DEVELOPER’s BLOG
技術ブログ
テキストマイニングで機械学習論文のトレンドを発見する方法

概要
AI技術の発展が進み、今や私たちの身の回りでも当たり前のようにAIが生活をより便利にしてくれています。この夢のような技術を支えているのは研究者の方たちによる地道な努力です。では、最近はどのような研究が行われているのでしょうか?
研究の成果は論文という形で公開されますが、世界中で活発に研究されているAI関連の論文は1日に数十~百本もの論文が出ています。そのためこれらの論文を読んで最新の研究動向をつかむことは難しいでしょう。
そこで今回はテキストマイニングと呼ばれる技術を用いて20年前から現在までに出版された大量の論文を自動で分析し、大まかでよいので、今流行っている研究や過去のトレンドを調べてみたいと思います。
目次
テキストマイニング
テキストマイニングって?
インターネットやSNSが発達し、個人が自分の考えを自由に発信できる今、膨大な量の文章データがネット上に集積していきます。こういった「生の」情報を集めることは簡単ですが、この中から本当に意味のある情報を引き出すことは容易ではありません。例えば数値データであるならば、平均値を求めたりすることで、大体の状況を把握することができますが、文章の場合にはこういった処理ができないからです。
テキスト(文章)マイニング(採掘)は、こういった問題に対処する一つの方法で、「膨大な文章の中から自分にとって価値のある情報を抽出する技術」のことです。最近よく見かける、ワードクラウド(下の図)もテキストマイニングを用いたものです。

一体どのような方法で文章から情報を抽出するのでしょうか?
それを見る前に、テキストマイニングの便利さを実感するために1つ例を考えてみます。
仮に洋服屋に勤務しているとして、売り上げがなかなか伸びなかったとします。あなたはその原因を探るべく、お客様アンケートを行いました。
従来の方法では
Q、品ぞろえに満足していますか?
- 満足
- 普通
- 不満
のように選択式でないと定量的に扱うことができず、さらにセーターの品ぞろえが悪いのか、パーカーの品ぞろえが悪いのか、あるいはそれ以外なのか、区別がつきません。
これでは質問を作るのは手間だし、的確な情報も得ることは難しいです。
テキストマイニングを使えば、
Q、品ぞろえに関して不満な点はありますか?
のような自由記述で回答してもらい、これを分析にかけることで、「パーカー」「品ぞろえ」「悪い」といった大まかな回答の傾向をつかむことができ、適切な対処をとることができるでしょう。
このような利点からテキストマイニングは、SNSを対象にした商品のレビュー調査、新聞記事を対象にした社会学、対話型AI等、様々な用途に利用されいます。膨大なデータから何か新しい情報を抽出したい際にきっと強力な道具となるはずです。
分析方法
ここではテキストマイニングの流れについて説明したいと思います。あくまでテキストマイニングを利用した分析を述べることが主眼なので統計学的な詳細については省略します。
例として、2019年9月に環境活動家のグレタ・トゥンベリさんが国連で行ったスピーチの一部を見てみましょう。
This is all wrong. I shouldn't be up here. I should be back in school on the other side of the ocean. Yet you all come to us, young people, for hope? How dare you! You have stolen my dreams and my childhood with your empty words. And yet I'm one of the lucky ones. People are suffering. People are dying. Entire ecosystems are collapsing. We are in the beginning of a mass extinction. And all you can talk about is money and fairytales of eternal economic growth. How dare you!
