DEVELOPER’s BLOG
技術ブログ
じゃらんの口コミをpythonでスクレイピングしてみた

今回は「じゃらんの口コミをスクレイピングしてみた」ということで紹介していきます。
※この記事はスクレイピング初心者向けに書いています。
目次
1はじめに
2スクレイピング
3可視化
4分析・まとめ
5注意すること
6終わりに
はじめに
皆さんは今年の冬をどのように過ごす予定でしょうか?
今回は「冬」「雪」といえば「スキー」「温泉」ということで、この二つのキーワードに関連するホテル・旅館の口コミを分析しました。LINEトラベルのサイトによると、温泉が楽しめるスキー場1位は「山形蔵王温泉スキー場」のようです。
このエリアの口コミ評価今現在第一位のホテルについてスクレイピングさせていただきました。
今回は特定のホテルの口コミをスクレイピングし、どんな人が口コミを投稿し、どんな評価をつけているのかをグラフを表示しながら分析しました。
スクレイピング
今回取得する情報
・性別
・年齢
・評価
・いつ宿泊したか
・誰と旅行したか
・価格帯
この記事は初心者向けに書いていますので、コードを初めから紹介したいと思います。
ここではスクレイピングからデータフレームを作るところまでを紹介しています。
まずはじめに必要なものをインポートします。
from bs4 import BeautifulSoup import urllib import pandas as pd import requests
取得したいホテル口コミページのURLを取得します。
html = requests.get('https://www.jalan.net/yad309590/kuchikomi/')
