DEVELOPER’s BLOG
技術ブログ
機械学習活用事例|口コミ分析で顧客満足度向上

SNS、口コミでの評価と顧客満足度は深い関係があります。
今回は「ネガポジ判定」を用いて、顧客の要望を発掘していきます。
目次
- ネガポジ判定とは
- 実装方法
- 今後の検討方針
- 参考文献
1.ネガポジ判定とは
自然言語処理分野に関する文章のネガポジ判定とは、AIが文章の内容がネガティブかポジティブか判定するものです。
今回は食べログからスクレイピングによって口コミ(お店の評価)を抽出し、それらを実際にネガポジ判定します。
判定結果、特にネガティブと判定されたものは、顧客満足度向上に役立ちます。この技術は、既存のデータを分析し二次活用していくために有効な手法です。
Sentiment Analysisライブラリ oseti
今回のネガポジ判定には oseti というライブラリを使用しました。
osetiは日本語評価極性辞書を用いて文の評価極性(ネガポジ)のスコアを計算します。このライブラリのリンクは参考文献に載せておきます。
例えば、以下の3つの文章でosetiを使います。
import oseti
analyzer = oseti.Analyzer()
analyzer.analyze('店員の態度は悪かった。')
==>[-1.0]
analyzer.analyze('ここのラーメンは美味しかった。')
==>[1.0]
analyzer.analyze('店員の態度は悪かったが、ここのラーメンは美味しかった。')
==>[0.0]
このように、osetiは極性を判定するキーワードに対しポジなら「+1」、ネガなら「-1」とスコアリングします。キーワードが複数ある場合はそれらのスコアの和の平均を出力します。また、osetiは1文ごとにスコアを出力し、文章を入力した場合は1文ごとにスコアを出していきます。
2.実装方法
事前準備【食べログから口コミのスクレイピング(抽出)】
では本題に入る前に、実際に食べログから口コミをある程度スクレイピングします。
スクレイピングする対象として、今回は東京都の渋谷(恵比寿,代官山含む)と池袋(早稲田,高田馬場含む)にあるラーメン屋を選択しました。
理由は、2つあります。
1.他の店舗間で値段の差がほぼないため、シンプルに味で口コミの評価が二分されると感じた
2.弊社が渋谷にあるのでどういうお店が評価が高いのか興味がある
そこで渋谷と池袋それぞれ、 評価が3.5以上のお店40件、それぞれの店舗から20件ずつ 計1600件(800×2)の口コミをスクレイピングしました。
スクレイピングの結果の一部です。


scoreは食べログの評価、reviewcntはその店舗の口コミの件数で、著作権の関係上、店舗の名前storename、評価reviewは消してあります。このような形でそれぞれのデータをcsvファイルとして保存します。
さて、準備は整ったので早速osetiを使ってネガポジ判定していきましょう。
判定
まず、csvファイルのreviewに入っている文章を全てosetiに入力します。
#ネガポジ判定
def negaposi(text):
review = analyzer.analyze(text)
re_view= np.average(review)
return re_view
#ネガポジ判定値追加
shibuya_ramen_review ['negaposi'] = shibuya_ramen_review['review'].map(negaposi)
ikebukuro_ramen_review ['negaposi'] = shibuya_ramen_review['review'].map(negaposi)
出力は次のようになります。一番右のnegaposiの欄が判定スコアで、1文ずつのスコアの平均値を出しています。値が1に近ければよりポジティブであると考えられます。