このスピーチは環境問題に真剣に取り組まない各国の首脳らに向けた怒りのメッセージで、" How dare you! "「よくもそんなことができるものだ!」というフレーズが特徴的で話題を集めました。実際このフレーズは全スピーチ中で4回繰り返されています。
このスピーチ全文を分析にかけた場合には、ネガポジ分析(テキストマイニングを利用した分析の一つで、その文章全体がネガティブな内容なのか、ポジティブな内容なのかを判断する)では「ネガティブ」と判断され、よく出てくる単語として dareや, air (大気), fail (失敗する), solution (解決策), emission (排出)のような環境問題系の言葉が現れるはずです。また、語同士のつながりは、How, dare, you の3語のつながりが明確に出るはずです。
それでは分析の流れを順を追って説明していきます。(実際にはソフトの「実行」ボタン一つで完了します)
1、まず、文章を一文ごとに区切ります。英語の場合はピリオド(.)で区切ればよいのですが、 U.S.A や Mr. Tanaka のような例外もあるので、こういった例外を集めた一種の「辞書」が必要です。ソフトはこの「辞書」を参照しつつ全文を区切っていきます。今回用いるソフトウェアKH Coderではこの作業をPearlのモジュールを使って行っているようです。
例えば上のスピーチの一文
I shouldn't be up here. 私は今ここにいるべきじゃない 。
をとってきたとしましょう。
2、区切った一文を今度は単語ごとに区切ります。英語の場合スペースで区切ればよいです。ただし shouldn't = should not のような例外もあるので、これも「辞書」を参照しつつ行います。
上の例では
I, should, not, be, up, here
となります。
3,取り出した単語一つ一つについて、基本形に直します。過去形を現在形に直したり、複数形を単数形にしたりするということです。そうすることで cars と car 等の二種類の単語を一つにまとめて扱うことができ、分析が楽になるからです。この作業をステミング(stemming)と呼びます。これにも「辞書」が必要です。英語の場合には "Stanford POS Tagger"、 "FreeLing"、 "SnowBall" といった辞書が公開されています。今回は2、および3の作業には "Standard POS Tagger"を用います。
この作業を行うと上の例では
I, shell, not, be, up, here
となります。
4,次に stop word を削除します。これは英語の場合 be動詞や前置詞など、どんな文章にも頻繁に現れる、重要ではない語のことです。何をstop word とするかは分析者が自分で定義します。
上の例では
not, here
のようになるかもしれませんし、何も残らないかもしれません。
5,ここまでの作業はどのテキストマイニングのソフトにも共通の前処理でした。ここからどのように分析を行っていくのかがそのソフトの特徴となります。分析の方向性には以下のように大きく二つあります。
- 分析者があらかじめ指定した単語を中心にコンピュータが分析する手法
- 例えば地球温暖化についての新聞記事を対象としている際に、分析者が「火力発電」という切り口で分析を進めたい場合、コンピューターは指定された「火力発電」を含む文章を集め、多変量解析の手法で分析します。(単語の出現回数を数えたり、一緒に現れやすい単語の組を探したりします)
