DEVELOPER’s BLOG
技術ブログ
人材不足に立ち向かうSREの力:次世代の運用体制をどう築くか

- はじめに:運用現場の"人材不足"が引き起こすリスクとは?
- なぜSREが"人手に依存しない運用"を可能にするのか?
- 自動化・可観測性がもたらす省力化と再現性
- 従来の限界を超えた次世代の運用支援〜生成AI×SREの事例〜
- 今すぐ始めるためのSRE導入チェックリスト
- まとめ:人が足りない今こそ、SREという選択を
1.はじめに:運用現場の"人材不足"が引き起こすリスクとは?
クラウド化やマイクロサービスの導入が進む中、IT運用の現場では深刻な人材不足が表面化しています。 経済産業省の『IT人材需給に関する調査(概要)』(2019)では、2030年時点で最大79万人のIT人材が不足する可能性があると予測されており、特にインフラやシステム運用分野での人材確保が極めて難しい状況にあると明記されています。 この人材不足は、単なる"数"の問題にとどまりません。運用現場ではすでに、以下のような問題が顕在化しています。
- 障害対応の遅延:トラブル発生時に即時対応できる体制が組めない
- セキュリティリスクの増加:パッチ対応の遅れや設定ミスが生じやすい
- 業務の属人化:特定のメンバーにしか対応できない領域が増え、退職がリスクに直結
このような状況下で、従来の"人海戦術"に依存した運用モデルでは立ち行かなくなってきています。今、本当に求められているのは、少人数でも高信頼・高可用性を実現する、持続可能な運用体制です。 その解決策として、注目を集めているのが SRE(Site Reliability Engineering)です。 SREは、Googleが提唱した手法で、システムの信頼性と可用性を向上させることを目的としています。手作業に依存せず運用の安定性と効率性を両立させる考え方です。人材不足という構造的課題を乗り越えるための、現実的かつ強力なアプローチといえるでしょう。
2. なぜSREが"人手に依存しない運用"を可能にするのか?
以下の3つの特徴が、SREが少人数運用を可能にする理由です。
① Toil(単純作業)の徹底排除と自動化
SREは、繰り返し発生する機械的・労働集約的な作業(=Toil)を可能な限り自動化することを最優先します。 例えば、 以下の「人が手を動かさなくても回る仕組み」を先に作ります。
- 障害対応の自動復旧スクリプト
- 定型的な監視アラートの自動チューニング
- デプロイパイプラインのCI/CD自動化
結果として、限られた人員でも運用業務に追われることなく、本質的な改善に時間を割けるようになります。
② SLI/SLOによる"信頼性の定量管理"
SREでは、「なんとなく安定している」ではなく、サービスの信頼性を指標(SLI)と目標(SLO)で定量化します。 これにより、
- どの程度の障害まで許容できるのか(エラーバジェット)
- どの改善活動が最も効果的なのか
といった判断がデータに基づいて行えるようになり、無駄な人員投入や過剰対応を避けられます。
③再現性のある運用体制の構築