soup = BeautifulSoup(html.content,'html.parser')
このホテルの口コミページは3ページあったので、それぞれのURLをリストに入れておきます。
url_list = ['https://www.jalan.net/yad309590/kuchikomi/?screenId=UWW3701&idx=0&smlCd=060203&dateUndecided=1&yadNo=309590&distCd=01', 'https://www.jalan.net/yad309590/kuchikomi/2.HTML?screenId=UWW3701&idx=30&smlCd=060203&dateUndecided=1&yadNo=309590&distCd=01', 'https://www.jalan.net/yad309590/kuchikomi/3.HTML?screenId=UWW3701&idx=60&smlCd=060203&dateUndecided=1&yadNo=309590&distCd=01']
ここから本題に入っていきます。
まず、口コミ投稿者の性別と年代を取得し、綺麗な形にします。
valuer = []
for row in url_list:
row = str(row)
html = urllib.request.urlopen(row)
soup = BeautifulSoup(html)
valuer.append(soup.find_all("span", class_='jlnpc-kuchikomi__cassette__user__name'))
continue
valuer_list = valuer[0]+valuer[1]+valuer[2]
new_valuer_list = []
for row in valuer_list:
row = str(row)
new_valuer_list.append(row.split('(')1.split(')')0)
このようになります。

性別・年代をそれぞれデータフレームに入れます。
data = pd.DataFrame()
sex = []
age = []
for row in new_valuer_list:
row = str(row)
sex.append(row.split(' / ')[0])
age.append(row.split(' / ')[1])
new_age = []
for row in age:
row = str(row)
new_age.append(row.replace("代","'s"))
data['sex'] = sex
data['age'] = new_age
次に、口コミ評価を取得します。
value = []
for row in url_list:
row = str(row)
html = urllib.request.urlopen(row)
soup = BeautifulSoup(html)
value.append(soup.find_all("span", class_='jlnpc-kuchikomi__cassette__rating__em'))
continue
value = value[0]+value[1]+value[2]