- 分析者の問題意識が反映されやすい一方で、客観性に問題があるかもしれません。
- 分析者が何の条件も指定せず、バイアスなしでコンピュータが分析する手法
- 初めから全データをコンピュータが多変量解析の手法で分析し、得られた結果から何が言えるのかを考えます。
- 上の例だと、地球温暖化に関する記事を全て分析にかけ、その中で「火力発電」がどのくらいのウエイトを占めているのかなどを調べます。
- 結果があいまいになる(ほかのデータの中に埋もれやすい)恐れがある一方で客観性は保証されます。
今回用いるKH Coderはどちらのアプローチでも分析できるのが特徴です。
実際に後者の方法で上のスピーチ全文についての分析を行い、「共起ネットワーク」(語の出現回数を丸の大きさで表し、語同士のつながりを線の太さで表した図)を描いたものが次の図です。
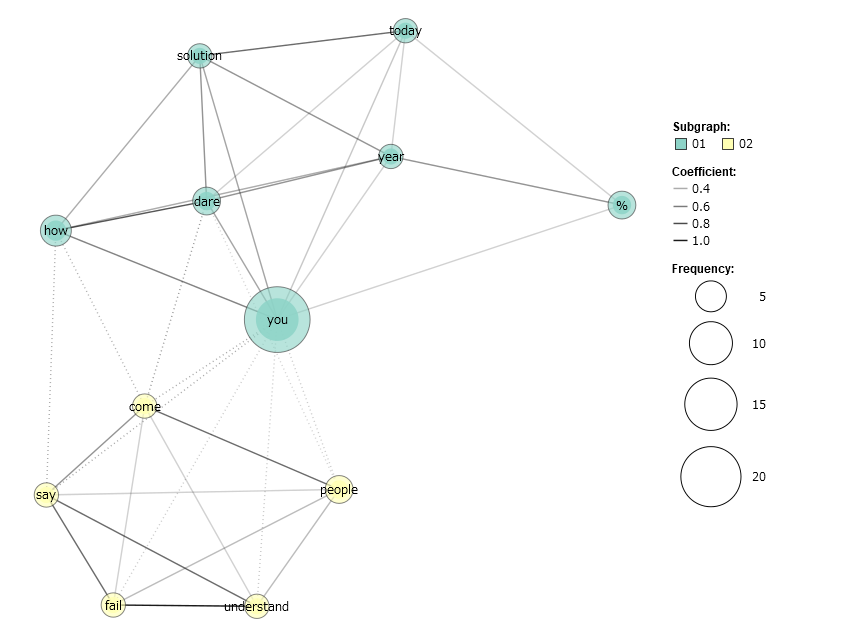
中心付近で、 How, dare, youの3語が強く結びついているのが分かります。ただ、頻出の単語は come, people, say 等、環境問題特有のものではなく、一般的に多くの文章でよく使う単語が目立ちます。このスピーチは短いのでまだマシですが、大量の文章を分析するとこの傾向がさらに強まると考えられます。そのため、こういった単語はstop wordにしてしまうか、あるいは表示する単語の出現回数に上限を設けるなどの対策が必要です。
データの収集
arXiv
論文の収集には、物理、数学、情報科学といった分野の論文が保存・公開されている、arXivというサイトを使います。arXivは時間のかかる査読(提出した論文を他の専門家がチェックする過程)を経ずに論文を無料で投稿できるため、多くの論文が集積しています。今回は分野を機械学習分野に絞り、論文の最初に書かれている、Summary(要約)を集めて分析したいと思います。Summaryは短いので大量の論文から集めても計算時間がそれほど長くはならず、また論文全体の内容が凝縮されているので、機械学習に関係のない単語の割合が少なく、分析しやすいと考えたからです。
スクレイピング
大量の論文を集めるにはスクレイピングという手法を用います。いちいち自分で該当するwebサイトにアクセスせずに、自動でダウンロードしてくれる便利な方法です。arXivはスクレイピング用のAPIを用意してくれているのでこれを利用します。今回は2019年、2018年、2017年、2016年、~2009年、~1999年に出版された論文を集めます。
※以下のコードは Google Colaboratory で動作確認済みです。
まずは必要なライブラリをインポートします。
import arxiv import pandas as pd
※ arxivが入っていない場合は、次のように打ってインストールしてください。
! pip install arxiv
このarxivというAPIを使えば、検索条件を指定するだけで自動で論文名、著者、日付、要約などをダウンロードできます。
今回は、「機械学習分野(LG)で2019年に出版されたもののうち、最大10,000件を提出日の新しい順に」取得します。それが以下のコードです。
latestQuery = arxiv.query(query='cs.LG AND submittedDate:[20190101 TO 20191231]', max_results=10000, sort_by='submittedDate', sort_order='descending')
得られるデータは辞書形式で見にくいのでデータフレーム形式(エクセルのような表形式)に直します。
