DEVELOPER’s BLOG
技術ブログ
U-net番外編:ResNetはなぜ高精度なのか
はじめに
今回はU-netの番外編でskip-conectionについてまとめようと思います。 前回のtensorflowで学習をさせてみた際に、skip-conectionがない場合、学習が遅いだけでなく精度が悪いことがわかりました。 skip-conectionが(おそらく)初めて使われたのが2015年12月に発表されたResNetで、ImageNet2015の分類コンペ(ILSVRC 2015)で1位になりました。
目次
- ResNet以前
- skip-conection
- skip-conectionの効果
- なぜskip-conectionが効くのか
1.ResNet以前
深層学習において層の数はとても重要な要素であり、ImageNetにおいてResNetが発表される以前は16~30層ほどの比較的深いモデルが主流でした。 そこで「層を深くすればするほど、精度は良くなるのか」という疑問が生まれますが、そう上手くはいきません。 なぜなら層を深くすることにより勾配消失問題が起きてしまうからです。 この勾配消失問題に対してBatch Normalizationが考案され、勾配消失が起きづらくなりました。
しかし、層を深くしていく中である深さで精度が頭打ちになり、更に層を増やすことで精度が著しく悪くなってしまいました。
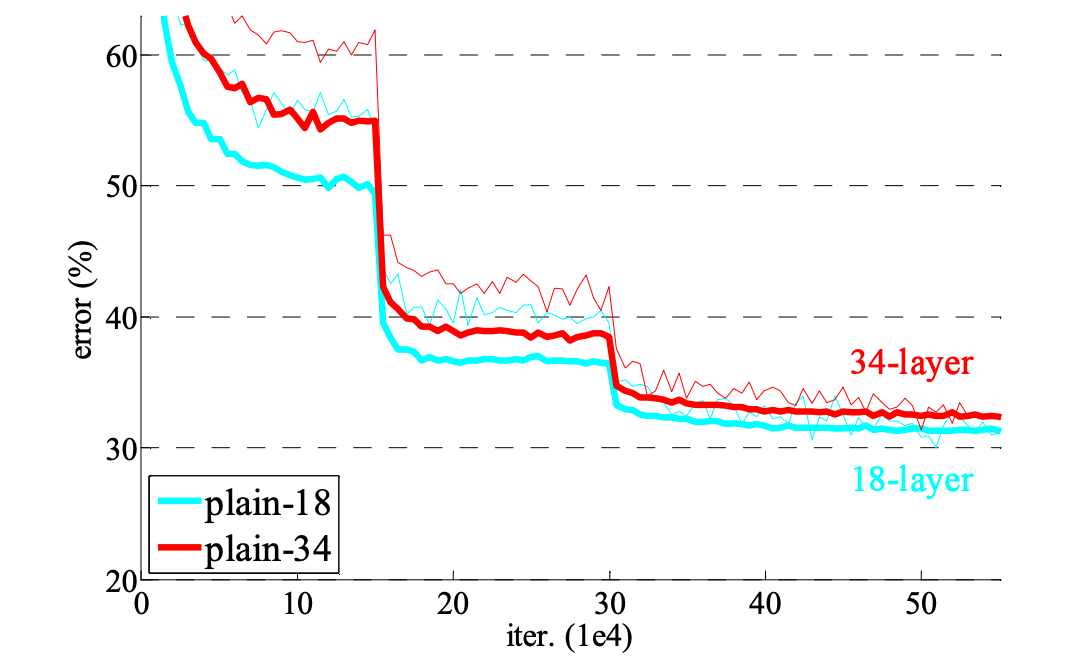
上の図を見ると18層のモデルに層を追加し34層にしても精度がほとんど変わらないどころか、むしろ悪くなっていることがわかります。
2.skip-conection
ResNetの著者は、上の図に現れている劣化現象は勾配消失によるものではなく重みの最適化に問題があると考えました。つまり層を深くしても最適化できず、層を深くした恩恵を受けられないと考えました。 そこで考案されたのがskip-conectionです。
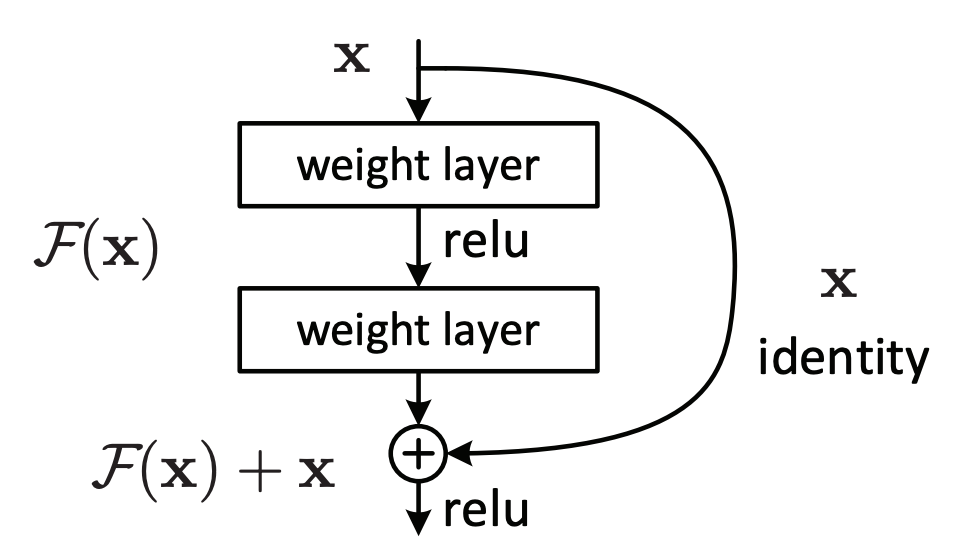
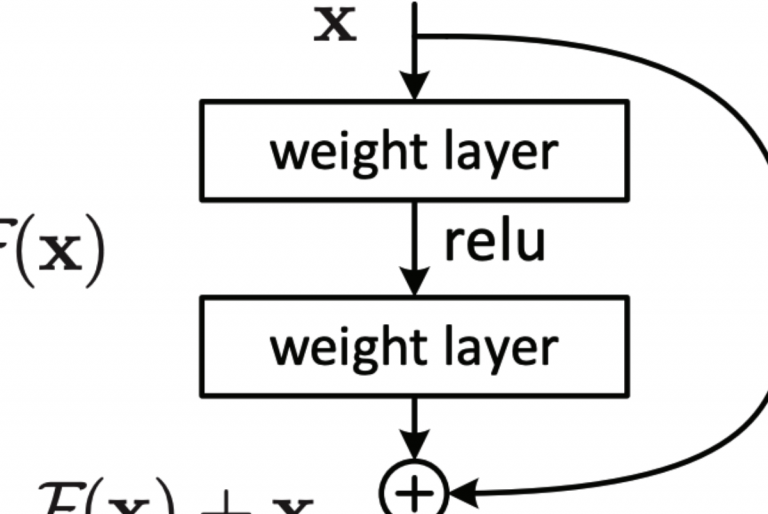
xを入力として、xに重みをかける(weighted layerを通る)関数をF(x)とします。 F(x) + xを最終的な出力としています。
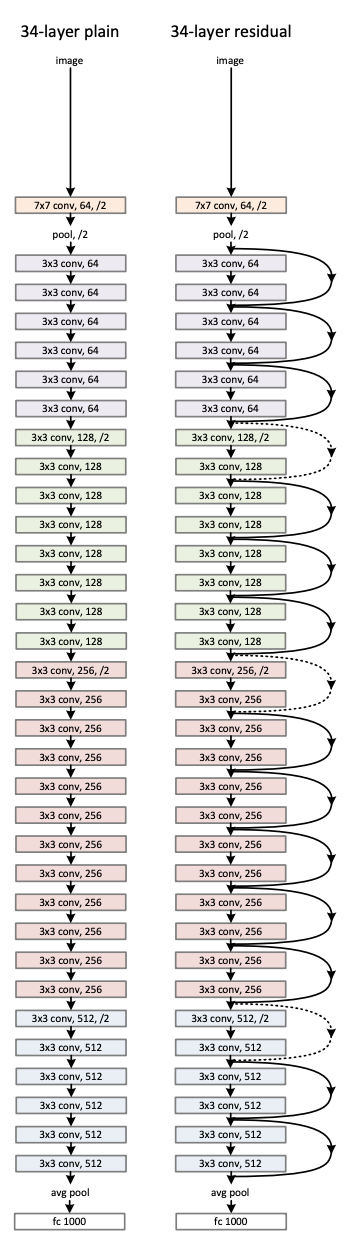
