DEVELOPER’s BLOG
技術ブログ
Microsoft Azure Machine Learning でパラメーターチューニング

今回は特定のモデルではなく、パラメーターチューニングというテクニックについて解説したいと思います。
パラメーターチューニングとは、特定のモデルにおけるパラメーター(例:Decision Forest Model における決定木の数)を調節することで、モデルの精度を上げていく作業です。実際にモデルを実装する際は、与えたれたデフォルト値ではなく、そのデータで一番精度が出るようなパラメーターを設定していくことが重要になります。その際、一回づつ手動で調節するのではなく、チューニングモジュールを使うことで最適なパラメーターが比較的楽に特定できます。
具体例
具体的な例を見ていきましょう。
今回は他の場所でも触れたFast Forest Quantile Regressionを使います。
通常、Microsoft Azure ML で初めに使う場合、デフォルトのパラメーターが設定してあります。
下の図からわかるように、このモデルのデフォルトは決定木が100, それぞれの木における葉が20, 回帰をする分位が四分位であることがわかります。
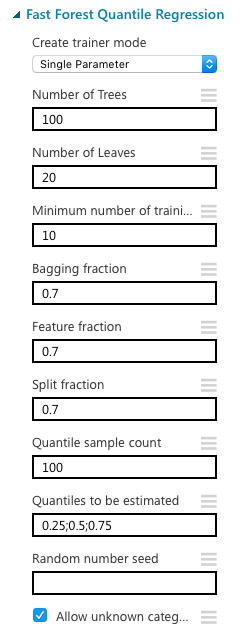
ここで、一番上の"Create Trainer Mode" を"Single Parameter"から"Parameter Range"に変えると、以下のように切り替わります。

ここでは、パラメーターを調節するにあたって、決定木の数を16から64、葉の数を16から64と調節していきますよ、ということがわかります。ここに好きな値を自分で追加することも可能です。
次に、"Tune Model Parameters"のモジュールを使って、実際にチューニングを行なっていきます。このモジュールも、以下の何種類かの設定からチューニング方法を選択することができます。
・Entire Grid - パラメーターの全ての組み合わせを順番に試していく。網羅的にチューニングができるが、その分時間がかかる。
・Random Grid - ランダムに候補を決め、その中で網羅的に行う。計算量を減らせるが、効果はEntire Gridとほぼ同等であることが証明されている。
・Random Sweep - ランダムにパラメーターを使用していく。計算量を減らせるが、必ずしも最適なパラメーターの組み合わせを探せるとは限らない。
理想的にはRandom Gridを使うのですが、時間節約のため今はRandom Sweepを使い、組み合わせを10種類試すように設定します。それでも、実質的にモデルを10回学習させ直しているのと一緒なので、非常に時間がかかります。僕の場合1時間弱かかりました。
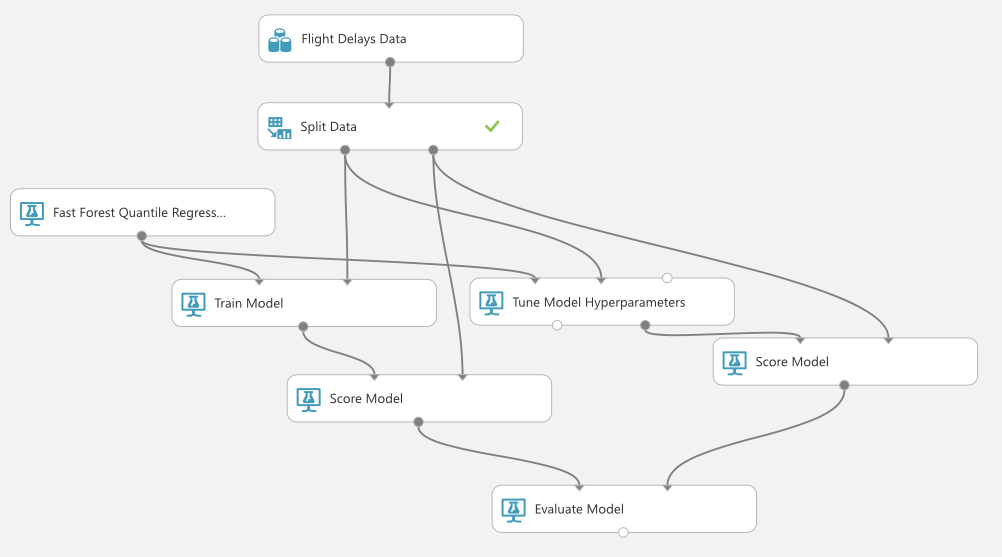
では、パラメーターチューニングを行なったモデルとデフォルト値のモデルを比べていきましょう。下の図のようにモジュールを繋ぎます。左側のデフォルト値を使ったモデルと、右側のチューニングを行なったモデルを、最後に比較しています。
結果を見てみましょう。
上の列がデフォルト値のモデルで、下の列がチューニングされたモデルになります。比べてみると、チューニングされたモデルの方が誤差が約1/2になっていることがわかります。一度チューニングすると、その後同じデータに同じモデルを使うときに、より良いパラメーターを用いることができます。

