DEVELOPER’s BLOG
技術ブログ
AWSの可用性設計を考える:AZ・リージョン・事業継続計画(BCP)のバランス

- はじめに
- 可用性設計の基礎:リージョンとAZの仕組みを理解する
- 止まらない設計を妨げる単一点障害:単一AZ構成の限界
- マルチAZ構成:同一リージョン内での止まらない仕組み
- マルチリージョン構成:事業継続(BCP)のための冗長化
- まとめ:設計段階で「どこまで止めないか」を決めよう
1. はじめに
AWSは、数クリックで仮想サーバー(EC2)を立ち上げられるなど、手軽にサービスを構築できるクラウドです。システム企画や開発の初期段階では「とりあえず動いているから大丈夫」と感じてしまうことも多いかもしれません。しかし、「動作確認ができた」=「安全に運用できる」とは限りません。停電や災害などが発生した場合にも「止まらないこと」や「早期復旧できること」が事業継続計画(BCP)の観点では重要です。
本記事では、システム企画者向けに「可用性設計」の考え方をアベイラビリティゾーン(AZ)、リージョン、事業継続計画(BCP)の3つの視点から整理します。
2. 可用性設計の基礎:リージョンとAZの仕組みを理解する
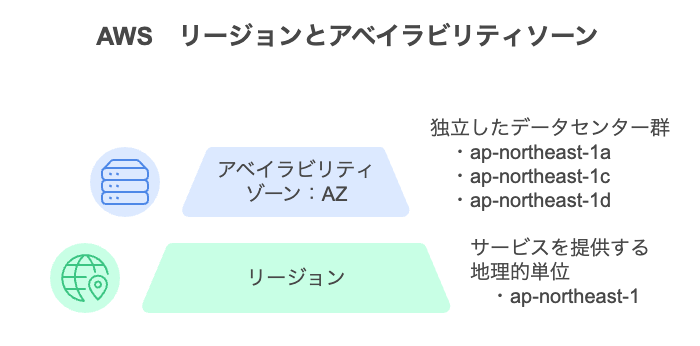
AWSでは、サービスを提供する地理的な単位を「リージョン(Region)」と呼びます。例えば、東京(ap-northeast-1)、米国バージニア北部(us-east-1)、欧州ロンドン(eu-west-2)など、各リージョンは世界中に分散しています。
各リージョンの中には複数の「アベイラビリティゾーン(Availability Zone:AZ)」が存在し、AZは「物理的に独立したデータセンター群(電力・冷却・ネットワークが分離)」として設計されています。例えば、東京リージョン(ap-northeast-1)には2025年11月時点で3つのAZ(1a、1c、1d)が存在します。(参考:AWSグローバルインフラストラクチャ)
 AZが同一地域内にありながら物理的にも論理的にも分離された拠点となっているのは、クラウドの「高可用性(High Availability)」を支える基礎となっています。例えば、東京リージョン(ap-northeast-1)のAZ(1a)で停電などの障害が発生しても、他のAZ(1c、1d)は稼働し続けられる設計になっています。この構造を理解することが可用性設計を考える第一歩です。
AZが同一地域内にありながら物理的にも論理的にも分離された拠点となっているのは、クラウドの「高可用性(High Availability)」を支える基礎となっています。例えば、東京リージョン(ap-northeast-1)のAZ(1a)で停電などの障害が発生しても、他のAZ(1c、1d)は稼働し続けられる設計になっています。この構造を理解することが可用性設計を考える第一歩です。
3.止まらない設計を妨げる単一障害点:単一AZ構成の限界
AWSでは最小構成であれば1つのAZにEC2とRDSを立てる単一AZ構成でも動作しますが「とりあえず動く」便利さが落とし穴にもなります。もし、AZで障害が起きた場合、EC2もRDSも同時に停止してしまいます。
実際、過去には特定AZの電源障害・ネットワーク障害によって多くのサービスが影響を受けた事例もあります。例えば2025年4月15日、東京リージョン(ap-northeast-1)のアベイラビリティゾーン(ap-northeast-1a)で障害が発生しました。(参考:AWSヘルスダッシュボード)当該AZで起動されたEC2インスタンスや、影響を受けたEC2インスタンスを利用する他のAWS APIで、エラー率やレイテンシーの増加など影響が及んだことが報告されました。
単一AZ構成のような「とりあえず動く構成」は将来的にはリスクを増やすことを認識し、障害発生でシステム全体が停止してしまう「単一障害点」を極力なくすことが重要です。
4.マルチAZ構成:同一リージョン内での止まらない仕組み
AZが物理的に独立したデータセンター群として構成されている仕組みを活かせば、1つのAZに障害が発生しても、別のAZでサービスを継続することができます。同一リージョン内で複数のAZにリソースを配置することで、片方に障害が起きても、もう一方で稼働を継続できる「マルチAZ構成」が可用性設計の第一歩です。
例えば、前節で例に挙げた「1つのAZにEC2とRDSを立てる」単一AZ構成は、LB、AutoScalingやRDS(プライマリ・スタンバイ)を使ってマルチAZ構成にすることができます。以下のマルチAZ構成例では、単一AZに配置したリソースの大きな1サーバで全リクエストを捌くのではなく、小さいサイズのインスタンスをマルチAZに配備して負荷分散およびオートスケーリングをして同じ量のリクエストを捌くようにすることで、1つのAZに障害が発生した場合にも自動回復力の高いサービスを提供することができます。
また、「RDS(マルチAZ)」では、AWSが自動的に別のAZに「待機用(スタンバイ)DB」を複製してくれます。もしプライマリ側のAZで障害が発生しても、AWSが自動的にスタンバイDBへ切り替えてくれるため、データベースの可用性を確保できます。
マルチAZ構成は、ALBやレプリカといった追加リソースの配置が必要になるケースが多くコストが増加する傾向はありますが、「システムが止まらない」安心を比較的低コストで得られる現実的な方法です。
 マルチAZ構成例 (引用:3つのAZにデプロイされる多階層アーキテクチャ)
マルチAZ構成例 (引用:3つのAZにデプロイされる多階層アーキテクチャ)
よくあるマルチAZ構成例
| サービス | マルチAZ構成例 | 効果 |
|---|---|---|
| EC2+ALB | EC2を2つのAZに配置し、ALBで負荷分散 | Webアプリの冗長化 |
| RDS | マルチAZオプションを有効化 | 自動フェイルオーバーによるDB耐障害性 |
| ElastiCache | プライマリ+リードレプリカを別AZに配置 | キャッシュ層の冗長化 |
5.マルチリージョン構成:BCP(事業継続)のための冗長化
マルチAZ構成で防げないのが「地域全体の障害」です。地震・大規模停電など、AZ単位ではなくリージョン単位で影響が及ぶケースでは「マルチリージョン構成」が有効となります。例えば、東京リージョン(ap-northeast-1)と大阪リージョン(ap-northeast-3)を組み合わせるケースが代表的です。
以下の手法を組み合わせることで、片方のリージョンが完全停止しても他方で業務を継続できる仕組みを作ることができます。マルチリージョン構成はコスト・運用負荷も大きくなりますが、金融・医療・公共系など「止まってはいけない」領域では必須の戦略です。
代表的なマルチリージョン設計手法
| 手法 | サービス例 | 概要 |
|---|---|---|
| クロスリージョンバックアップ | AWS Backup(EC2・RDSなど) | 別リージョンに自動バックアップ |
| データ複製 | S3クロスリージョンレプリケーション(CRR) | 別リージョンに自動バックアップ |
| DB冗長化 | Aurora Global Database | 数秒以内で他リージョンに同期 |
| フェイルオーバー | Route 53 Health Check | 障害時に別リージョンへ自動切り替え |
6.まとめ:設計段階で「どこまで止めないか」を決めよう
最後に、AWSにおける可用性設計を整理すると、以下の3段階に分かれます。
1. 単一AZ構成:開発やテストなど、短期的利用に最適
2. マルチAZ構成:一般的な商用システムの信頼性確保
3. マルチリージョン構成:ミッションクリティカルシステム向け
システム企画者が意識すべきことは「どのレベルの可用性を求めるか」を企画の初期段階で明確にすることです。運用が始まってからの再構築は、コスト・工数・ダウンタイムの面で非常に負担が大きくなるため、企画段階で「どこまで止めないか」を決め、開発・運用チームと共通認識を持つことが大切です。
X(旧Twitter)・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

