられ、優秀な結果を出しています。 例えば機械翻訳

機械学習では、訓練データとテストデータの違いによって、一部のテストデータに対する精度が上がらないことがあります。 例えば、水辺の鳥と野原の鳥を分類するCUB(Caltech-UCSD Birds-200-2011)データセットに対する画像認識の問題が挙げられます。意図的にではありますが訓練データを、 水辺の鳥が写っている画像は背景が水辺のものが90%、野原のものが10% 野原の鳥が写っている画像は背景が水辺のものが10%、野原のものが90% となるように