DEVELOPER’s BLOG
技術ブログ
海洋エネルギー × 機械学習〜洋上風力発電の発電量予測〜

第1弾、第2弾に続き
- 第1弾:海洋エネルギー × 機械学習 〜普及に向けた課題と解決策〜
再生可能エネルギーの一つである海洋エネルギー発電の長所と課題とその解決策について触れた。
- 第2弾:海洋エネルギー × 機械学習 〜機械学習を利用した電力需要量予測による波力発電の制御〜
複数ある課題から「発電量と需要とのバランスが取りにくい」、「無駄な待機時間がある」を解決するために、電力需要量を予測を行った。必要な電力需要量が分かれば、その分量を発電できるように発電装置を制御すればよいので、この具体例として波力発電装置の制御を解説した。
今回は第1弾で取り上げたこちらを検討していく。
ここでの「発電量予測」とは、発電装置周辺の気象・海象データを説明変数として発電量を予測することである。電力は常に需要量と供給量(発電量)が同量でなければ、停電を起こしてしまう。それを防ぐために発電量が予測されていれば、需要と供給のバランスを保ちやすくなる。また発電装置の無駄な待機時間も削減され、設備稼働率も向上する。このようにして、課題①「電力需要量とのバランスが取りにくい」、課題③「無駄な待機運転の時間がある」を解決する。
更に第二弾で紹介した「電力需要量予測による制御」と組み合わせれば、発電量と需要量をより正確に一致させることができる。
今回は発電方法を洋上風力発電としてこの「発電量予測」を実装する。

目次
- データセットについて
- 予測モデルについて
- 精度の向上
- 結果・考察・課題
- 参考文献
1. データセットについて
1章でも述べたが、発電量予測は発電装置周辺の気象・海象データを説明変数とすべきだ。しかし、風速や天候などの気象データ、波高や波向などの海象データ、そして発電量の三つ揃ったデータセットを手に入れるには、造波装置を搭載する大型水槽での模型試験、または実海域での実証試験を行うしかない。大規模な装置を使わずに単純なモデルで模型試験を行い、そこからデータセットを得ようというアイデアもあるが、それは一度おいておき、今回は表1のようなデータの種類を用いることにした。表2がデータセットであり、2016年1月1日0時0分から2017年12月31日23時45分までの二年分のデータ値が記入されている。
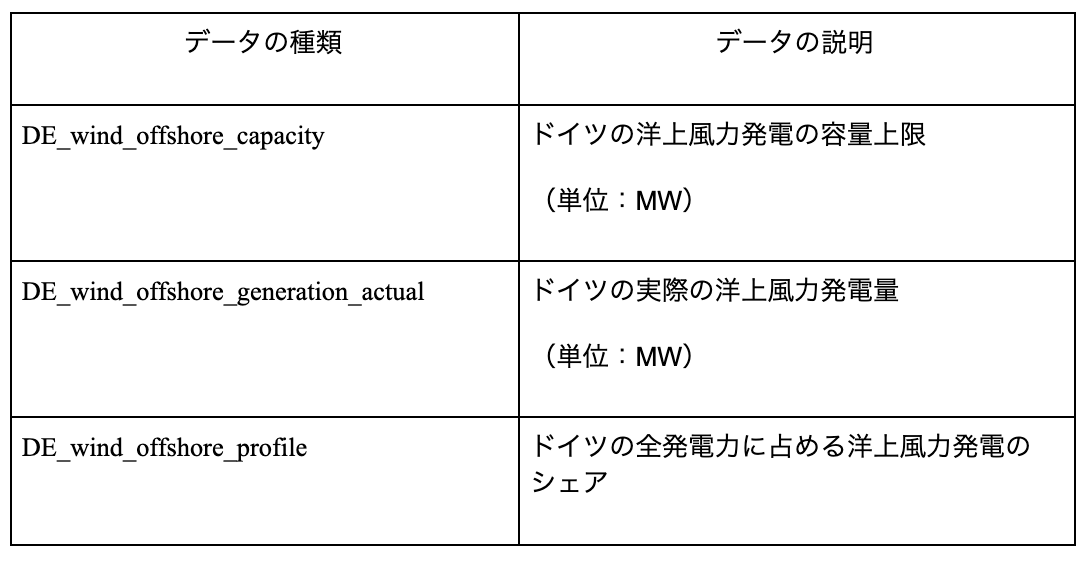
