DEVELOPER’s BLOG
技術ブログ
Google Colablatory使ってみた ~線形回帰を添えて~

こんにちは、システム部の大瀧です。
今回は初歩ということでGoogle Colaboratoryを使ってみようと思います。
せっかくなので実際に動くものとして、scikit-learnが用意しているbostonのデータセットを使って初歩的な単回帰分析を行ってみます。
1. Google Colaboratoryとは
Colaboratoryは、完全にクラウドで実行されるJupyterノートブック環境です。設定不要で、無料でご利用になれます。
Colaboratoryを使用すると、コードの記述と実行、解析の保存や共有、強力なコンピューティングリソースへのアクセスなどをブラウザからすべて無料で行えます。
つまりGoogle Colaboratory(以下Colab, コラボと読むようです)は、端的にいうとクラウド版のjupyter notebookということです。
誰でも無料で簡単に利用することができるという敷居の低さや、GPU環境を無料で利用可能であることなどがColabのメリットです。
補足. jupyter notebookとは
「jupyter notebookが何か」を簡潔にいうとプログラムの実行環境のことなのですが、優れているのはnotebookというだけあってコードだけでなくメモやファイル、コードの実行結果などをノートのように残すことができる点です。
特にデータの処理を行ったグラフなどを残しておけるのは非常に見やすく、データを分析する助けになります。
2. 実際に動かしてみる
Colabの準備は簡単です。
Googleアカウントを用意しましょう。それだけです。
https://colab.research.google.com/にアクセスします。
以下のような画面が表示されるはずです。
次に新しいノートブックを作成します。
メニューの「ファイル」から「Python3の新しいノートブック」を選択すると真っさらなノートブックが作成されます。