skip-conectionを34層のモデルで行った様子は以下のようになります。 左が通常のモデル、右がskip-conectionありのモデル
3.skip-conectionの効果
通常のモデルにskip-conectionを用いたものをResNetと呼ぶことにします。 上と同様にImageNetで精度を計算すると以下のようになりました。
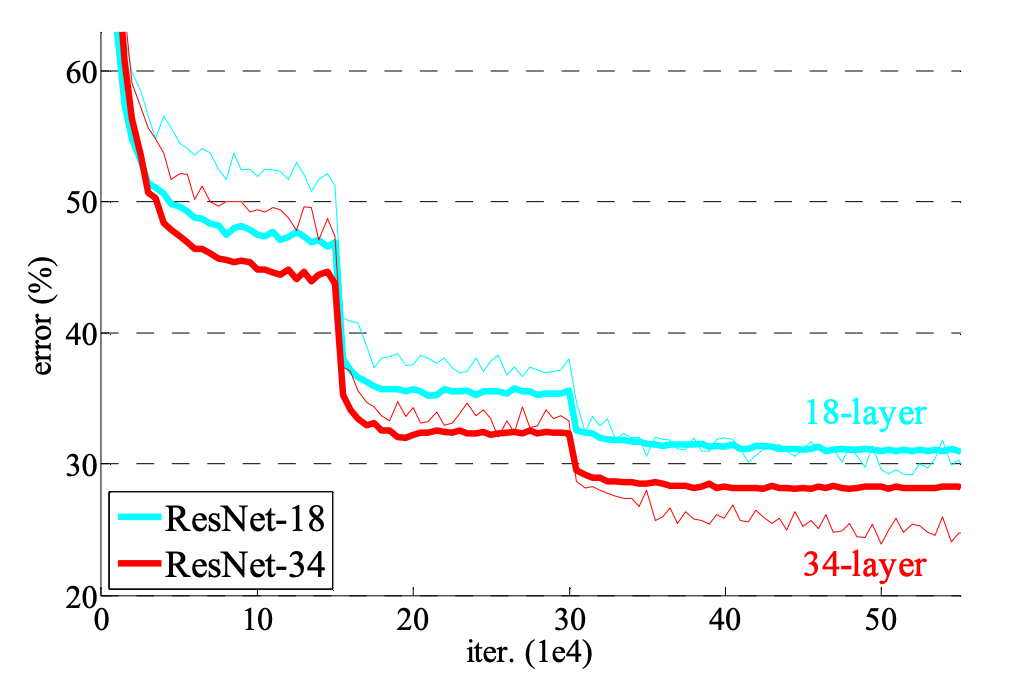 層が深いモデルの方が精度が良いことがわかります。
さらに重要なことに34層のモデルの学習時の精度(赤の細線)が、18層のモデルの学習時の精度(青の細線)よりもかなり良くなっていることがわかります。
これは劣化現象を上手く解決し、より深く学習できるようになったことを示しています。
(層を深くすることによる恩恵を受けられた。)
層が深いモデルの方が精度が良いことがわかります。
さらに重要なことに34層のモデルの学習時の精度(赤の細線)が、18層のモデルの学習時の精度(青の細線)よりもかなり良くなっていることがわかります。
これは劣化現象を上手く解決し、より深く学習できるようになったことを示しています。
(層を深くすることによる恩恵を受けられた。)
4.なぜskip-conectionが効くのか
xを入力としてH(x)を目標とする関数とします。
xに重みをかける(weighted layerを通る)関数をF(x)とします。
F(x) + xを最終的な出力とし、これを目標の関数H(x)に近づけます。
F(x) + x = H(x) の時(目標の関数に等しくなれた時) F(x) = H(x) - xとなることから、Fは入力xと目標とする関数H(x)の残差(residual)と等しいことがわかります。
つまりFそのものをHに近くなるように学習するのではなく、Hとxの残差を正確に予測できるように学習しています。
このようにするとHが恒等関数に近い時、FそのものをHに近づけるのは難しいですが、F+xを近づけることは簡単になります。 論文の筆者も劣化問題は目標の関数Hが恒等関数の時、重みに対して非線形である関数FでHに近づくことが難しいために起きていると主張しています。
まとめ
U-netでskip-conectionは畳み込みにより失われる物体の位置情報を保持する役目があり、skip-conectionが使われ始めた当初とは少しだけニュアンスが違うように感じました。 残差を予測するという考えは以前からあるようで、代表的なものだとGBDTが挙げられます。 こちらの記事も是非ご覧ください。