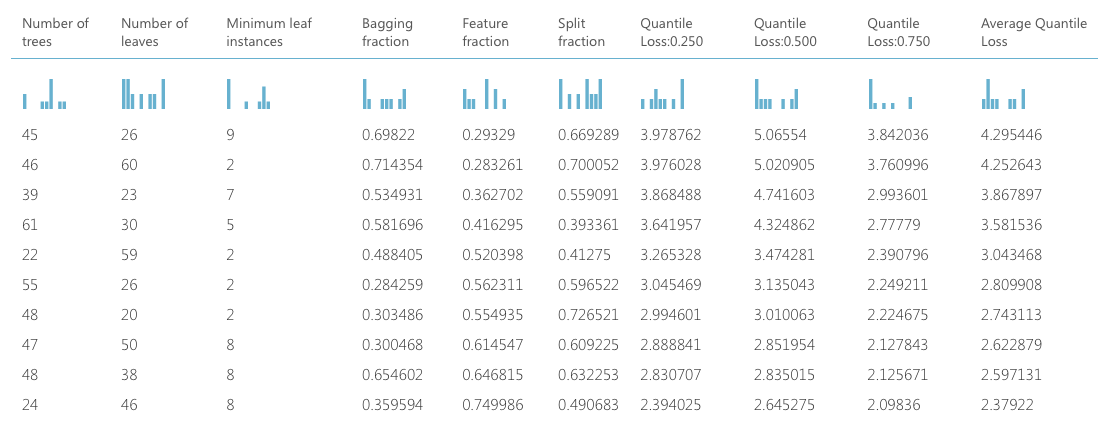
実際にどのパラメーターが一番精度が高いのでしょうか。今回は10種類試すように設定したので、結果が10列分表示されるはずです。
一番右側の誤差を比べてみると、決定機の数=24, 葉の数=46などが一番誤差が小さいことがわかります。このパラメーターが上の図の比較で使われています。今回はRandom Gridを使ったので、この組み合わせが最適なパラメーターとは限りませんが、デフォルト値より誤差が半分になったといことで、大幅な改善と言えるでしょう。
以上、パラメーターチューニングについてでした。時間がかかる作業ではありますが、精度を高めるためには是非活用したいテクニックです。
その他のMicrosoft Azure Machine Learning Studioでやってみた記事も参考にしてください!
決定木アルゴリズムCARTを用いた性能評価
ロジスティクス回帰を用いた Iris Two Class Dataの分類
分位点回帰を用いた飛行機遅延予測
ランダムフォレスト回帰を用いた人気ブログタイトル予測
関連記事

ここでは今は去りしデータマイニングブームで頻繁に活用されていた決定木について説明する。理論的な側面もするが、概念は理解しやすい部類であるので参考にしていただければと思う。 1 決定木(Decision Tree) 決定木とは木構造を用いて分類や回帰を行う機械学習の手法の一つで段階的にある事項のデータを分析、分離することで、目標値に関する推定結果を返すという方式である。データが木構造のように分岐している出力結果の様子から「決定木」との由来である。用途としては

はじめに 今回はロジスティック回帰についてやっていこうと思います。まずはロジスティック回帰の概要を説明して、最後には実際にAzureでiris(アヤメ)のデータでロジスティック回帰を使っていこうと思います。 勾配降下法 ロジスティック回帰でパラメータの値を決めるときに勾配降下法を用いるので、簡単に説明をしておきます。 勾配降下法は、ある関数J(w)が最小となるwを求める際に、あるwでの傾き(勾配)を求めて、降下の方向(傾きが小さくなる方)にwを更新し

分位点回帰は、普通の直線回帰とは少し変わった、特殊な回帰ですが、正規分布に従わないデータを処理する際、柔軟な予測をすることができる便利なモデルです。今回は、理論編・実践編に分けて、分位点回帰を解説していきたいと思います。 理論編 1.回帰 回帰とはデータ処理の方法の一つで、簡単に言うとデータを予測するモデルを作る際に、「モデル化=簡略化」に伴う損失を最小限にすることです。そしてこの「損失」を定量化するためにモデルごとに様々な「損失関数」を定義します。「損失

様々な場面で使われるランダムフォレストですが、大きく分けると「ランダム」の部分と「フォレスト=森」の部分の2つに分けることができます。そこで今回は理論編でそれぞれの部分がどういう仕組みになっているのか、解説していきたいと思います。後半では、実践編と題して、実際のデータセットとMicrosoft Azureを用いてRandom Forest Regressionを一般的なLinear Regression (直線回帰) と比べてみたいと思います。 理論編 0