画像の赤枠が「セル」と呼ばれ、コードはセル単位で実行することが可能です。
せっかくなので簡単にコードを記載してみます。
今回はscikit-learnというライブラリのBostonデータセットを使ってなんちゃって線形回帰を試してみたいと思います。
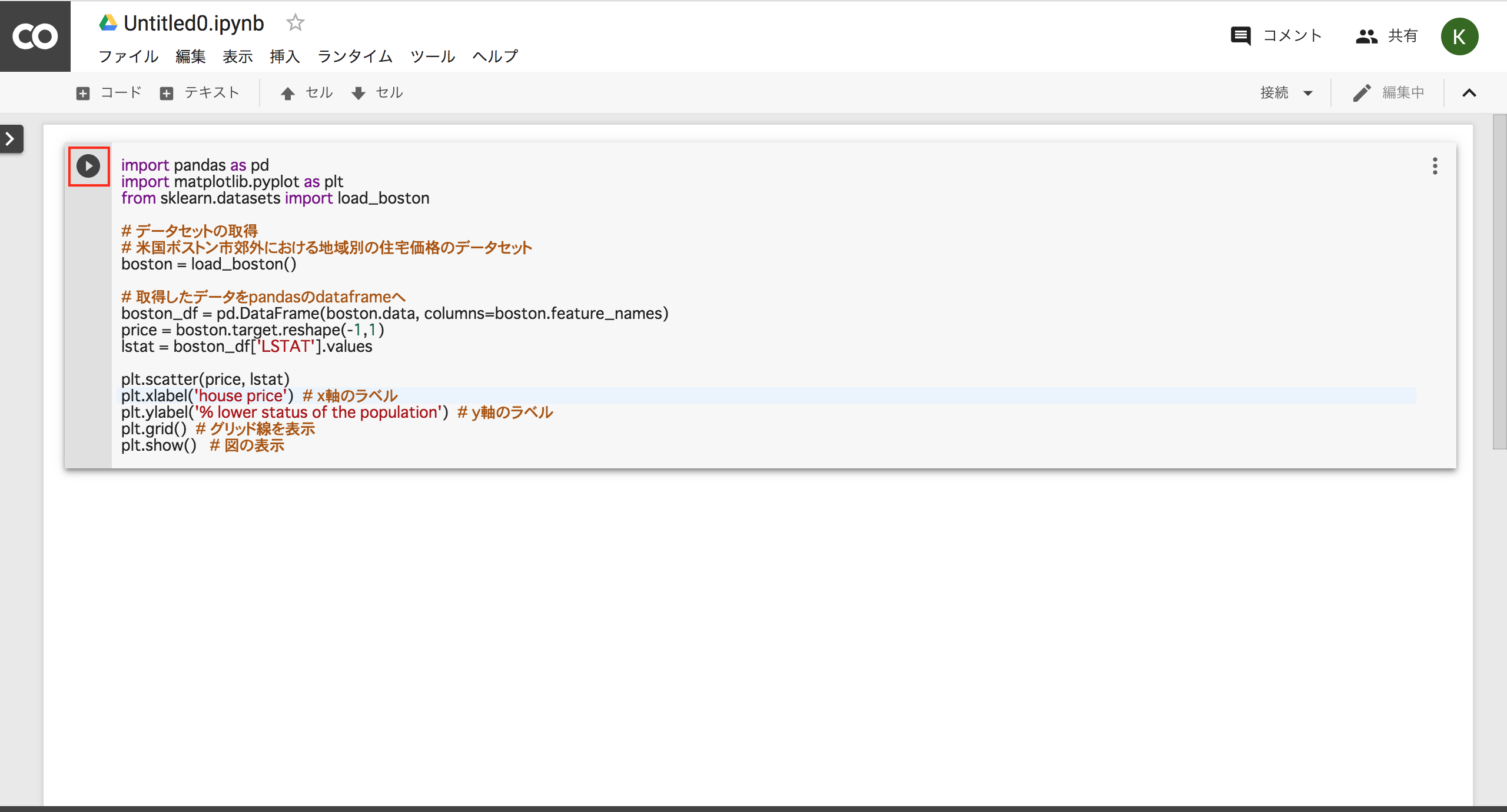
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
# データセットの取得
# 米国ボストン市郊外における地域別の住宅価格のデータセット
boston = load_boston()
# 取得したデータをpandasのdataframeへ
boston_df = pd.DataFrame(boston.data, columns=boston.feature_names)
price = boston.target.reshape(-1,1)
lstat = boston_df['LSTAT'].values
plt.scatter(price, lstat)
plt.xlabel('house price') # x軸のラベル
plt.ylabel('% lower status of the population') # y軸のラベル
plt.grid() # グリッド線を表示
plt.show() # 図の表示
実行するコードをセルに書き込んだらセルの左上にある再生ボタン?を押しましょう。これでコードが実行されます。
もし複数のセルを実行したい場合は、メニューにある「ランタイム」の項目の「すべてのセルを実行」を選択してください。他にも一部のセルのみを実行することなどが可能です。
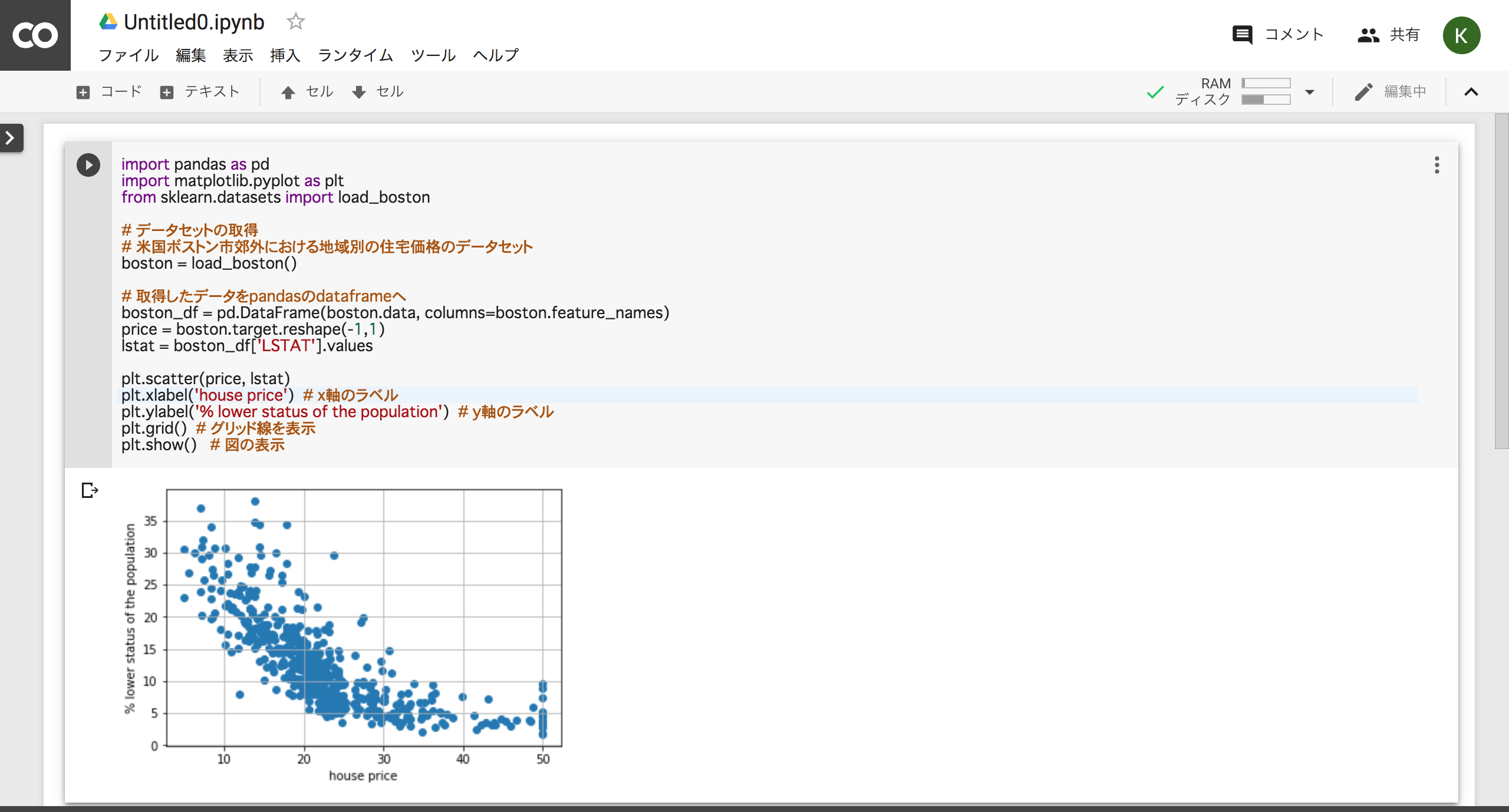
実行するとグラフが描画されます。
今回は「地域別住宅価格(X軸)」と「給与の低い職業に従事する人口の割合 (%)(Y軸)」のグラフです。プロットされたドットをみるとどうやら相関関係がありそうです。
当たり前かもしれませんが、住宅の価格が高い地域には給与の低い職業に従事する人が少ないようです。
