DEVELOPER’s BLOG
技術ブログ
SRE導入で成果を上げるシステムとは?失敗しないための選定ポイント

1.はじめに
クラウド環境の最適化を検討されている方が、SRE(Site Reliability Engineering)について情報収集をされる際、どのようなシステムが向いており、どんな条件下で最大の効果を発揮するのかを理解することは効果的です。本記事では、システムよりの具体例や技術的観点を交えて、「SREが適したシステム」と「効果を引き出すポイント」を詳しく解説します。
2.SREが向いているシステムの具体例
2-1.高可用性が必須な業務基幹システム
企業の中核を担う基幹システムは、業務の停止が直接的な損失や信頼の低下につながるため、SREの手法を取り入れることで信頼性を向上させられます。
・ERPシステム
販売管理、在庫管理、財務会計などを一元管理するERPシステムは、停止すると事業運営全体に影響を及ぼします。SREでは、システムダウンを未然に防ぐためのモニタリングや予測分析を導入し、ダウンタイムを最小化します。
・顧客管理システム(CRM)
クラウド型CRMシステムやオンプレミスCRMは、営業やカスタマーサポートの効率化に重要です。ここでのSLO設定(例: サーバ応答時間95%以内に100ms)やエラーバジェットの活用は、ユーザー満足度を高める鍵となります。
2-2. ミッションクリティカルなシステム
特に外部ユーザーや顧客が直接利用するシステムでは、障害がブランドや収益に影響を与えるため、SREの価値が大きく発揮されます。
・オンライン決済システム
決済処理では、1秒の遅延やエラーが信用損失につながります。SREでは、冗長構成や継続的な負荷テストを通じて高い可用性を確保します。
・物流システム
配送トラッキングや倉庫管理システムでは、リアルタイム性が重要です。分散システムの監視や障害発生時の迅速な切り替えをSREのアプローチで実現できます。
2-3. クラウドネイティブなシステム
クラウド技術を採用している場合、SREの手法は特に効果的です。
・コンテナオーケストレーション
Kubernetesなどのオーケストレーションツールを使用している場合、SREによる自動化が効果を発揮します。Podのスケールアウト/スケールインやフェイルオーバーの最適化がその一例です。
・サーバレスアーキテクチャ
サーバレス環境(例: AWS Lambda、Google Cloud Functions)では、オンデマンドでスケールする仕組みがあるため、SREによるモニタリングやパフォーマンス最適化が重要です。
3.SREの効果を引き出すための技術的な要件
3-1.明確なSLO/SLIの設定
SREの導入は、信頼性目標(SLO: Service Level Objective)が明確であるほど効果を発揮します。
SLO/SLI設定の具体例
・応答時間
Webアプリの応答時間を「95%のリクエストが200ms以下」と設定し、これをSLIで定量的にモニタリング。
・エラー率
APIリクエストの成功率を99.95%以上に保つ目標を設定し、これを監視ツールで追跡。
・ダウンタイム
月間許容ダウンタイムを「43.2分以内」(99.9%稼働)と設定し、エラーバジェットに基づいて適切な運用を実現。
3-2.モニタリングとアラートの強化
システムの信頼性を向上させるには、リアルタイムのモニタリングと自動アラートの整備が必要です。
使用可能なツール例
・インフラ監視
Prometheus、Zabbix、Datadogなどを活用し、CPU使用率やディスクI/Oを監視。
・アプリケーション監視