new_value = []
for row in value:
row = str(row)
new_value.append(row.split('')[0])
data['value'] = new_value
最後に、いつ・誰と・どのくらいの価格帯で利用したのか取得します。
what = []
for row in url_list:
row = str(row)
html = urllib.request.urlopen(row)
soup = BeautifulSoup(html)
what.append(soup.find_all("div", class_='jlnpc-kuchikomi__cassette__attribute1 styleguide-scope'))
continue
what = what0+what1+what2
new_what = []
for row in what:
row = str(row)
new_what.append(row.split('')1.split('')0)
date = []
trip = []
for row in new_what:
row = str(row)
date.append(row.split('【')1.split('宿泊')0)
trip.append(row.split('\xa0\xa0')1.split('】')0)
data['date'] = date
data['trip'] = trip
price = []
for row in what:
row = str(row)
price.append(row.split('【宿泊価格帯】')1.split('(大人1人あたり/税込)')0)
data['price'] = price
データフレームが完成しました。
可視化
ここでは先ほどスクレイピングした口コミ投稿者のデータについて可視化し、簡単に考察します。
まずはじめに、取得したデータについて簡単に見ていきましょう。
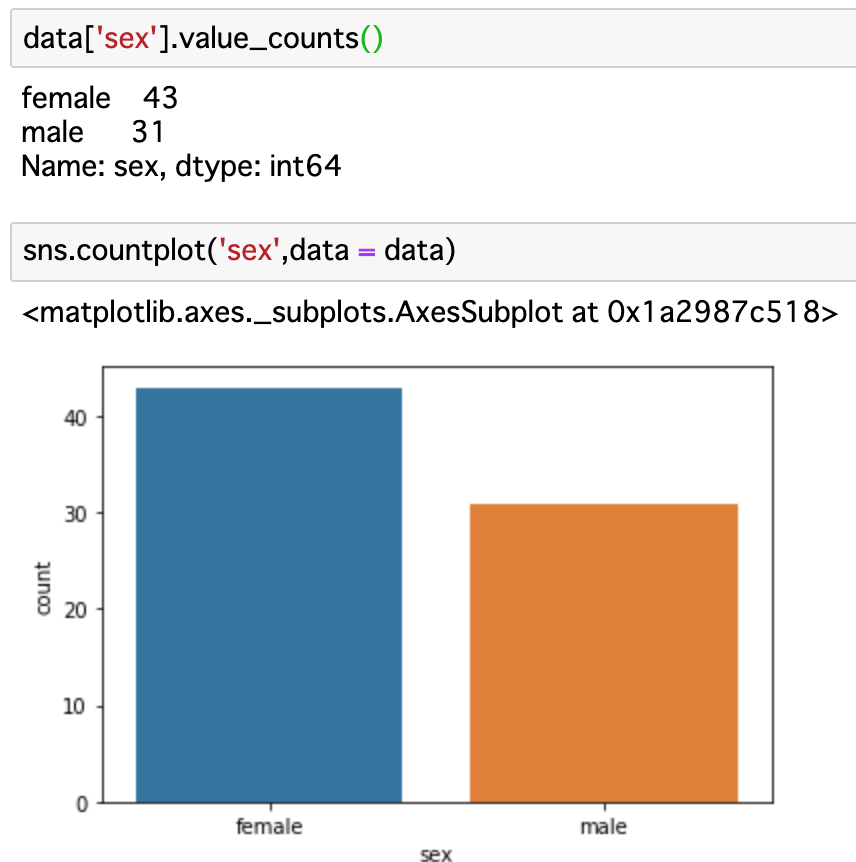
性別
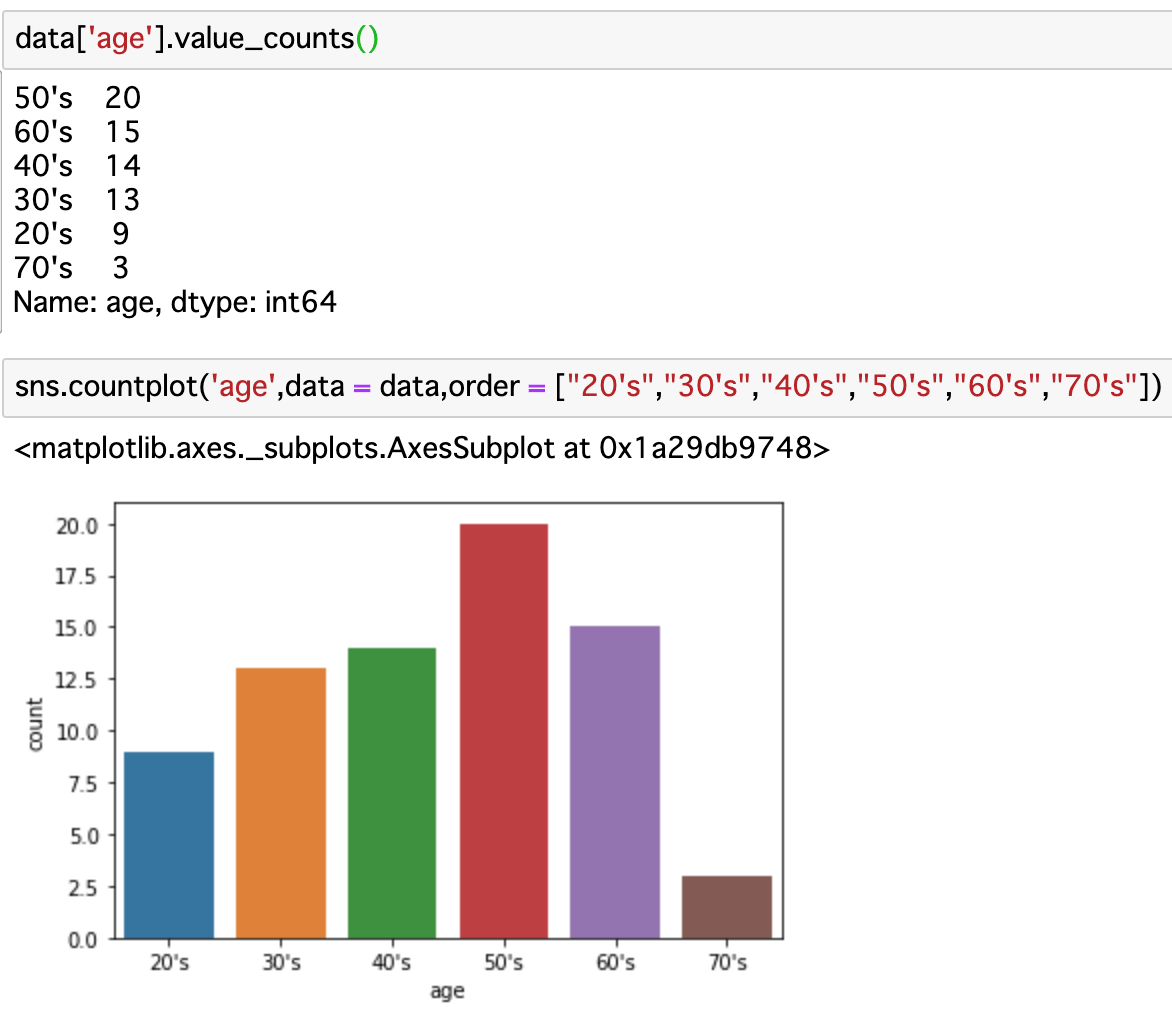
年代
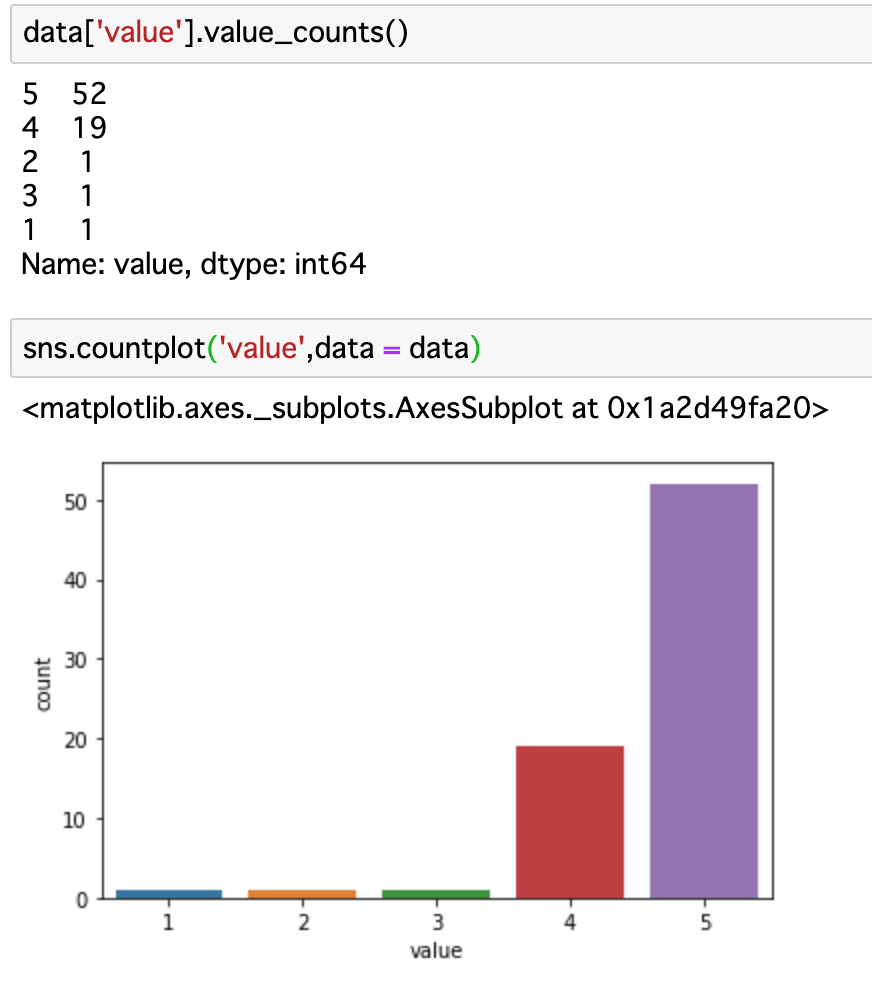
口コミ評価
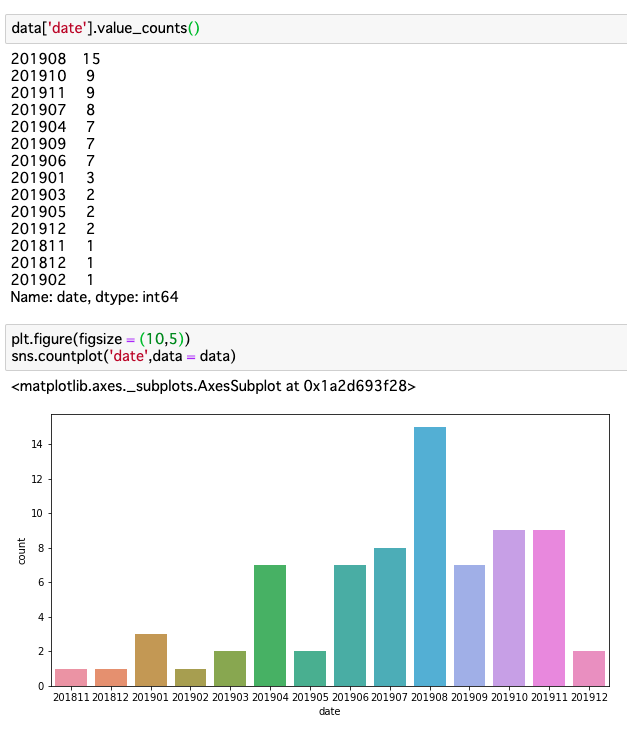
いつ利用したか
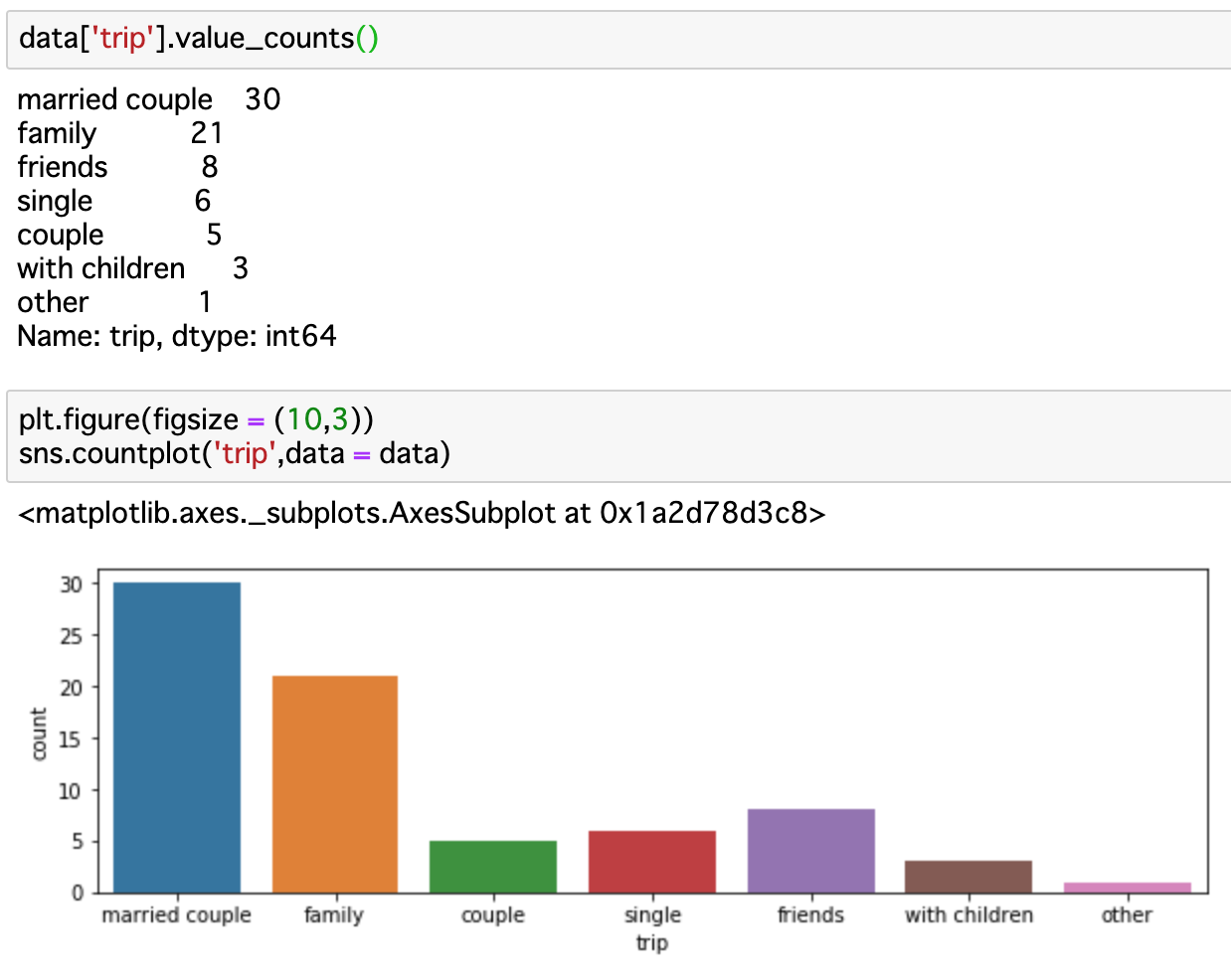
誰と利用したか
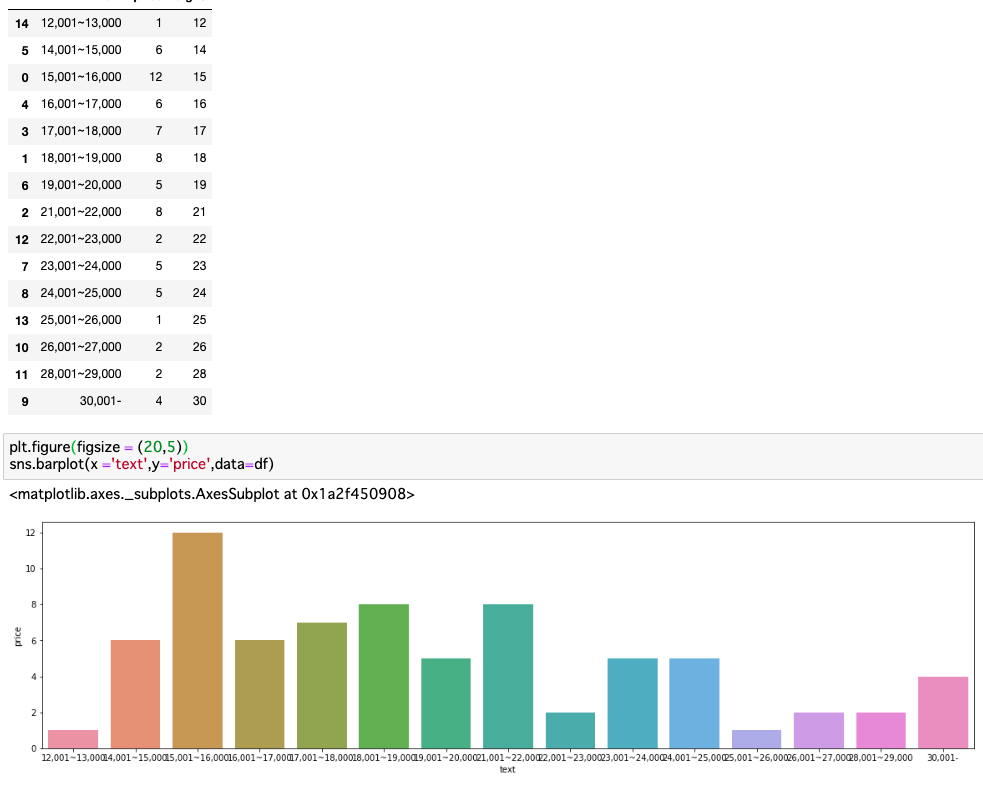
価格帯
分析・まとめ
データからわかること
・口コミ投稿者は50代が一番多く、60代、40代と続く。
若い層(20代、30代)よりも多いのは、お金に余裕があるからなのか、あるいは温泉地ということが関係しているのか。
・今回「スキー」と「温泉」というキーワードで探したが、2019年8月の投稿が多い。夏でも人気のある観光地なのかもしれない。
・大人1人あたり1万円を超え、高いものは3万円を超えるものもあることがわかる。夫婦旅行が多いことにも関係していそう。