ではこれらを線形回帰(今回は手抜き単回帰分析)します。
描画されたグラフはそのままに新たに分析結果を追加したグラフを描画します。
メニュー下の「+コード」を押します。
新たに作成されたセルに新たにコードを書き込み、今回書き込んだセルの左上にある再生ボタンをクリックすると、このセルのみが実行されます。
画像のように線形直線が描画された新たなグラフが表示されたでしょうか。
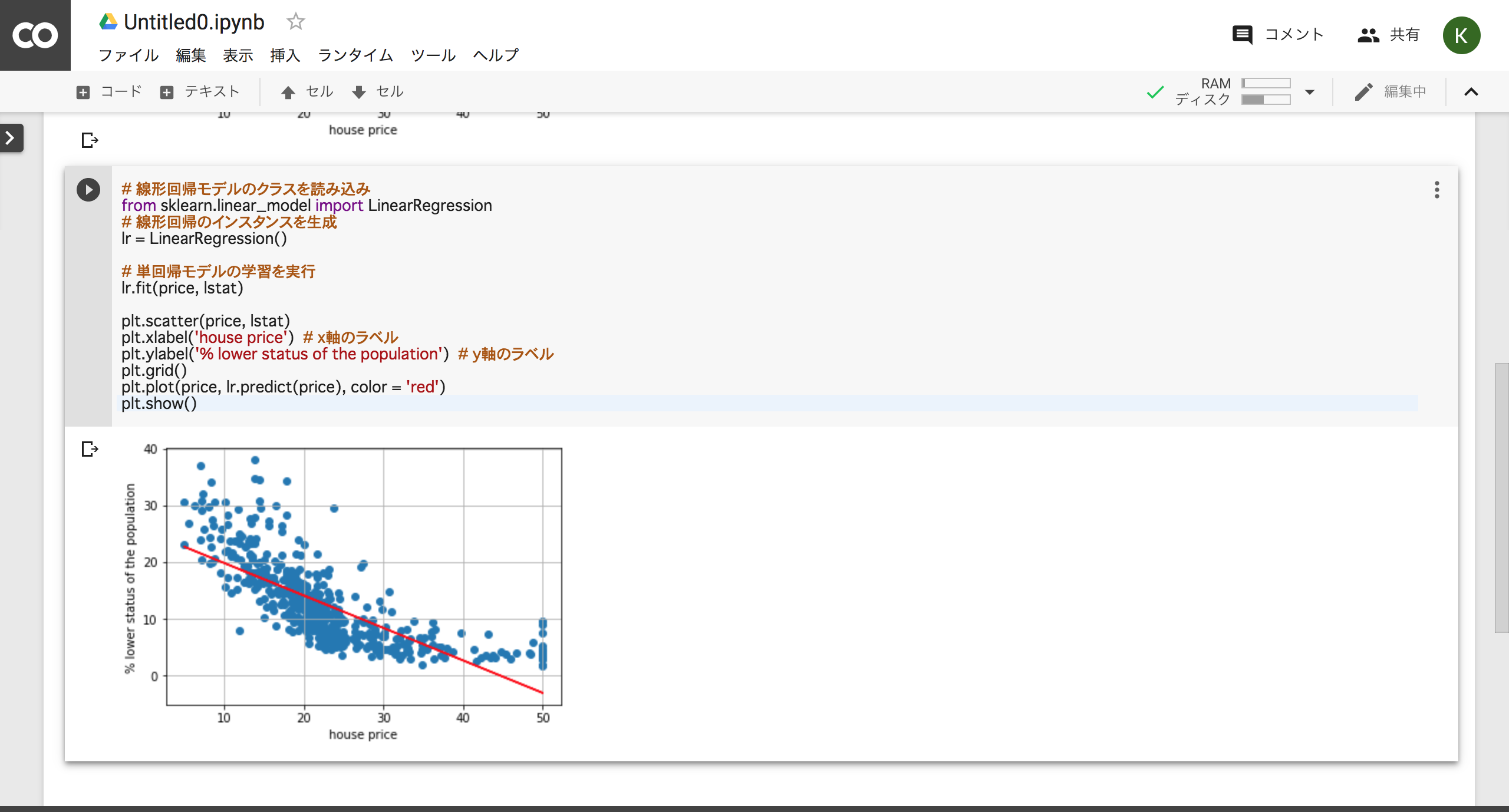
# 線形回帰モデルのクラスを読み込み
from sklearn.linear_model import LinearRegression
# 線形回帰のインスタンスを生成
lr = LinearRegression()
# 単回帰モデルの学習を実行
lr.fit(price, lstat)
plt.scatter(price, lstat)
plt.xlabel('house price') # x軸のラベル
plt.ylabel('% lower status of the population') # y軸のラベル
plt.grid()
plt.plot(price, lr.predict(price), color = 'red')
plt.show()
作成したファイルなのですが、アカウントのGoogle Drive内にColab Notebooksというフォルダができており、そこに保存されています。ここで察しがつくのですが、Google Driveに保存されているファイル(例えば集計データなど)をロードして、コードの中で使うことも容易になっており、そういう点もColabの魅了ですね。
今回のサンプルを公開しておきます[リンク]。
このように簡単に公開できることも大きな魅力ですが、これらを自身のワークスペースに複製して編集することなどもできます。
今回のサンプルはグラフの描画などを行いましたが、単純にPythonを初めて触る際にも使い勝手が良いかと思いますので是非使ってみましょう。
関連記事