Walmartは生成AIを活用した翻訳エンジンを作り、翻訳コストを99%削減しました。年間約2,500万ドルかけていた翻訳作業を、AIを組み込んだ「Walmart Translation Platform(WTP)」に置き換えることに成功しました。成功のポイントは、単純に単語を置き換える(翻訳する)ことではなく、意味・意図を汲んで訳したことでした。 その成功のポイントを整理すると、AWSが提唱する「AI BPR」というフレームワークとの類似性が見えてきま

はじめに AWS RAPIDとは AWS RAPIDによる書類審査デモ AWS RAPIDのプロンプト改良で精度向上 AWS RAPIDの「嬉しい点」とまとめ おわりに はじめに 書類審査業務のDXを実現する「AWS RAPID」 設計書や契約書、申請書などの書類審査業務は、多くの組織で重要な業務の一つです。 しかし実際の現場では、「チェック項目が多すぎる」「確認する書類が膨大」「審査に時間がかかる」といった悩みを抱えている方

アマゾンジャパン品川オフィス はじめに AI BPRとは ワークショップの内容 参加者の声 組織への展開と本格導入 1.はじめに 売上や現場の数字を見ながら、次々と判断を下す毎日。「これAIでやってくれないかなぁ」と感じたことはありませんか。 生成 AI のニュースは毎日のように流れてきますが、自社の業務で「使える」という実感を持てている方は、まだ少ないのではないでしょうか。業務の中で日々判断を重ねている方ほど、目の前の業務を AI が

はじめに 環境構築手順 Store Manager Agentで実現できること まとめ 1.はじめに 店舗運営において、こんなお悩みはありませんか。 売上データは見ているが、次に何をすべきか判断に迷う 売場づくりや品揃えが、どうしてもベテラン頼みになってしまう 在庫・売上・時間帯など、考えるべき要素が多すぎる 数字の振り返りはしているものの、改善アクションに落とし込めない こうした課題は、特定の業種だけのものではありません。 例えば、 ス