df_latest = pd.io.json.json_normalize(latestQuery) print(df_latest)
以下のような表が得られます。
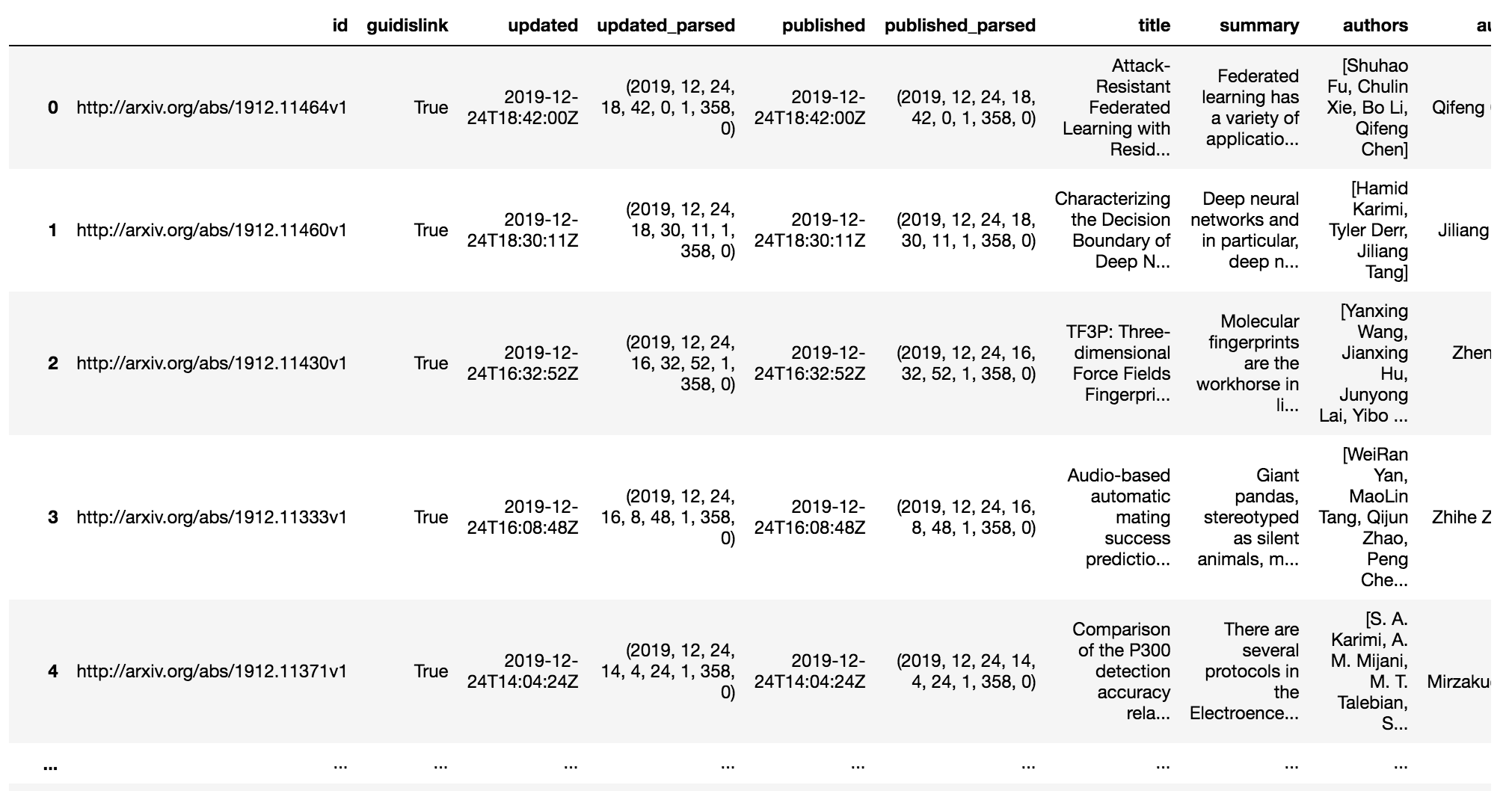
ここから Summary(要約)だけ取り出します。
df_latest_s = df_latest[['summary']] df_latest_s.index.name='index' #後でつかうソフトに合わせるためのもので特に意味はありません。
最後に、得られたデータを同じディレクトリにcsvファイルとして保存します。
df_latest_s.to_csv('./latest_data.csv')
全く同様に、2018年、2017年...の論文を集めます。
# 検索条件を指定
oneoldQuery = arxiv.query(query='cs.LG AND submittedDate:[20180101 TO 20181231]', max_results=10000, sort_by='submittedDate', sort_order='descending')
twooldQuery = arxiv.query(query='cs.LG AND submittedDate:[20170101 TO 20171231]', max_results=10000, sort_by='submittedDate', sort_order='descending')
throldQuery = arxiv.query(query='cs.LG AND submittedDate:[20160101 TO 20161231]', max_results=10000, sort_by='submittedDate', sort_order='descending')
tenoldQuery = arxiv.query(query='cs.LG AND submittedDate:[20000101 TO 20091231]', max_results=10000, sort_by='submittedDate', sort_order='descending')
tweoldQuery = arxiv.query(query='cs.LG AND submittedDate:[19900101 TO 19991231]', max_results=10000, sort_by='submittedDate', sort_order='descending')
# データフレーム型に変換
df_oneold = pd.io.json.json_normalize(oneoldQuery)
df_twoold = pd.io.json.json_normalize(twooldQuery)
df_throld = pd.io.json.json_normalize(throldQuery)
df_tenold = pd.io.json.json_normalize(tenoldQuery)
df_tweold = pd.io.json.json_normalize(tweoldQuery)
# Summaryだけ抜き取る
df_oneold_s = df_oneold[['summary']]
df_oneold_s.index.name='index'
df_twoold_s = df_twoold[['summary']]
df_twoold_s.index.name='index'
df_throld_s = df_throld[['summary']]
df_throld_s.index.name='index'
df_tenold_s = df_tenold[['summary']]
df_tenold_s.index.name='index'