線形モデル(linear model)は、実用的に広く用いられており、入力特徴量の線形関数(linear function)を用いて予測を行うものです。まず、説明に入る前に言葉の定義から紹介します。 線形回帰 データがn個あるとした時にデータの傾向をうまく表現することができるy=w_0×x_0+....+w_n×x_n というモデルを探し出すこと 正則化 過学習を防いで汎化性を高めるための技術で、モデルに正則化項というものを加え、モデルの形が複雑になりす

はじめに 昨日まで開催されていたKaggleの2019 Data Science Bowlに参加しました。結果から言いますと、public scoreでは銅メダル圏内に位置していたにも関わらず、大きなshake downを起こし3947チーム中1193位でのフィニッシュとなりました。今回メダルを獲得できればCompetition Expertになれたので悔しい結果となりましたが、このshake downの経験を通して学ぶことは多くあったので反省点も踏まえて

〜普及に向けた課題と解決策〜に続き 私が前回作成した記事である「海洋エネルギー × 機械学習 〜普及に向けた課題と解決策〜」では、海洋エネルギー発電の長所と課題とその解決策について触れた。今回はそこで取り上げた、 課題①「電力需要量とのバランスが取りにくい」、課題③「無駄な待機運転の時間がある」への解決策 ~発電量・電力需要量予測~ ~機械学習を用いた制御~ を実装してみる。 繰り返しにはなるが、この「発電量・電力需要量予測」と「機械学習を用いた制御」

回帰分析とは 先ず回帰分析とは、あるp個の変数が与えられた時、それと相関関係のあるyの値を説明、予測することである。ここで変数xを 説明変数 、変数yを 目的変数と呼ぶ。p=1、つまり説明変数が1つの時を単回帰、またp>=2、つまり説明変数が2つ以上の時を重回帰と呼ぶ。 単回帰分析 今回はp=1と置いた 単回帰分析 について説明する。 このとき、回帰式は y=ax+b(a,bは 回帰係数 と呼ばれる)となり直線の形でyの値を近似(予測)できる。 単回帰分析