訓練データとして表1のデータを三つとも全て用い、テストデータは発電量を予測したいので、「DE wind offshore generation actual」とする。
2. 予測モデルについて
2章のデータセットは時系列データなので、時系列の分析に強いLSTMをモデルとして採用した。
LSTMとは、ディープラーニングの一種であるが、過去の情報をモデル内に保持していることが一番の特徴である。過去の情報といっても、少し前からの情報(短期記憶)や、かなり前からの情報(長期記憶)がある。LSTMはそのどちらも必要な分保持し続けるような仕組みになっている。
重みの更新の方法はディープラーニングの一種なので誤差逆伝播法となるのだが、LSTMの場合、誤差が時間を遡って逆伝播することから、「通時的誤差逆伝播法BPTT(Backpropagation Through Time)」と呼ばれる。
ところが、長い時系列に対してこれを行うと、勾配が不安定になったり、計算量が膨大になり、分析に時間がかかってしまう。そこで、連なったLSTM層の逆伝播のつながりだけを適当な長さ(「ブロック長さ」)で切断することで、この問題を解決することができる。このようなBPTTを「Truncated BPTT」と言い、この切断した一つの単位を「LSTMブロック」と呼ぶ。そして、そして全てのLSTMブロックを最初から最後までまとめたものを「Time LSTM層」と呼ぶ。
今回は過去の「DE wind offshore generation actual」(発電量)のデータ値とその他の二つの特徴量から、1時間後の「DE wind offshore generation actual」(発電量)を予測するというモデルになっている。
3. 精度の向上
予測精度を向上させるために下記を実施した。
- 「Time LSTM層」を増やす
- 「Time LSTM層」のユニット数を増やす
- 活性化関数を変える
- 「ブロック長さ」を変える
- 最適化アルゴリズムであるAdamの学習率を変える
この中で特に精度に差が出たのは、「「ブロック長さ」を変える」ことであった。ブロック長さを5、10、20、30と変えていくと、二乗平均平方根誤差RMSEは表3のようになる。この時、「Time LSTM層」は1つ、「Time LSTM層」のユニット数は20つとした。

また、図3、4はそれぞれ最も誤差の大きい、ブロック長さが5の時と、最も誤差が小さい、ブロック長さが10の時の実測値(real)(黒い破線)と予測値(predicted)(赤い実線)のグラフである。但し、発電量の値は0から1に正規化してある。図4の方が、黒い破線が赤い実線と重なり消えていて、予測が正しいということが分かる。