df_tweold_s = df_tweold[['summary']]
df_tweold_s.index.name='index'
# csvファイルに保存
df_oneold_s.to_csv('./oneold_data.csv')
df_twoold_s.to_csv('./twoold_data.csv')
df_throld_s.to_csv('./throld_data.csv')
df_tenold_s.to_csv('./tenold_data.csv')
df_tweold_s.to_csv('./tweold_data.csv')
これでデータの準備は整いました。なお2009年、1999年に出版された論文は少なすぎたので、前10年分をとりました。
分析
今回テキストマイニングに用いるソフトはKH Coderです。これは日本人の方が開発されたソフトで、英語だけでなく日本語や中国語にも対応しています。
KH Coderのインストール
ここからダウンロードできます。Windowsの場合はダウンロードしたファイルを実行するだけですが、MacやLinuxの場合、MySQLやPearl、Rの設定などを自分で行わなければいけないので環境構築が大変です(インストールを自動化してくれる有償サポートもあります)。基本的には このサイト に従えばよいですが、それでもエラーが頻発すると思います(私はいやというほどしました)。どうしても解決しない場合は、製作者の方が質問を受け付けてくださっているので ここで質問してみるのも手です。
私が詰まったエラーを二つ書いておきます。
・MySQLの「LOAD DATA LOCAL INFILE」コマンドでエラー

↓エラーメッセージ
SQL Input:
LOAD DATA LOCAL INFILE '/Applications/khcoder-master/config/khc26/khc26_ch.txt' INTO TABLE rowdata CHARACTER SET utf8mb4
Error:
The used command is not allowed with this MySQL version
```
これはKH Coderの開発時からMySQLのバージョンが新しくなったことによる問題です。まずターミナルで
mysql -uroot
と打ってMySQLにログインします。その状態で次のようにコマンドを打てば解決するはずです。
SET PERSIST local_infile= 1;
・MySQLの「GROUP BY」でエラー

↓エラーメッセージ
SQL Input:
INSERT INTO hgh2 (genkei, sum, h_id, h_name)
SELECT hgh.genkei, SUM(num), hinshi.id, hinshi.name
FROM hgh, hinshi
WHERE hgh.hinshi=hinshi.name
GROUP BY hgh.genkei, hgh.hinshi
Error:
Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'khc25.hinshi.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
```
これも 開発時からMySQLのバージョンが更新されたことによる問題です。MySQLにログインした状態で以下のコマンドを打てば解決します。
mysql> set global sql_mode=(selectreplace(@@sql_mode,'only_full_group_by',''));
KH Coderの設定
上述したように、文章から単語を取り出して基本形に直すには「辞書」が必要です。また、stop wordの削除を行うには、自分でstop wordを定義しなければいけません。
まず、今回使う辞書 "Standard POS Tagger" をダウンロードして適当な場所に保存しましょう。ここからダウンロードします。
KH Coder のメニューバーから、【プロジェクト】→【設定】→【語を抽出する方法】→【Standard POS Tagger】→【*. TAGGER file path】に先ほど保存した場所を指定します。また、同時に【Stop words】も定義します。KH Coderをダウンロードしたときに一緒にダウンロードされる、sample fileをそのままコピペすればよいでしょう。
また、【その他】の「前処理効率化のためにデータをRAMに読み出すを選択しておくと前処理が早くなるのでチェックしておくと良いです。
前処理の実行
設定が終われば、【プロジェクト】→【新規】から先ほどスクレイピングで集めたファイルを指定します。「分析対象とする列」にはindexではなく、 **summaryを指定** するようにしましょう。また「言語」は英語、Standard POS Tagger となっていることも確認しましょう。
次に前処理をします。メニューバーから【前処理】→【前処理の実行】を押し、現れるダイアログは「OK」を選択し、しばらく待ちます(私の場合1~10分ほどでした。)
初めのうちはここで山ほどエラーが出ると思いますが一つ一つつぶしていきましょう。
結果
結果の表示にはその分析法に応じて複数の描画の方法があります。「対応分析」と「共起ネットワーク」が視覚的にわかりやすいので今回はこれを使いました。他にも多くの方法があるので詳しくはKH Coderのマニュアルを参照しましょう。マニュアルは、メニューバーから【ヘルプ】→【マニュアル】で見ることができます。
まずは、古い順に共起ネットワークを描いていきます。共起ネットワークは、語の出現回数を丸の大きさで表し、語同士のつながりを線で表しています。また、語の色分けについては、「サブグラフ検出」と呼ばれる方法で比較的強くお互いに結びついている部分を自動で検出してグループ分けを行った結果です。ただし、マニュアルにも書かれている通り、
あくまで機械的な処理の結果であるから,色分けには必ず重要な意味があるはずだと考えて深読みをするのではなく,グラフを解釈する際の
補助として利用することが穏当であろう
とのことなので注意します。
語同士のつながりには実線と破線がありますが、同じサブグラフに属する語同士は実線、そうでなければ破線という意味です。
まずは一番古い1990 - 1999年まで(実際にあったのは1997/12 - 1999/12)に出た全論文33本について分析を行ったのが以下の図です。
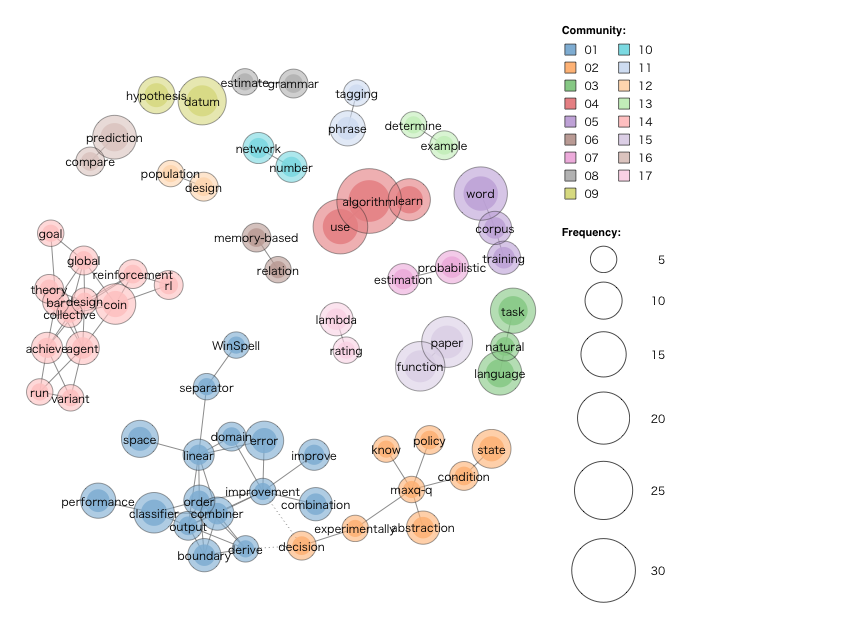
algorithmという単語が最もよく出てきていることからもわかるように、この時期は基礎的な研究が主だったことがうかがえます。
reinforcement, agent, maxq, corpus, natural, language 等の単語から、強化学習や自然言語処理の研究がすでに始まっていたこともわかります。
続いて2000 - 2009年にかけて出版された全論文762本について分析したのが以下の図です。
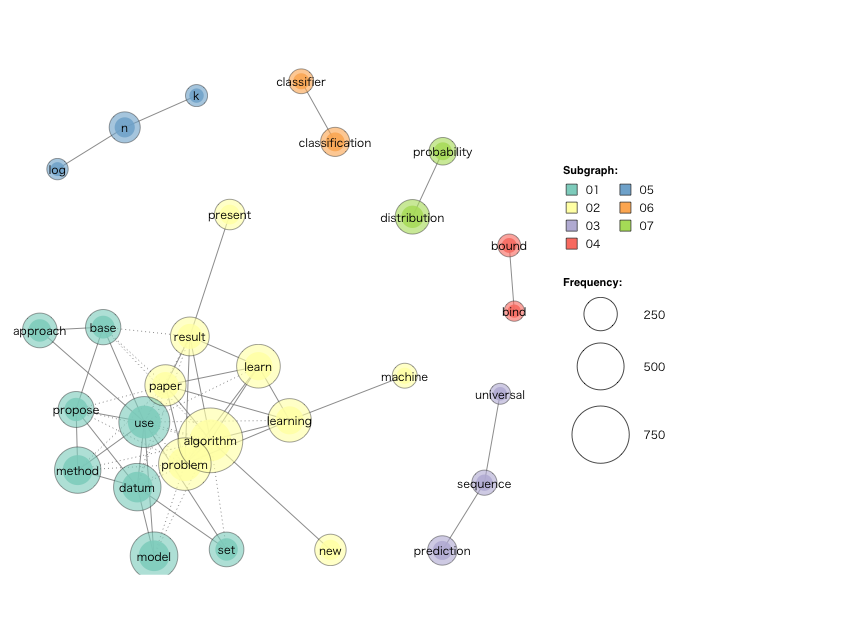
依然 algorithm が最頻出単語です。 vector - machine はいわゆる SVM(サポートベクターマシン)、 decision - tree は決定木、 classification = 分類、など今につながる具体的な手法が目につきます。 time - algorithm や、 model - learning のつながりが現れたことから、機械学習の原理の研究から、現実的な問題解決の方法論へと研究が移行していったのがこの時期だと考えられます。
続いて2016年に出版された全論文3568本について分析した結果が以下です。
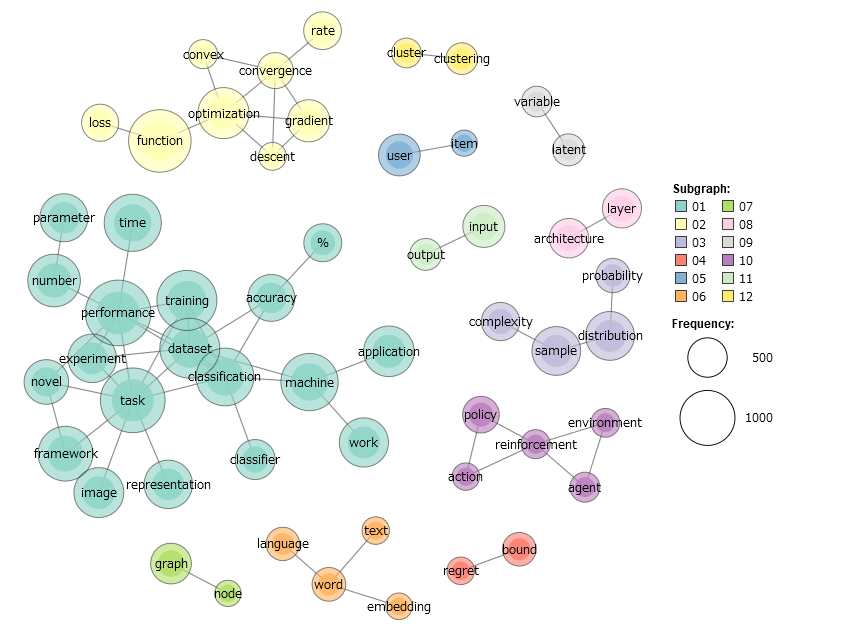
上述のように機械学習に関係のない語をはじくために、出現回数が100回以上1500回以下の単語に絞って書いてあります。この対処法は感覚的なもので、これが最も適切な処理である根拠はありません。実際機械学習の中心的な単語であるはずの algorithm や model が出てきていないのは出現回数が大きすぎたためです。これがテキスト分析の難しいところですが、これ以上ソフトで分析を進めるのは難しいので、あとは注意深く結果を見て、何かしらの傾向をつかめるように頑張ります。
左にある緑色の大きなグループは、 task を中心として image, classification, dataset, frameworkのような単語が並んでいることから、画像分類の内容であると推測できます。ディープラーニングによって画像分類の精度が飛躍的に高まり、話題を集めたのが2012年のことなので、これは比較的新しい話題で、研究のフロンティアだったのだと考えられます。
右の方には reinforcementを中心にした強化学習、下の方には wordを中心にした自然言語処理が20年前から依然としてあり、この二分野は長らく、よく研究されていることが言えます。
上の方には optimization(最適化), gradient(勾配)などのやや基礎的な研究内容があります。
また、教師なし学習の代表格 clusteringも目につきます。
続いて2017年に出版された52381本の論文について。
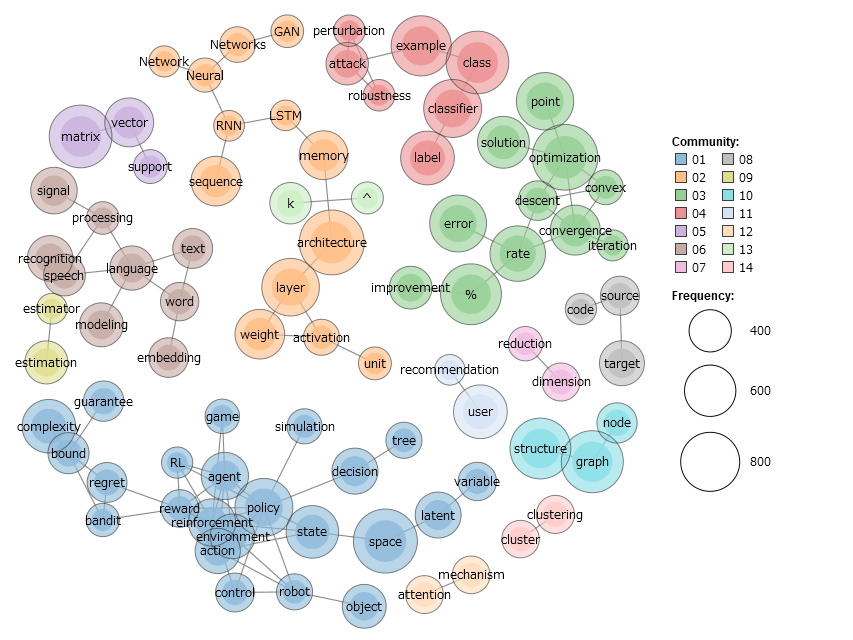
出現回数が200回以上1000回以下の単語に絞った描画です。
この年に特徴的なのは、reinforcementを中心とする強化学習に関連する単語群の出現数がほかの分野に比べて相対的にずっと多くなったことです。前年のグラフと比べてみれば一目瞭然です。
この時期に強化学習関連で目立ったことがあったのかどうか調べてみると...ありました!
2016年3月に GoogleのAlphaGoが韓国のトップ棋士李世乭さんに5番勝負で4勝1敗にて勝利し、2017年5月には中国のトップ棋士柯潔さんにも3局全勝を上げていました。ニュースでも大々的に取り上げられましたね。
将棋やチェスなど数あるボードゲームの中でも、囲碁はそのありうる盤面の数が際立って大きいです。そのためコンピュータの得意とする全探索手法が使えないために、人間に勝利することは難しいと考えられていたために、AIに詳しい人ほど、この対局は衝撃的だったのでしょう。これを機に研究者たちの中でも強化学習の可能性に注目が集まり、よく研究されるようになったのだと推測されます。
左上の方には RNN, LSTM, GAN といったディープラーニングに関する話題が多く出てきています。以前にもあったけれども、ほかの語に埋もれていたのかもしれないので、この時期にはやったのかどうかは何とも言えません。
左の方には language, textなどの自然言語処理の話題があり、前年に比べ相対的に大きくなっています。また、 speechが新たに自然言語処理に加わっているのも面白いですね。
続いて2018年に出版されたもののうち5600本(「うち」と書いているのは、APIの仕様のせいか、全ての論文を集めることができなかったためです)。
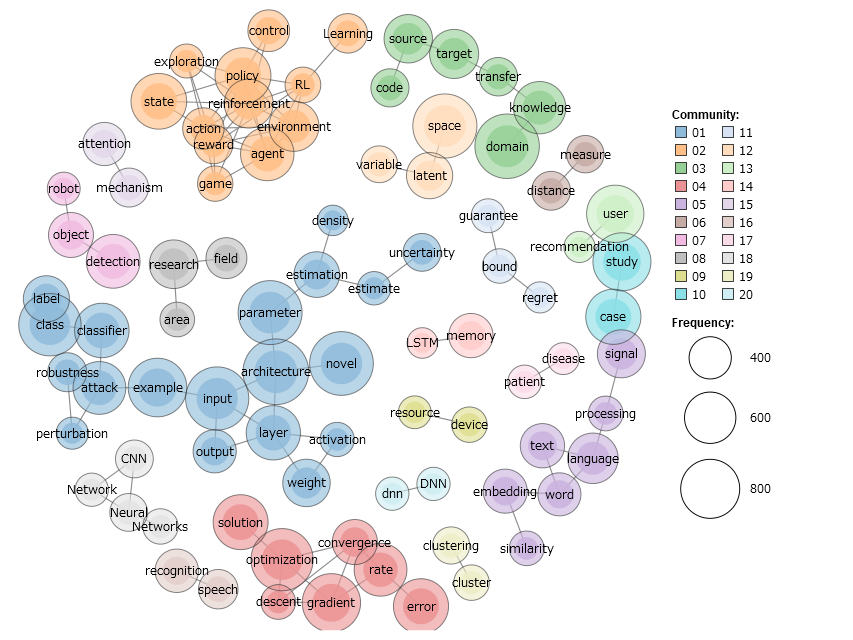
出現回数が200回以上1000回以下の単語に絞った描画です。
下の方にある optimization, gradientはアルゴリズムの研究のような基礎的な話題でしょう。