New RelicやAppDynamicsでトランザクション応答時間を可視化。
・ログ管理
ElasticsearchやSplunkでエラーログの集中管理と迅速な検索。
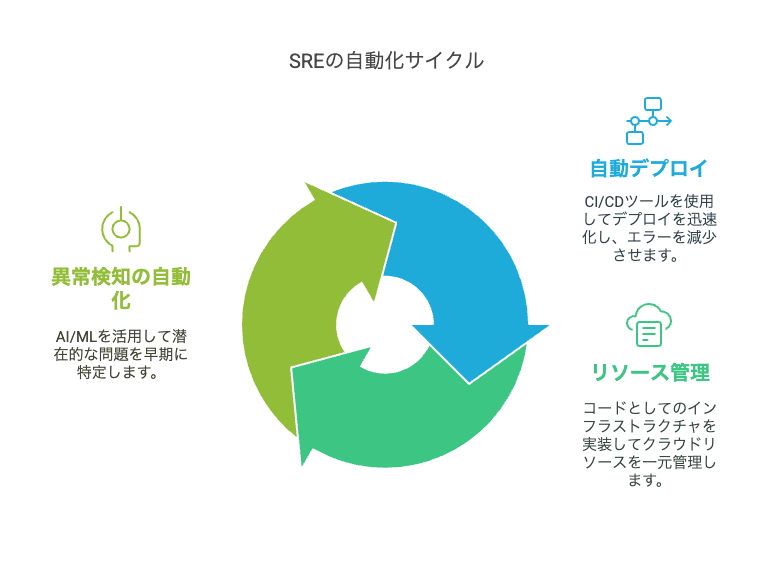
3-3. 自動化の推進
SREの効果を引き出すには、運用タスクを極力自動化することが重要です。
・自動デプロイ
CI/CDツール(例: Jenkins、GitLab CI)を使い、デプロイメントの迅速化とエラー削減を実現。
・リソース管理
Infrastructure as Code(例: Terraform、Ansible)でクラウドリソースの一元管理を行い、変更のトレーサビリティを確保。
・異常検知の自動化
AI/MLを活用した異常検知(例: DatadogのAnomaly Detection)で、潜在的な問題を早期に特定。
4. SREが効果を発揮する環境の整備
4-1.文化とプロセスの改革
SREは単なる技術ではなく、文化改革でもあります。システム企画部門が率先して以下を推進することが重要です。
・開発と運用の連携(DevOps)
システムダウンは顧客の信頼を損ない、ブランドイメージに悪影響を与えます。SREがシステムの安定稼働を支えることで、顧客離れのリスクを最小限に抑えられます。
・障害を許容する文化
「障害ゼロ」ではなく、エラーバジェットを活用し、許容範囲内での失敗を容認する仕組みを導入します。
4-2.段階的導入のすすめ
SREを全社的に導入する前に、次のような段階的なアプローチを取ることを推奨します。
・パイロットプロジェクトを設定
特に影響度の高いシステムや新規プロジェクトに限定してSREの実験的導入を行います。
・成功事例の展開
成果をもとに他のシステムへ展開し、組織全体での運用改善を目指します。
4-3.コストとROIの評価
SREの導入には初期投資が必要です。システム企画担当者としては、コストと効果のバランスを見極めることが大切です。
主なコスト要因:
・ツールライセンス
・エンジニアのトレーニング
・文化改革に必要な時間とリソース
投資効果の測定例
・障害発生時の復旧時間(MTTR: Mean Time to Recovery)の短縮。
・予定外のダウンタイムの減少による業務への影響削減。
・顧客満足度や信頼性向上による利益拡大。
5. 導入事例:ある企業システムへのSRE適用例
背景
ある製造業の企業では、クラウド上に顧客注文管理システムを構築していました。しかし、頻繁に発生するサーバ負荷問題とダウンタイムにより、顧客クレームが急増していました。
対応内容
1.SLOの定義
「95%のリクエストを1秒以内に処理する」という目標を設定。
2.監視とアラートの導入
Datadogでシステム全体をリアルタイムで監視し、CPUスパイク時にアラートを発生。
3.スケーリングの自動化
Kubernetesを利用して、トラフィック増加時にコンテナを自動スケール。
結果
・ダウンタイムが月間2時間から10分以下に減少。
・顧客満足度が15%向上。
・システム運用コストが10%削減。
6. まとめ
SREは特定の条件下で大きな効果を発揮するアプローチですが、すべてのシステムに適用すべきとは限りません。自社システムの特徴を分析し、SREの導入が適切かどうかを慎重に判断する必要があります。 リスクの少ないはじめ方として、パイロットプロジェクトを設定し、段階的にSREの導入を進めることで、リスクを抑えながら効果を最大化できます。
X(旧Twitter)・Facebookで定期的に情報発信しています!
Follow @acceluniverse