しかし、上の結果を見てみるとスコアは正の値となっていますが、極端に1に近いとは言えません。
例えば渋谷の1番上のスコア0.19444のレビューを見てみると(著作権の関係上載せれませんが)、スコア0.5は超えてもいいかなと思います。
文章全体を見てポジティブな内容であると分かっても、やはり文全体の平均を取っているので1に大きく近づきはしませんでした。なので、BERTなど文脈を読み取れるようなライブラリを用いた方が精度が上がりそうです。
全体としてポジティブに厳しい判定ではあったものの、ネガティブな内容をポジティブと誤判定することはなく、冒頭であげた「ネガティブな評価を見つける」、といった目的は達成できます。
N-gramによる頻出単語の可視化
次に、N-gramによってテキストを単語ごとに分割し、頻出単語を見ていきます。
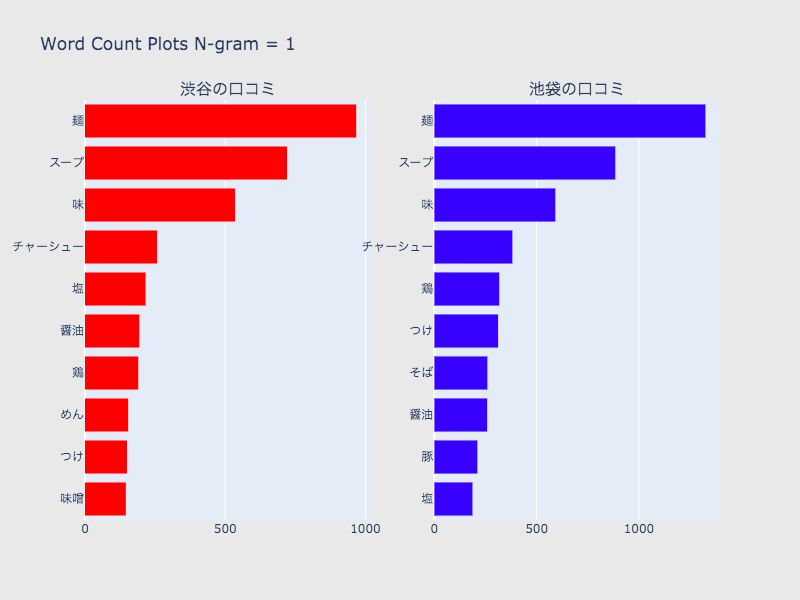
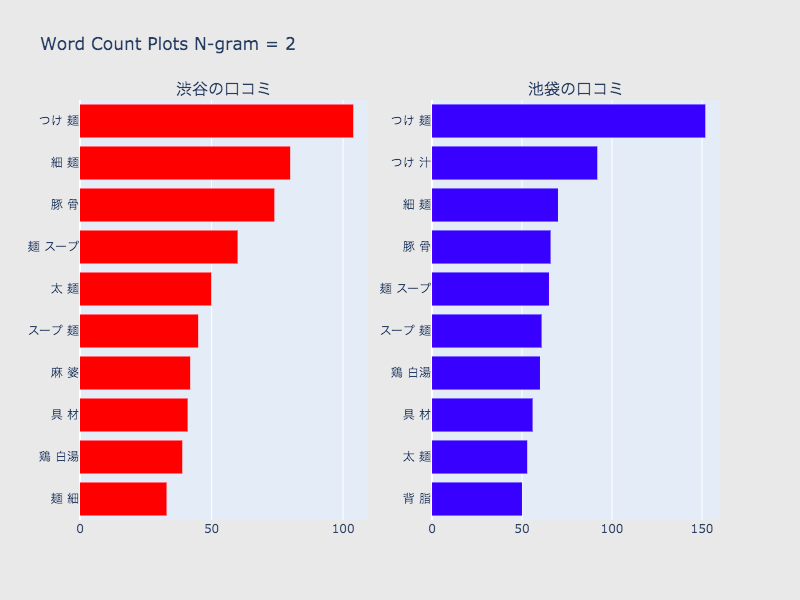
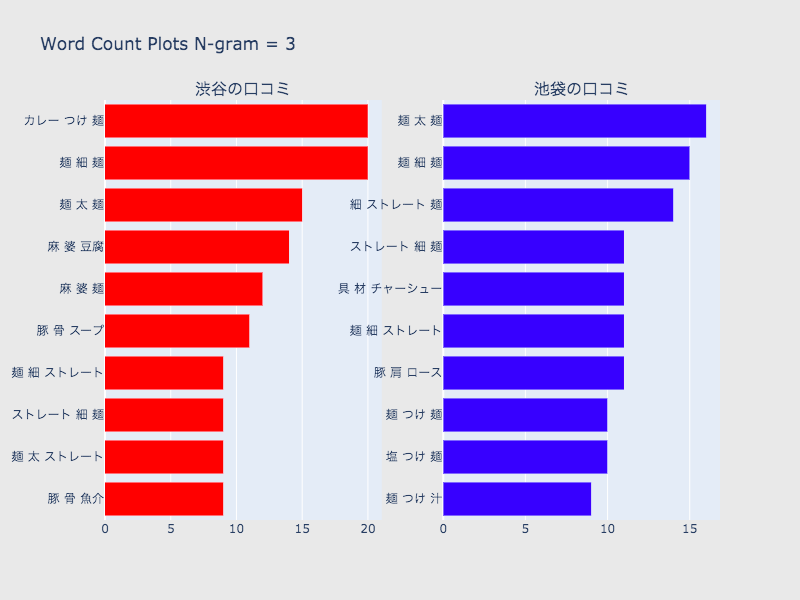
今回ポジティブ判定されたラーメン屋の傾向が何となく分かります。
1、2、3の比較
- 1では、麺などラーメン屋の口コミとしては当たり前に出てくる単語が上位に来てしまっているところは問題だが、味、麺、具材の種類を表す単語からは、池袋と渋谷を比較しても多少傾向が見られるので、ストップワードを工夫することで大まかな傾向は掴めそう。
- 1は2、3と比べて一単語ずつの出現数が保証できる。
- 2、3は1より具体的な麺、味の種類が出てくるため、より特徴的なワードを掴める。また、1よりも池袋、渋谷の差を確認しやすい。
- しかし、一つ一つの出現数は少なくなるので、データの吟味が必要。
- 2と3で入れ替わるワードもあり、両方のデータを考察する必要がある。
3.今後の検討方針
今回感情分析の手法(ライブラリ)としてosetiを用いましたが、単語の極性だけを見てもかなりの精度でネガポジ判定ができることがわかりました。
しかし、このosetiにはいくつか問題点があります。
- 日本語評価極性辞書に載っていない単語が出現した際、それらを定量的に評価できない。
- 極性辞書の単語の評価には作成者の感情が入っているので、客観的な評価が完璧にできない。
- 1文ごとにネガポジ判定を行うので、文章全体で見たときに文脈を読み取れない。
これらが原因で、ポジティブな口コミをネガティブ寄りと誤判定したり、その逆の判定をしてしまう時もありました。
日々日本語は増えていくし、ニュアンスもそれに伴って変化していきます。人手で作る極性辞書にも限界があるので、今回はそこがボトルネックとなっていました。
3の問題点を改善するために、今後の検討ではBERTを用いて文章の感情分析を行いたいと思います。
また、単語の出現数だけを見て、ある程度の傾向は感覚的に掴めますが、単語同士の繋がりや、その単語がポジティブへ関係しているか明確ではありません。そのため係り受け解析をするなどが必要だと考えています。
全部の文章からだとその店に対する評価をしている文以外も入ってくるので、そこの取捨選択ができれば、評価されている部分と批判されている部分がより明確になると思っています。
4.参考文献
日本語評価極性辞書を利用したPython用Sentiment Analysisライブラリ oseti
【初学者向け】TFIDFについて簡単にまとめてみた
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数