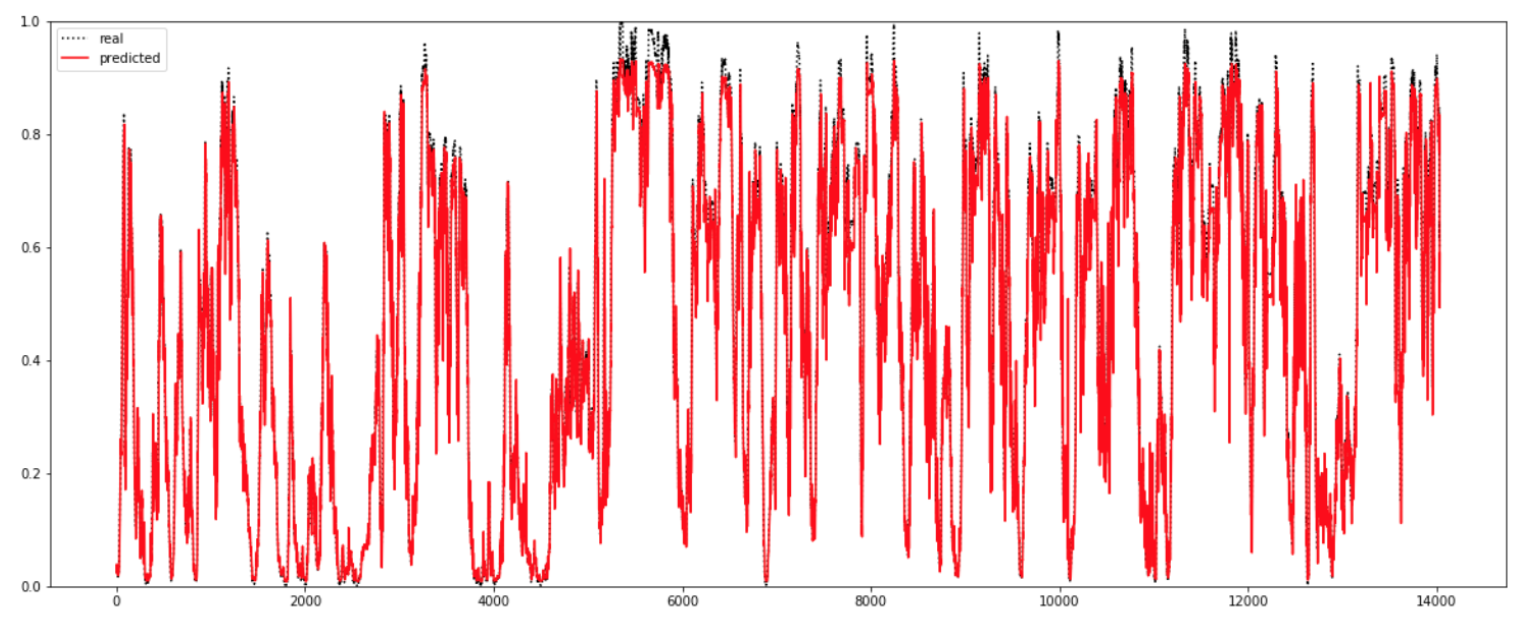
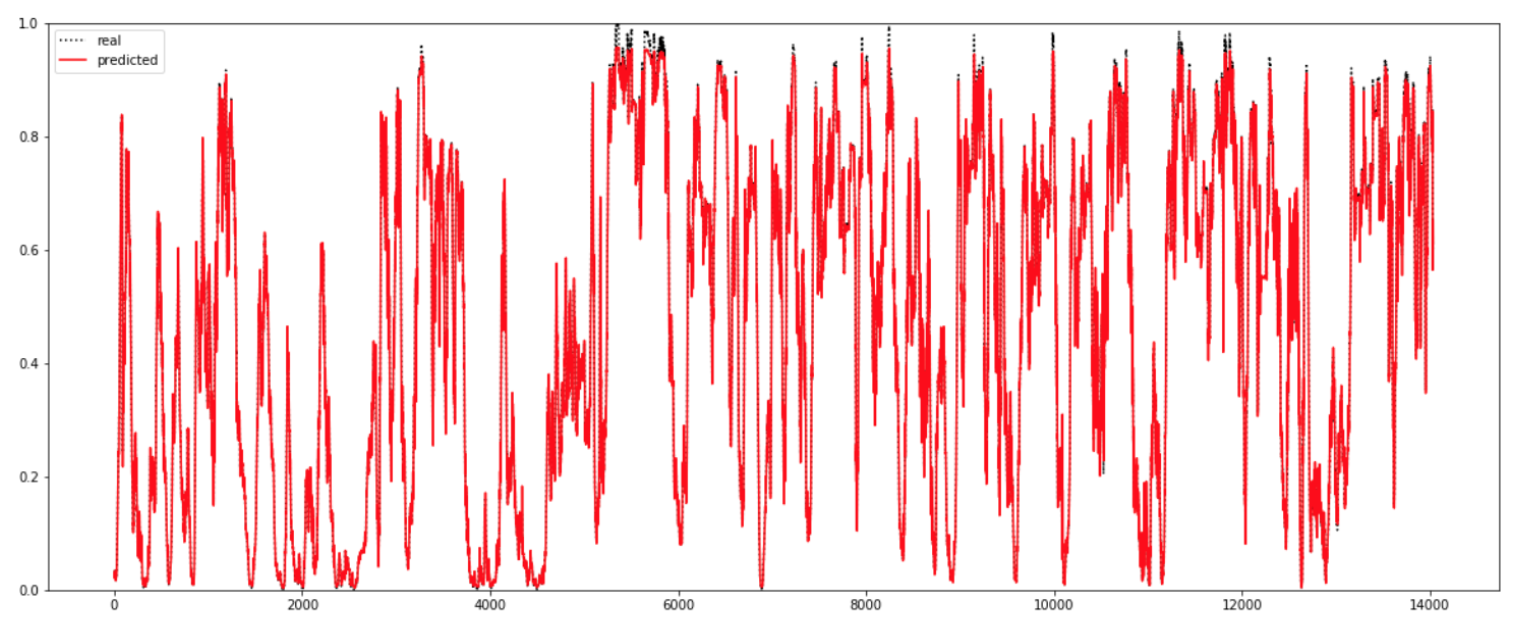
また、「最適化アルゴリズムであるAdamの学習率を変える」ことも精度を変化させた。結果的に、学習率が0.0007の時に最も精度がよくなった。(図3、4は学習率0.0007の場合)
4. 結果・考察・課題
図4はブロック長さを10、Adamの学習率を0.0007とした結果であるが、これは私が今回実装した中で最も精度の高い結果である。全体的にかなりの精度で予測できていることが分かり、時系列データに非常に強いLSTMをモデルとして採用していることが大きな要因である。
しかし、発電量が非常に多い時(発電量を0から1に正規化した時の0.95以上)の予測精度は、今後、発電量予測を実用化する場合には必ず解決しなければならない問題である。当然であるが沢山発電することができる時というのは非常に重要であるからだ。このような結果を招く理由として考えられることは、これらが挙げられる。
- 訓練データとして気象・海象データがない(特徴量が足りない)
- 何らかのパラメータのチューニングで失敗している
- 測定期間が短すぎる
私としては、パラメータのチューニングについては非常に多くのパターンを試してみたので、それによってこれ以上大きく変化するとは思えない。やはり訓練データとして気象・海象データがないことが一番の原因ではないかと考えている。自然の力を利用して発電しているのにも関わらず、自然の力に関するデータなしに、過去の発電量、容量上限、シェア率だけから発電量を予測しては精度は期待できないであろう。もし気象・海象データ(具体的には、風速、風向き、天候、波高、波向など)と発電量のデータセットを手に入れることができれば、実用化も遠くない予測モデルが完成するかもしれない。1章でも触れたが、大規模な装置を使わずに単純なモデルで模型試験を行って、そこからデータセットを得ることについても今後模索してみようと思っている。
5.参考文献
- 斎藤康毅『ゼロから作るDeep Learning ② ー自然言語処理編』株式会社オライリージャパン, 2018
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数