SREは、属人性の排除も大きなテーマです。手順を明文化した「Runbook(=運用手順書)」や、構成情報をプログラムで管理する「IaC(=Infrastructure as Code)」の導入により、以下の再現性の高い運用基盤が実現します。
- 誰が見ても同じ手順で作業できる
- 手動の設定ミスが減る
- 新メンバーがすぐにキャッチアップできる
つまり、SREは「優秀な人を集める」ことを前提とした運用ではなく、「限られた人員で最大限の信頼性を引き出す」ための設計思想といえます。 これが、SREが人材不足時代において不可欠な戦略として注目されている理由です。
3. 自動化・可観測性がもたらす省力化と再現性
3-1.自動化による"ミスなき省力運用"の実現
SREが目指す自動化は、単なるシェルスクリプトの自動実行ではありません。 以下のような領域をシステムとして制御可能にすることを指します。
CI/CDの自動パイプライン:デプロイの品質と速度を同時に担保
障害対応の自動リカバリ:例)Kubernetesによるポッドの自動再スケジューリング
インシデント通知とRunbook連携:PagerDutyやOpsgenieを活用した自動フロー
これにより、"ミスを許さない設計"を先に組み込むことで、人的リソースへの依存度を下げることができます。特に夜間や休日の対応など、手動対応が負担になる場面で大きな効果を発揮します。
3-2.可観測性による"再現性ある問題解決"の推進
人材が足りない現場では、「誰でも素早く正確に障害原因を特定できる」仕組みが不可欠です。そのために必要なのが、可観測性(Observability)の向上です。 従来の「監視(Monitoring)」は、CPU使用率やメモリなどのメトリクス中心でしたが、可観測性では以下のような3つのデータ軸を総合的に扱います。
- メトリクス(Metrics):CPU、レイテンシ、リクエスト数
- ログ(Logs):アプリやOSの記録情報
- トレース(Traces):分散システムにおけるリクエストの流れ
ツールとしては、Prometheus+Grafana、OpenTelemetry、Datadog、New Relicなどが活用されており、 障害が起きた瞬間に「何が」「どこで」「なぜ」起きたのかを誰でも特定できる状態を実現します。これにより、属人性の高い"職人の勘"に頼らずとも、再現性と客観性のある障害対応が可能になります。 SREの現場では、自動化と可観測性を一体化させることで、「人手が足りない」ではなく、「人の介入がそもそも少なくて済む」環境そのものを構築することが重要視されています。
4. 従来の限界を超えた次世代の運用支援〜生成AI×SREの事例〜
生成AIとSREを融合させることで、従来の限界を超えた次世代の運用支援を実現できます。ここでは、実際のプロジェクトで見られた活用パターンとその成果を、事例ベースでご紹介します。
4-1.ケーススタディ:障害一次対応の自動化と省力化
ある製造業向けクラウドシステムでは、月間で平均50件以上のアラートが発生していました。その中には実際には対応不要な「誤検知アラート」も多く、運用担当者の疲弊と対応遅延が課題となっていました。この課題に対して以下のような生成AIとSREの連携アプローチが考えられます。