仮説:蔵王には、お金に比較的余裕があり、子育ても終わった50代の夫婦が旅行に来ることが多いのでしょうか。8月に口コミが多かったのも、冬に体力の必要なスキーを楽しむのではなく、ゆったりと自然を感じたいという人が多いのかもしれません。もしかすると、今回、「スキー」「温泉」で蔵王が出てきたのは、スキーで有名という理由だけではなく、体力のある若い世代に冬の時期に多く来て欲しいという地域の狙いがあるのかもしれません。
今回取得した口コミの数は74件と少なく、取得したデータの種類も少ないため、事実に対して理由を断定することはできません。しかし、だからこそ上記の仮説のように想像を膨らませ、いろいろなことに思いを巡らせることができるのかもしれませんね。
注意すること
口コミを分析する際にはいくつか気をつけなければいけないことがあります。
・口コミ分析は、宿泊者全員について分析できるというわけではなく、あくまで「口コミをした人」のみに対する分析となります。もしかしたら、男性よりも女性の方が口コミをするのが好きかもしれないし、年齢層が高めの人より若い人の方が口コミを投稿するということもあり得ます(その逆も然り)。
口コミを分析している時点で情報を限定してしまっているということに気をつける必要があります。
・上と似ているのですが、口コミを投稿する人はどんな人かを考える必要があります。
口コミを通して伝えたい!という人はどんな人でしょうか?宿泊にとても満足してお礼を伝えたい、良さを伝えたいという人や、何か不満があって意見を言いたい、改善策を伝えたいという人が想定されます(不満だった人は関わりたくないから口コミを投稿しないということも考えられます)。可もなく不可もなく感じている人は、口コミ投稿するのが好きという人を除き、わざわざ口コミを投稿するでしょうか?
