DEVELOPER’s BLOG
技術ブログ
TensorFlowでニューラルネットワークを使った手書き数字の分類

はじめに
こんにちは、システム部の譚です。
Google Colablatoryで、手書きの数字(0, 1, 2 など)から構成されているMNISTデータセットを使い、分類問題のニューラルネットワークを構築してみました。
目次
モデルを構築する
手順
1.TensorFlowのモデルを構築し訓練するためのハイレベルのAPIである tf.kerasを使用する。
from __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow and tf.keras import tensorflow as tf from tensorflow import keras # Helper libraries import numpy as np import matplotlib.pyplot as plt print(tf.__version__)
2.訓練データとテストデータをダウンロードする。
fashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
3.後ほど画像を出力するときのために、クラス名を保存しておく。
mnist = keras.datasets.mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data()
4.label nameをつける。
class_names = ['0', '1', '2', '3', '4','5', '6', '7', '8', '9']
5.データの前処理をする。
最初の画像を調べてみればわかるように、ピクセルの値は0から255の間の数値です。
ニューラルネットワークにデータを投入する前に、これらの値を0から1までの範囲にスケールするので、画素の値を255で割ります。
train_images = train_images / 255.0 test_images = test_images / 255.0
6.訓練用データセットの最初の25枚の画像を、クラス名付きで表示する。
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

7.モデルを構築する。
model = keras.Sequential([
# データのフォーマット変換
keras.layers.Flatten(input_shape=(28, 28)),
# 128個のノードのDense層
keras.layers.Dense(128, activation=tf.nn.relu),
# 10ノードのsoftmax層
keras.layers.Dense(10, activation=tf.nn.softmax)
])
8.モデルのコンパイルをする。
model.compile( # モデルが見ているデータと、損失関数の値から、どのようにモデルを更新するかを決定 optimizer=tf.keras.optimizers.Adam(), # 訓練中にモデルがどれくらい正確かを測定します loss='sparse_categorical_crossentropy', # 訓練とテストのステップを監視するのに使用します metrics=['accuracy'])
9.モデルの訓練
モデルは、画像とラベルの対応関係を学習します model.fit(train_images, train_labels, epochs=5)
Epoch 1/5 60000/60000 [==============================] - 7s 111us/sample - loss: 0.2607 - acc: 0.9261 Epoch 2/5 60000/60000 [==============================] - 6s 105us/sample - loss: 0.1127 - acc: 0.9668 Epoch 3/5 60000/60000 [==============================] - 6s 103us/sample - loss: 0.0763 - acc: 0.9769 Epoch 4/5 60000/60000 [==============================] - 6s 103us/sample - loss: 0.0557 - acc: 0.9832 Epoch 5/5 60000/60000 [==============================] - 6s 104us/sample - loss: 0.0448 - acc: 0.9864
モデルの訓練の進行とともに、損失値と正解率が表示されます。このモデルの場合、訓練用データでは0.98(すなわち98%)の正解率に達します。
10.正解率を評価する。
テスト用データセットに対するモデルの性能を比較します。
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
10000/10000 [==============================] - 0s 41us/sample - loss: 0.0717 - acc: 0.9777 Test accuracy: 0.9777
ご覧の通り、テスト用データの正解率は訓練用より少し低い結果でした。これは過学習(over fitting)の一例です。
11.予測する。
predictions = model.predict(test_images) np.argmax(predictions[0])
今回の予測は合っていることが確認できました。
12.10チャンネル全てをグラフ化する。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
0番目の画像と、予測、予測配列を見てみましょう。
i = 0 plt.figure(figsize=(6,3)) plt.subplot(1,2,1) plot_image(i, predictions, test_labels, test_images) plt.subplot(1,2,2) plot_value_array(i, predictions, test_labels) plt.show()
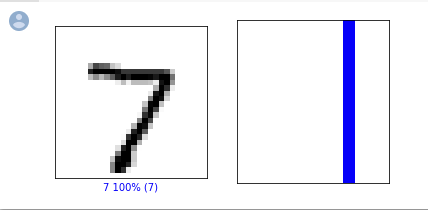 予測確率は100%なので、すべて青で表示されました。
予測確率は100%なので、すべて青で表示されました。
やはり数字に自信満々ですね。(チュートリアルのほうは、Fashion MNISTを使って若干赤かグレーも出てきました。)
13.予測の中のいくつかの画像を、予測値と共に表示する。
# X個のテスト画像、予測されたラベル、正解ラベルを表示します。
# 正しい予測は青で、間違った予測は赤で表示しています。
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()

図のように、三行目の5の予測率が82%だった以外は、100%です。(これは手書きが悪かったですね)
おわりに
今回は試すことが多かったですが、これから学ぶべきことに気づけました。
例えば...
- モデルのレイヤーとは。
- モデルをコンパイルする際に、損失関数、オプティマイザ、メトリクスなどはモデルにどのような影響するのか。
- ヘルパーライブラリnumpy、matplotlib.pyplotなどの具体的な使い方など。
実際に扱ってみることで、機械学習に対する怖さはなくなり、今後も様々なモデルで実装していきたいと思います。
参考
関連記事

ディープラーニングを使って、人の顔の画像を入力すると 年齢・性別・人種 を判別するモデルを作ります。 身近な機械学習では1つのデータ(画像)に対して1つの予測を出力するタスクが一般的ですが、今回は1つのデータ(画像)で複数の予測(年齢・性別・人種)を予測します。 実装方法 学習用データ まず、学習用に大量の顔画像が必要になりますが、ありがたいことに既に公開されているデータセットがあります。 UTKFace というもので、20万枚の顔画像が含まれています。ま

概要 自分に似合う色、引き立たせてくれる色を知る手法として「パーソナルカラー診断」が最近流行しています。 パーソナルカラーとは、個人の生まれ持った素材(髪、瞳、肌など)と雰囲気が合う色のことです。人によって似合う色はそれぞれ異なります。 パーソナルカラー診断では、個人を大きく2タイプ(イエローベース、ブルーベース)、さらに4タイプ(スプリング、サマー、オータム、ウィンター)に分別し、それぞれのタイプに合った色を知ることができます。 パーソナルカラーを知るメ
はじめに この記事では物体検出に興味がある初学者向けに、最新技術をデモンストレーションを通して体感的に知ってもらうことを目的としています。今回紹介するのはAAAI19というカンファレンスにて精度と速度を高水準で叩き出した「M2Det」です。one-stage手法の中では最強モデル候補の一つとなっており、以下の図を見ても分かるようにYOLO,SSD,Refine-Net等と比較しても同程度の速度を保ちつつ、精度が上がっていることがわかります。 ※https:

はじめに まずは下の動画をご覧ください。 スパイダーマン2の主役はトビー・マグワイアですが、この動画ではトム・クルーズがスパイダーマンを演じています。 これは実際にトム・クルーズが演じているのではなく、トム・クルーズの顔画像を用いて合成したもので、機械学習の技術を用いて実現できます。 機械学習は画像に何が写っているか判別したり、株価の予測に使われていましたが、今回ご紹介するGANではdeep learningの技術を用いて「人間を騙す自然なもの」を生成する