左の方にある青い大きなグループは layerがハブになっていて、また雑多な単語がつながっていることからディープニューラルネットワークを用いた応用的な話題かと思われます。
上の方にあるオレンジ色のグループは強化学習、右の方にある紫色のグループは自然言語処理の話題でしょう。
最後に2019年に出版されたもののうち3000本です。
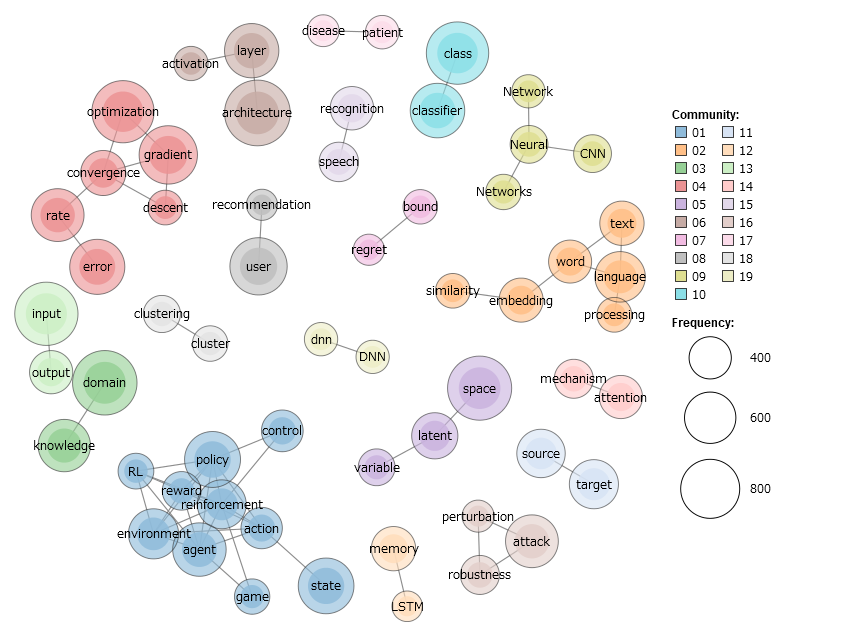
出現回数が200回以上1000回以下の単語に絞った描画です。
アルゴリズム(赤)、強化学習(青)、自然言語処理(オレンジ)、画像認識(黄緑)など、今よく聞く話題がよく研究されていることがわかります。また、突出して出現頻度が多い語はなく、色分けされたグループもだいたい同じ規模です。これが出現回数の制限によるものかどうか調べるため、試しに2000回以下、及び制限なしの場合に同じ図を描いたのが次の図です。
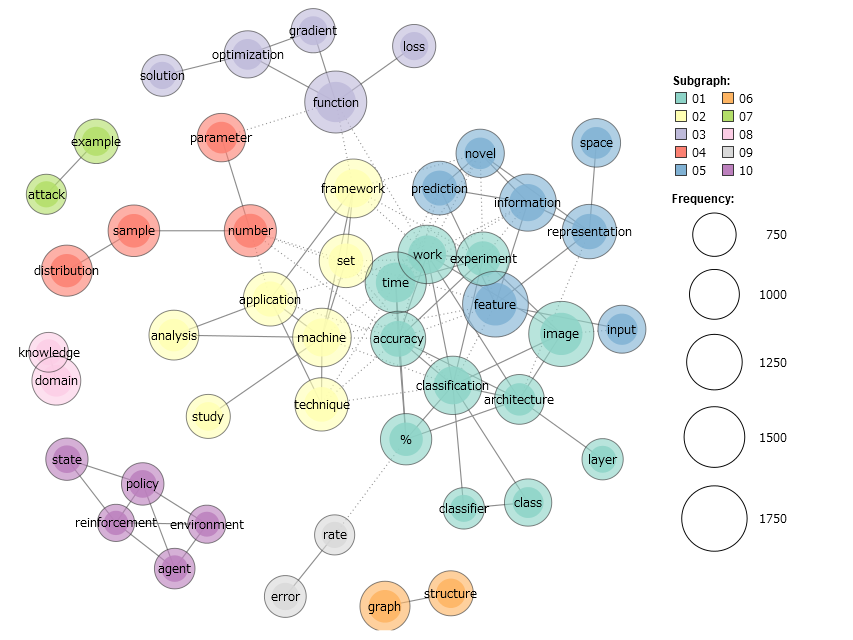
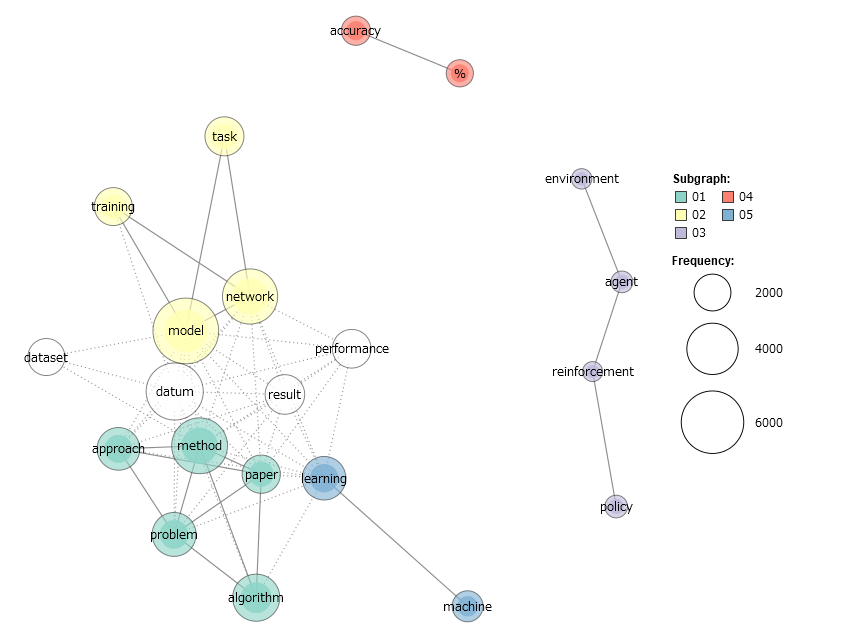
やはり同じ傾向が見られます。このことから、現在の研究は、アルゴリズム、強化学習、自然言語処理、画像認識がどれも活発に研究されていると言えるでしょう。
これまで出版年ごとに共起ネットワークを出してきました。各年ごとの特徴はよく分かるのですが、時間変化はわかりにくくなっています。
時間変化をメインに共起ネットワークを描くには、すべての論文データを出版年とSummaryだけ残して一つのCSVファイルに統合し、これを前処理します。そして共起ネットワークを描く際のオプションとして、「共起パターンの変化を探る(相関)」にチェックを入れます。こうすると、以下の図が得られます。
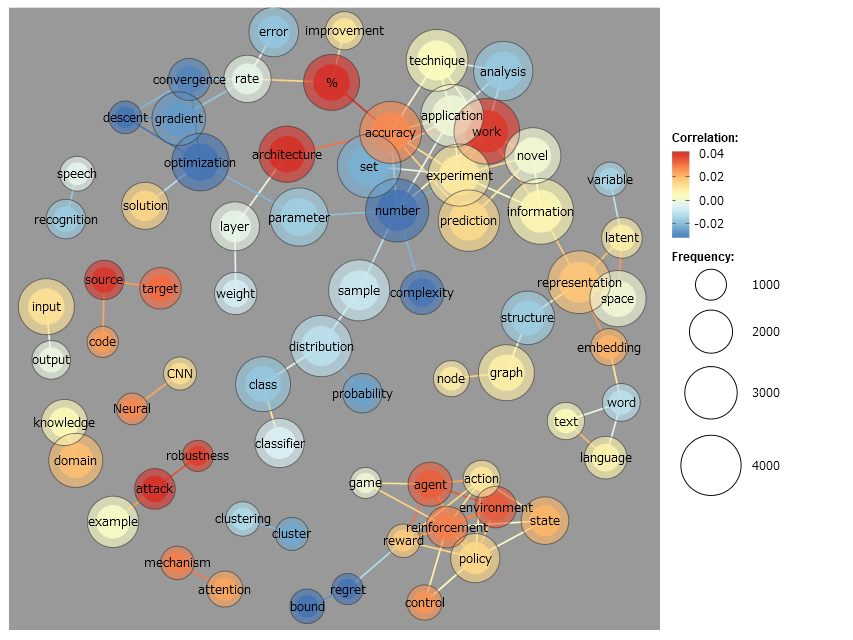
この図は、赤い線ほど、最近出版された論文に特徴的なつながり、青い線ほど古い論文に特徴的な論文に特徴的なつながりを表します。例えば、下の方にある rewardは古い論文では regretとよくつながっていましたが新しい論文では reinforcementとよくつながっているようです。これは強化学習における rewardに対する考え方が変化したことを表している可能性があります。
他にも、右の方にある languageは、よく共起する単語が wordから textへと変化していることもわかります。これは自然言語処理の発展により、研究対象が wordから textへと移り変わったことを示していると推測することもできます。
共起ネットワーク以外の表現方法もあります。以下の図は対応分析と呼ばれる手法を用いて分析した結果です。
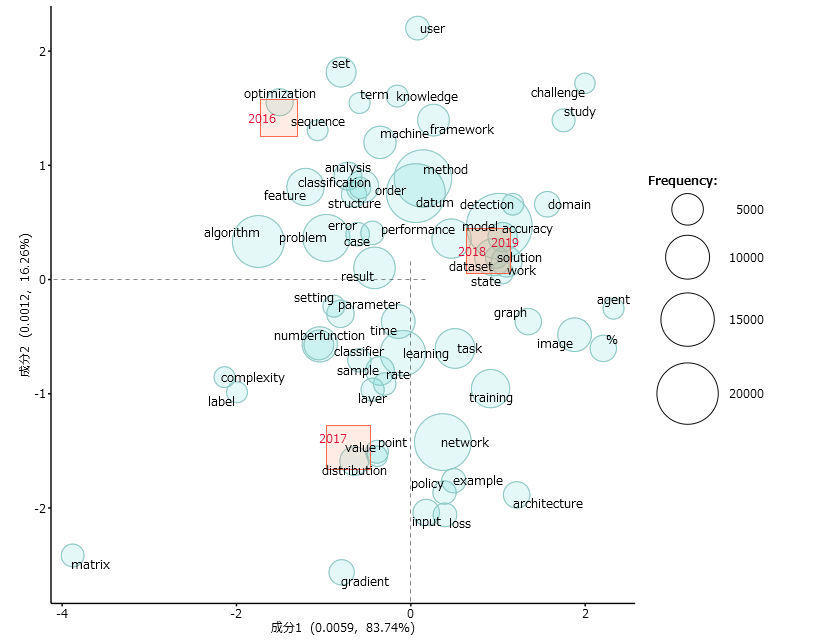
この図では出版年が書いてある赤四角の領域に近い言葉ほど、その年に特徴的な言葉であることを意味します。
例えば2018年と2019年の四角は領域がほとんどかぶっていて、出てくる主要な語に変化が少なかったことを意味します。ただ、出てきている語を見ると、 CNN, reinforcementのような機械学習の具体的な手法や分野を表す語がなく、抽象的な語ばかりなので、ここからトレンドの変化を探ることはできませんでした。描く対象になる語の出現回数を制限するなど、パラメータを適切な値にできればそういったことが可能であったかもしれません。
参考文献
- KH Coderのマニュアル
- https://ja.wikipedia.org/wiki/AlphaGo
- https://www.jstage.jst.go.jp/article/ojjams/19/1/19_1_101/_pdf
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数