・口コミは利用した人の感想ですから、主観が入り、その情報が正確かを確かめることは難しいでしょう。もしかしたら嘘をついている人や誇張して書いている人、あるいはサクラがいるという可能性も0ではありません。完全ではないということを意識する必要があります。
・今回は、口コミ評価が高評価に著しく偏っているため、どんな人が高評価・低評価をするのか明らかにすることはできませんでした。「口コミ評価が高評価に著しく偏っている」のは、このホテルに限ることなのか、もしくはエリア全体、口コミ全体でそういう傾向があるのかを明らかにすると、今後の口コミ分析の役に立つかもしれません。
終わりに
今回は特定のホテルの口コミをスクレイピングし、投稿者についての分析を行いました。
次回は、今回のスクレイピングの手法を活かして、どこかの「エリア」のホテル・旅館についてスクレイピングし、そのホテル・旅館ごとの傾向や、どんな人がそのホテル・旅館に向いているかなどを考察していこうと思います。
後々、機械学習を用いて、旅行しようと思っている人に最適なホテルをオススメできる機能を作りたいと考えています。
Twitter・Facebookで定期的に情報発信しています!
Follow @acceluniverse
関連記事

目次 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 2.AWS通信コストを押し上げる"NAT ゲートウェイ経由通信"の特定方法 3.NAT ゲートウェイコストを削減するための対策 4.VPCエンドポイント化によってコストを削減した結果 1.AWS通信コストが増加する背景と、NAT ゲートウェイが高額になりやすい理由 AUCでは、SRE活動の一環として、AWSコストの適正化を行っています。 (技術ブログ『SRE

目次 実装前の課題 採用した技術と理由 実装した内容の紹介 改善したこと(抑制できたコスト) 実装前の課題 SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)とは、Googleが提唱したシステム管理とサービス運用に対するアプローチです。システムの信頼性に焦点を置き、企業が保有する全てのシステムの管理、問題解決、運用タスクの自動化を行います。 弊社では2021年2月からSRE活動を行っており、セキュリ

目次 AUCの使用ツール GitHub、CircleCI使用までの流れ AWSの構成図 まとめ AUCの使用ツール 弊社ではGitHubとCircleCIの2つのツールを利用し、DevOpsの概念を実現しております。 DevOpsとは、開発者(Development)と運用者(Operations)が強調することで、ユーザーにとってより価値の高いシステムを提供する、という概念です。 開発者は、「システムへ新しい機能を追加したい」 運用者は、「システムを

2022年卒大学生の皆さん! コロナウイルスが流行していることで就活にどういう影響があるのか、とても不安ですよね。 今回は業界ごとに採用人数を予測し、「どの業界が狙い目なのか」機械学習を使った分析手順を紹介します! 目次 概要 手順 今後の課題 1.概要 データセットの内容 分析対象の7業界・各4企業 化粧品 電子機器 商社 不動産 金融 サービス IT・情報 説明変数と目的変数 特徴量 年初の株価、決算報告書提出翌日の株価、一株あたりの純資産額、従業員数