解決策
AIによるアラート内容の自然言語分類・優先度判断
→ 例)ChatGPT APIを活用し、アラート内容から"重大度・影響範囲"を分類Prometheus+自動Runbook生成機能の連携
→ 例)対応フローをLLMが要約し、Runbookのドラフトを自動で作成Slackへの自動通知と対応フロー提案
→ 例)SRE担当者に対応案を即時提示し、判断と対応を加速
成果
誤検知アラートの手動確認時間が80%以上削減
対応優先度のミスがゼロに
運用者の「心理的負担の軽減」につながり、離職リスクの低減にも寄与
4-2.生成AIによる"ナレッジの非属人化"
別プロジェクトでは、長年特定エンジニアが担当していた運用プロセスの引き継ぎが困難という課題がありました。 そこで、過去の障害対応記録や手順書をLLMに学習させ、ナレッジベースの自動化と検索機能を構築することにより、新人エンジニアでも即時に「過去の類似事例」、「対処方法」、「関係システム」を自然言語で取得できるようになりました。 結果、OJT期間が2週間から5日に短縮され、現場の立ち上がりが大幅にスピードアップしました。 このように生成AIの柔軟性とSREの自律性を融合させることで、「少人数でも運用が回る」実践的な仕組みを提供しています。
5. 今すぐ始めるためのSRE導入チェックリスト
「SREを導入したいけれど、自社のような少人数体制で本当にできるのか?」という声はよく聞かれます。しかし、SREは大規模企業専用のものではなく、中小規模のチームでも段階的に導入できるフレームワークです。以下に、SREを無理なく始めるためのチェックリストをご用意しました。まずは「現状把握」と「小さな一歩」から始めてみましょう。
基本チェックリスト
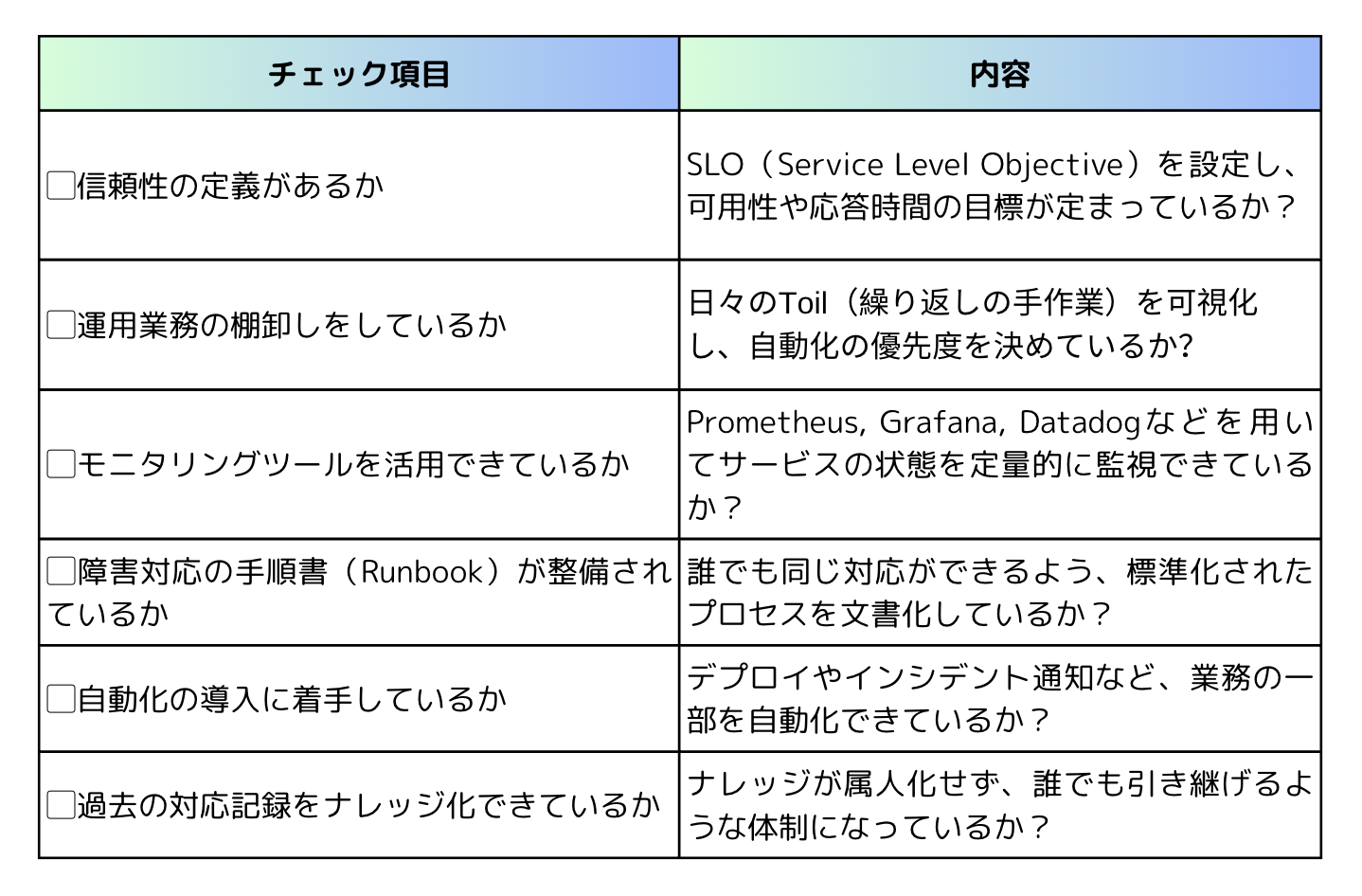
小さく始めるコツ
SLOを1つのサービスにだけ設定してみる
毎週1つのToilを削減することにフォーカスする
まずはRunbookのドラフトだけでも作成してみる
生成AIを使って手順書やFAQの自動化を試す
このように、"完璧を目指さない"ことが継続の鍵です。最初の一歩はとても小さくて構いません。まずはじめの一歩を踏み出すことが重要です。
6. まとめ:人が足りない今こそ、SREという選択を
IT運用の現場は今、未曾有の転換期にあります。
- インフラは複雑化
- サービスの可用性はビジネスの生命線
- 人材が不足
こうした背景の中で、SREという考え方は「人がいないからこそ選ぶべき運用戦略」として、その真価を発揮します。 SREは、単なる運用自動化の手法ではありません。
- 信頼性を定量的に管理
→人間が対応しなくてよい作業を徹底的に削減
- 属人化を排除した再現性ある運用体制を構築する
つまり、「限られた人材でも運用の質を落とさない」ための思想と仕組みといえます。 人手不足で困っているという状態で構いません。状況の整理から一緒に伴走させていただきます。何かお困り事がございましたら、お気軽にお問い合わせください。
X(旧Twitter)・Facebookで定期的に情報発信しています!
Follow @acceluniverse