GBDTを小学生レベルの数学で直感的に理解する
参考
https://arxiv.org/abs/1512.03385
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

概要 先日の勉強会にてインターン生の1人が物体検出について発表してくれました。これまで物体検出は学習済みのモデルを使うことが多く、仕組みを知る機会がなかったのでとても良い機会になりました。今回の記事では発表してくれた内容をシェアしていきたいと思います。 あくまで物体検出の入門ということで理論の深堀りや実装までは扱いませんが悪しからず。 物体検出とは ディープラーニングによる画像タスクといえば画像の分類タスクがよく挙げられます。例としては以下の犬の画像から犬

概要 小説を丸ごと理解できるAIとしてReformerモデルが発表され話題になっています。今回はこのReforerモデルが発表された論文の解説を行います。 自然言語や音楽、動画などのSequentialデータを理解するには広範囲における文脈の依存関係を理解する必要があり困難なタスクです。"Attention is all you need"の論文で紹介されたTransformerモデルは広くこれらの分野で用いられ、優秀な結果を出しています。 例えば機械翻訳

機械学習では、訓練データとテストデータの違いによって、一部のテストデータに対する精度が上がらないことがあります。 例えば、水辺の鳥と野原の鳥を分類するCUB(Caltech-UCSD Birds-200-2011)データセットに対する画像認識の問題が挙げられます。意図的にではありますが訓練データを、 水辺の鳥が写っている画像は背景が水辺のものが90%、野原のものが10% 野原の鳥が写っている画像は背景が水辺のものが10%、野原のものが90% となるように
はじめに この記事では物体検出に興味がある初学者向けに、最新技術をデモンストレーションを通して体感的に知ってもらうことを目的としています。今回紹介するのはAAAI19というカンファレンスにて精度と速度を高水準で叩き出した「M2Det」です。one-stage手法の中では最強モデル候補の一つとなっており、以下の図を見ても分かるようにYOLO,SSD,Refine-Net等と比較しても同程度の速度を保ちつつ、精度が上がっていることがわかります。 ※https: